Các câu hỏi phỏng vấn Ruby on Rails Developer - Phần 1
Bài đăng này đã không được cập nhật trong 6 năm
Lời mở đầu
Chào các bạn! Hôm nay, mình xin được chia sẽ một số câu hỏi khi tham gia phỏng vấn kỹ thuật của 1 Ruby Dev mà mình đã gặp.Bài viết này giúp mình tự kiểm tra lại kiến thức cơ sở và hi vọng những bạn sắp phỏng vấn có thể tham khảo để tự tin hơn. Những câu trả lời trong bài viết là do mình đã tìm hiểu trong thời gian chuẩn bị phỏng vấn join Div, các bạn nên google thêm để có câu trả lời chính xác và tốt nhất khi tham gia phỏng vấn.
Bắt đầu thôi!
Một bài phỏng vấn Ruby on Rails, mình thấy các câu hỏi có thể chia vào các mảng kiến thức dưới đây:
- Kiến thức OOP, giải thuật
- Kiến thức về cơ sở dữ liệu và SQL
- Hiểu biết về Ruby
- Hiểu biết về Rails
- Các hiểu biết liên quan như REST, Javascript
1. Kiến thức OOP, giải thuật
Cấu trúc dữ liệu
- Stack, Queue
- Link-list, Hash
- Graph, Cây nhị phân, …
Các thuật toán sắp xếp (Sort)
- selection sort tìm phần tử nhỏ nhất cho lên đầu, tìm nhỏ nhất trong phần còn lại đến hết
- bubble sort (đổi chỗ 2 phần tử -> đơn giản nhất)
- insertion sort so sánh 2 cặp số gần nhau, a < b cho a lên trước. Tiếp đến so sánh b và c,...
- merge sort chia để trị, chia mảng thành nhỏ nhất (1 phần tử) -> tổ hợp các phần tử lại bằng cách so sánh chúng -> gộp thành mảng đã sắp xếp
- quick sort chọn phần tử chốt -> chia thành 2 phần lớn hơn và nhỏ hơn phần tử chốt bảng cách so sánh -> sắp xếp đệ quy 2 phần đó -> kết quả
Độ phức tạp của các thuật toán sắp xếp (Sort)
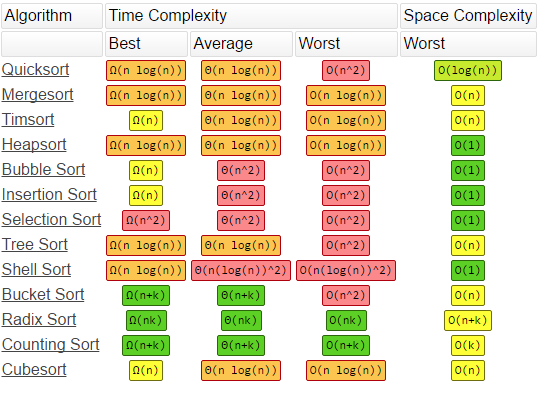
Các thuật toán tìm kiếm (Search)
Không theo kinh nghiệm
- Tìm kiếm tuyến tính (duyệt từ đầu đến cuối)
- Tìm kiếm nhị phân
- DFS Tìm kiếm theo chiều sâu
- BFS Tìm kiếm theo chiều rộng
Dựa theo kinh nghiệm
- Tìm kiếm tốt nhất - đầu tiên (best-first search) = BFS + hàm kinh nghiệm
- Tìm kiếm leo đồi (hill-climbing search) = DFS + hàm kinh nghiệm
- Tìm kiếm A*
Lập trình hướng đối tượng là gì ? Nêu 4 tính chất của hướng đối tượng, cho ví dụ?
Hướng đối tượng là một phương pháp lập trình mà mọi hoạt động đều thể hiện trên các Object.
Tính đóng gói
Tức là trạng thái của đối tượng được bảo vệ không cho các truy cập từ code bên ngoài như thay đổi trong thái hay nhìn trực tiếp. Việc cho phép môi trường bên ngoài tác động lên các dữ liệu nội tại của một đối tượng theo cách nào là hoàn toàn tùy thuộc vào người viết mã.
Đây là tính chất đảm bảo sự toàn vẹn, bảo mật của đối tượng Trong Java, tính đóng gói được thể hiện thông qua phạm vi truy cập (access modifier)
3 từ khóa private, protected, public
Tính trừu tượng
Tính trừu tượng là một tiến trình ẩn các chi tiết trình triển khai và chỉ hiển thị tính năng tới người dùng.
Tính trừu tượng cho phép bạn loại bỏ tính chất phức tạp của đối tượng bằng cách chỉ đưa ra các thuộc tính và phương thức cần thiết của đối tượng trong lập trình.
Tính trừu tượng giúp bạn tập trung vào những cốt lõi cần thiết của đối tượng thay vì quan tâm đến cách nó thực hiện.
Trong Java, chúng là sử dụng abstract class và abstract interface để có tính trừu tượng.
