Các Bước Chi Tiết Để Triển Khai Big Data Testing
Bài đăng này đã không được cập nhật trong 7 năm
Trong hai bài trước, chúng ta đã có cái nhìn sơ bộ về Big data, qua đó có thể trả lời một số câu hỏi đơn giản như Big Data là gì? Các bước cơ bản khi test Big Data? Ngoài ra ở bài 2, cũng đã giới thiệu sơ bộ về công cụ Yahoo! Cloud Serving Benchmark (YCSB) nhằm đánh giá hiệu năng của một database Bigdata. Vậy các câu hỏi tiếp theo sẽ là : các bước chi tiết để thực hiện test một dự án Big Data thực tế là gì? Công cụ hỗ trợ test?
Hiện nay có 2 nền tảng lưu trữ big Data phổ biến nhất là Hadoop HDFS (của Apache phát triển) và S4 (của Amazon phát triển). Trong đó, Hadoop đang được sử dụng rộng rãi hơn và có nhiều công ty phát triển với cộng đồng rất lớn như : Cloudera, Hortonworks and MapR. Do đó, trong bài này ta sẽ tập trung vào việc testing với dữ liệu trên nền tảng Hadoop.
I. Các bước chi tiết để kiểm thử ứng dụng Big Data:
Để đưa ra được chiến lược và chi tiết các bước thực hiện Big Data Testing, ta cần hiểu rõ luồng nghiệp vụ của dữ liệu trong một ứng dụng Big Data, từ đó có thể đưa ra được các checkpoint test. Mô hình dữ liệu một ứng dụng Big Data chuẩn như sau :
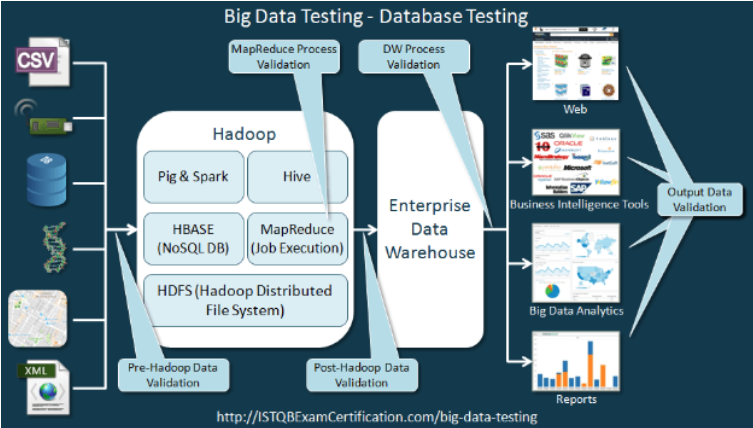
Luồng nghiệp vụ của ứng dụng Big data có thể giải thích chi tiết như sau, trong đó các phần bôi đậm chính là các bước mà Tester cần thực hiện khi test ứng dụng Big Data :
- Nguồn dữ liệu :
Dữ liệu có thể được thu thập từ nhiều nguồn khác nhau như cảm biến, các thiết bị IOT, bản scan, file CSV, logs, RDBMS… Nói chung dữ liệu đầu vào của một ứng dụng Big Data là rất đa dạng và có thể chia làm 3 loại chính như sau : NaNundefinedDữ liệu có cấu trúc (Structured Data) : RDBMS, ERP, CRM… NaNundefinedDữ liệu bán cấu trúc (Semi-Structured Data) : CSV, XML, JSON… NaNundefinedDữ liệu phi cấu trúc (Unstructured Data) : Video, Audio, Image, Sensor Data…
-
Ứng dụng Big Data sẽ làm việc với các tập data (Data Set), thực hiện xử lý các dữ liệu này (bóc tách, chuẩn hóa…), các tập data này phải được kiểm thử để đảm bảo tính chính xác dữ liệu.
-
Dữ liệu sau khi qua bước tiền xử lý sẽ được đưa vào lưu trữ trong cụm Hadoop.
-
Khi dữ liệu đã ở trong Hadoop, chúng ta cần test sự chính xác và đẩy đủ của dữ liệu. Cần so sánh trực tiếp giữa dữ liệu lưu trữ trong Hadoop và dữ liệu nguồn.