Tính kế thừa
Đối tượng này có các thuộc tính chung với đối tượng khác -> A kế thừa B A có các thuộc tính và các phương thức public và protected của B và của riêng A
Tính đa hình
Đối tượng thuộc các lớp khác nhau có thể hiểu cùng một thông điệp theo các cách khác nhau.
Ví dụ: Trong Shape có nhiều hình vẽ khác nhau như Circle, ... Tính diện tích chúng khác nhau, chạy chung phương thức calArea(). Ở mỗi class con viết đè phương thức calArea() theo cách khác nhau.
Chuyển kiểu lên và chuyển kiểu xuống (downcasting và upcasting)
3 cơ chế của OOP. Phân biệt, ví dụ
- Public: Thể hiện và con nó có thể truy cập
- Protected: Chỉ thằng con nó có thể truy cập
- Private: Không cho ai truy cập Tất nhiên là chỉ tính kế thừa và ngoài class, con trong class thì truy cập tất rồi :v
Hàm dựng, hàm hủy nó hoạt động như thế nào?
Hàm khởi tạo
Hàm khởi tạo cũng là một hàm bình thường nhưng có điểm đặc biệt là nó luôn luôn được gọi tới khi ta khởi tạo một đối tượng. Hàm khởi tạo có thẻ có tham số hoặc không có tham số, có thể có giá trị trả về hoặc không. Ở một hàm bình thường khác bạn cũng có thể gọi lại hàm khởi tạo được và hàm khởi tạo cũng có thể gọi một hàm bình thường khác.
Hàm hủy
Hàm hủy là hàm tự động gọi sau khi đối tượng bị hủy, nó thường được sử dụng để giải phóng bộ nhớ chương trình. Trong đối tượng hàm hủy có thể có hoặc không.
Phân biệt class và object
Class là một khuôn mẫu để tạo ra object Object là 1 thể hiện được đặt tên của class
Interface và Abstract class khác nhau như thế nào?
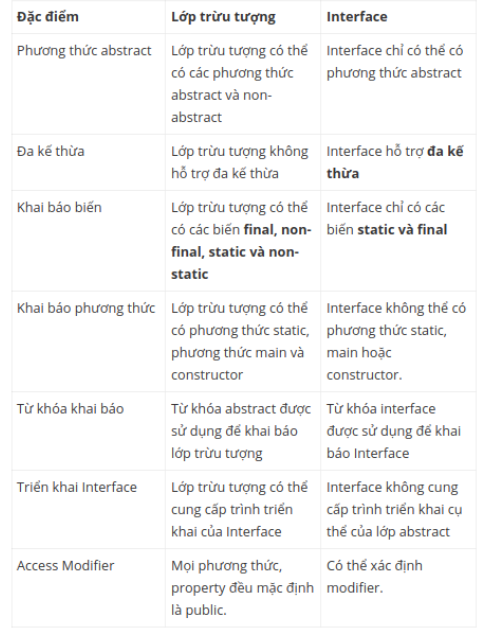
2. Kiến thức về cơ sở dữ liệu và SQL
Viết một số câu SQL theo yêu cầu
Cách xây dựng cơ sở dữ liệu cho bài toán cụ thể
Phân biệt các loại join
- INNER JOIN – trả về hàng khi có một sự phù hợp trong tất cả các bảng được join.
- LEFT JOIN trả về tất cả bản ghi bảng bên trái, ngay cả khi không có sự phù hợp trong bảng bên phải, còn những bản ghi nào của bảng bên phải phù hợp với bảng trái thì dữ liệu bản ghi đó được dùng để kết hợp với bản ghi bảng trái, nếu không có dữ liệu sẽ NULL.
- RIGHT JOIN – trả về tất cả các hàng từ bảng bên phải, ngay cả khi không có sự phù hợp nào ở bảng bên trái.
- FULL JOIN – trả về hàng khi có một sự phù hợp trong một trong các bảng.
- SELF JOIN – được sử dụng để tham gia một bảng với chính nó như thể bảng đó là hai bảng, tạm thời đổi tên ít nhất một bảng trong câu lệnh SQL.
Nếu muốn đọc để hiểu rõ hơn, các bạn có thể qua đọc series các bài viết về join sql:
https://www.w3schools.com/sql/sql_join.asp
https://hainh2k3.com/phan-biet-va-cach-su-dung-cac-loai-join-trong-mssql-server/
Phân biệt delete và truncate
| TRUNCATE | DELETE |
|---|---|
| Xóa dữ liệu nhưng không xóa cấu trúc | Xóa dữ liệu nhưng không xóa cấu trúc |
| Xóa tất cả dòng dữ liệu trong bảng | Xóa các dòng dữ liệu trong bảng |
| Không sử dụng được WHERE | Sử dụng được WHERE |
| KHÔNG ghi lại các dòng xóa trong transaction log | CÓ ghi lại các dòng xóa trong transaction log |
Phân biệt WHERE và HAVING
Where : Là câu lệnh điều kiện trả kết quả đối chiếu với từng dòng .