-
Để test dữ liệu trong Hadoop, tester cần nắm được các câu lệnh cơ bản để test dữ liệu : Hadoop Command Line, Pig, Spark, Hive. Đồng thời tester phải nắm được cơ bản SQL vì trong nhiều trường hợp thì dữ liệu nguồn là từ các hệ thống RDBMS.
-
Khi đã xác định được dữ liệu trong hadoop là chính xác, ứng dụng Big Data thực hiện các nghiệp vụ phân tích dữ liệu theo yêu cầu của khách hàng và bài toán. Do đó, tester cũng cần kiểm thử các tiến trình phân tích dữ liệu này.
-
Dữ liệu lưu trữ trong hadoop là rất lớn (đúng với tên Big Data) và không thể test trên toàn bộ tập dữ liệu này. Bởi vậy, trước khi thực hiện test ứng dụng thì việc quan trọng là chọn ra tập mẫu để thực hiện kiểm thử (đây gọi là tập Data Test).
-
Với mỗi chức năng cần test (căn cứ với yêu cầu khách hàng), tester cần thực hiện chạy process tương ứng trên tập Data Test. Sau đó so sánh kết quả với thực tế ứng dụng đã chạy để test các process này.
-
Dữ liệu sau khi qua các bước phân tích trên nền tảng hadoop sẽ được lưu trữ trong kho dữ liệu (Data Warehouse). Ở bước này cũng cần Tester kiểm thử lại dữ liệu lưu trữ trong Data Warehouse để đảm bảo các tiến trình phân tích và import dữ liệu vào Data Warehouse là chính xác.
-
Từ dữ liệu trong Data Warehouse, các ứng dụng Big Data có thể khai thác để triển khai nhiều nghiệp vụ khác nhau : Dashboard, BI (Bussiness Intelligence), Report… Các bước này cần Test kiểm thử lại việc khai thác dữ liệu như một ứng dụng thông thường.
Thông qua diễn giải chi tiết ở trên, các bước thực hiện kiểm thử dữ liệu lớn có thể chia làm 3 nhóm công việc chính như sau :
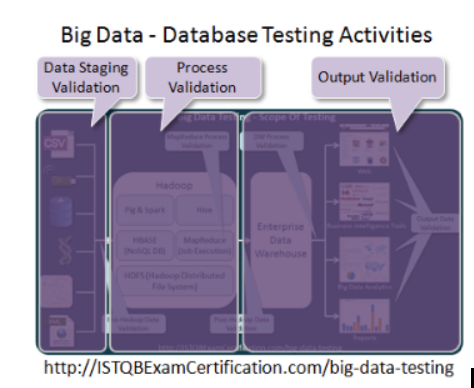
- Kiểm thử dữ liệu đầu vào (Data Staging Validation) : kiểm thử dữ liệu từ nhiều nguồn khác nhau, qua các bước tiền xử lý và load vào Hadoop
- Kiểm thử tiến trình xử lý dữ liệu trong database Hadoop (Process Validation) : Kiểm thử độ chính xác của các tiến trình phân tích/xử lý dữ liệu trong Hadoop.
- Kiểm thử kết quả đầu ra (Output Validation) : Kiểm thử dữ liệu lưu trữ trong Warehouse và các nghiệp vụ Big Data dựa trên dữ liệu này.
II. Các công cụ hỗ trợ Test ứng dụng Big Data :
Hiện tại có 3 công cụ hỗ trợ Test ứng dụng Big Data phổ biến :
-
TestingWhiz : cung cấp giải pháp kiểm thử Big Data tự động (automated Big Data testing solution), cho phép tester thực hiện các nghiệp vụ Test dữ liệu đầu vào (hỗ trợ cả dữ liệu có cấu trúc và phi cấu trúc), Test tiến trình xử lý dữ liệu (hỗ trợ các ngôn ngữ phân tích dữ liệu lớn như Hive, MapReduce, Pig..).
-
QuerySurge
-
Tricentis
Tuy nhiên cả 3 ứng dụng này đều là ứng dụng mất phí, do đó việc tiếp cận để thử nghiệm là khá khó khăn và thường được các công tỵ mua => lập đội nghiên cứu và sử dụng.
All rights reserved