Having : Là câu lệnh điều kiện trả kết quả đối chiếu cho nhóm (Sum,AVG,COUNT,…)
Vì vậy mà sau GROUP BY thì sẽ chỉ dùng được Having, còn Where thì KHÔNG dùng được sau GROUP BY
Phân biệt UNION và UNION ALL
UNION và UNION ALL đều dùng để hợp hai tập bản ghi cùng cấu trúc, nhưng giữa hai mệnh đề có một khác biệt khá tinh tế:
UNION loại bỏ các bản ghi trùng lặp trước khi trả lại kết quả
UNION ALL giữ lại tất cả các bản ghi từ hai tập ban đầu.
Điều quan trọng cần lưu ý là hiệu suất của UNION ALL thường sẽ tốt hơn UNION, vì UNION yêu cầu máy chủ thực hiện công việc bổ sung để loại bỏ các bản ghi bị trùng.
Các loại index trong sql
Index là một cấu trúc dữ liệu đặc biệt dưới dạng bảng tra cứu mà Database Search Engine có thể sử dụng để giúp việc truy vấn dữ liệu trong database được thực hiện hiệu quả hơn.
Hiểu đơn giản, một chỉ mục là một con trỏ tới dữ liệu trong một bảng, giống như mục lục trong một cuốn sách để tra cứu đến các trang sách
Có bao nhiêu loại index trong MySQL?
Có hai loại index chính trong MySQL, đó là Clustered Index và Non-clustered Index
Mở rộng từ 2 loại trên
Unique Index
Primary Index
Secondary Index
Nếu muốn đọc để hiểu rõ hơn, các bạn có thể đọc các bài viết sau:
http://dinhhoanglong91.github.io/post/2017/03/02/mysql-indexing.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
Các đánh index trong sql
MySQL cung cấp các kiểu đánh index đó là: B-Tree, Hash, R-Tree và bitmap index
B-Tree index
- Dữ liệu index được tổ chức và lưu trữ theo dạng cây, tức là có gốc, nhánh và lá. Giá trị của các node được tổ chức tăng dần từ trái qua phải.
- Khi truy vấn dữ liệu thì việc tìm kiếm trong B-Tree là một quá trình đệ quy, bắt đầu từ root node và tìm kiếm tới nhánh và lá, đến khi tìm được tất cả dữ liệu thỏa mãn với điều kiện truy vấn thì mới dùng lại.
- B-Tree index được sử dụng trong các biểu thức so sánh dạng: =, >, >=, <, <=, BETWEEN và LIKE. B-Tree index thường được sử dụng cho những column trong bảng khi muốn tìm kiếm giá trị nằm trong một khoảng nào đó.
Hash index
- Dữ liệu index được tổ chức theo dạng key - value được liên kết với nhau.
- Khi hash index làm việc nó sẽ tự động tạo ra một giá trị hash của cột rồi xây dựng B-Tree theo giá trị hash đó. Giá trị này có thể trùng nhau, và khi đó node của B-Tree sẽ lưu trữ một danh sách liên kết các con trỏ trỏ đến dòng của bảng.
- Hash index chỉ sử dụng trong các biểu thức toán tử là = và <>, không có phép tìm kiếm gần đúng, tìm kiếm trong một khoảng giá trị hay sắp xếp, không thể tối ưu hóa toán tử ORDER BY bằng việc sử dụng Hash index bởi vì nó không thể tìm kiếm được phần từ tiếp theo trong Order.
R-Tree index
MyISAM hỗ trợ các chỉ mục không gian, mà bạn có thể sử dụng với các loại một phần như GEOMETRY. Không giống như các chỉ mục B-Tree, các chỉ mục không gian không yêu cầu các mệnh đề WHERE của bạn hoạt động trên tiền tố ngoài cùng bên trái của chỉ mục.
Lợi, hại của việc đánh index
Mặc dù việc sử dụng các chỉ mục nhằm mục đích để nâng cao hiệu suất của Database nhưng đôi khi bạn nên tránh dùng chúng. Một nguyên tắc chung là tạo index cho tất cả mọi thứ được tham chiếu trong các phần WHERE, HAVING và ORDER BY của các truy vấn SQL.
- Index cho việc tìm kiếm giá trị duy nhất
- Index cho khóa ngoài để tối ưu hóa việc tìm kiếm
- Index cho giá trị được sắp xếp xảy ra thường xuyên
Cần xem xét các điểm sau để quyết định có nên sử dụng chỉ mục hay không:
- Các chỉ mục không nên được sử dụng trong các bảng nhỏ.
- Bảng mà thường xuyên có các hoạt động update, insert.
- Các chỉ mục không nên được sử dụng trên các cột mà chứa một số lượng lớn giá trị NULL.
- Không nên dùng chỉ mục trên các cột mà thường xuyên bị sửa đổi.
All rights reserved
