Big Data Testing
Bài đăng này đã không được cập nhật trong 7 năm
I. Big Data là gì?
- Big Data không chỉ đơn giản nói đến khối lượng dữ liệu lớn mà còn nói đến tốc độ dữ liệu và tính đa dạng của dữ liệu.
- Khi chúng ta có một khối lượng dữ liệu hợp lý, chúng ta thường sử dụng các CSDL quan hệ truyền thống như Oracle, MySQL, SQL Server để lưu trữ và làm việc.
- Tuy nhiên khi chúng ta có khối lượng data lớn sẽ không thể sử dụng các CSDL truyền thống để làm việc được nữa.

- Những CSDL truyền thống sẽ làm việc tốt với cấu trúc data được lưu trữ dưới dạng dòng và cột. Còn những data không có cấu trúc thì khi tạo quan hệ trong CSDL thì sẽ khó mà chính xác được
- Với big data có tính đa dạng dữ liệu thì một lượng lớn dữ liệu có thể có ở bất kỳ định dạng nào như image,flat files, audio,... có cấu trúc và định dạng không giống nhau giữa các records thì cũng khó để quản lý bởi các database truyền thống.
- Đặc trưng của Big data là: Volume Velocity Variety.
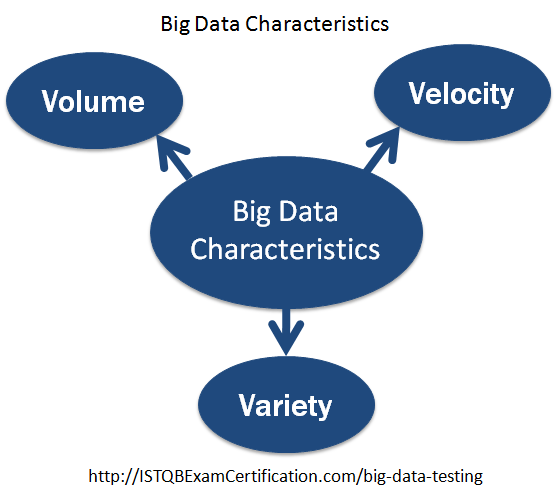
II. Ứng dụng của Big data trên thực tế
1. E-commerce
- Amazon, Flipkart và những trang thương mại khác có hàng triệu khách truy cập mỗi ngày với hàng trăm ngàn sản phẩm. Amazon đã sử dụng big data để làm thông tin lưu trữ sản phẩm, khách hàng và đặt hàng.
- Ngoài ra còn thu thập xung quanh các tìm kiếm sản phẩm, views, sản phẩm đã được thêm vào giỏ hàng, giỏ hàng bị loại, các sản phẩm được mua cùng nhau, ...
- Tất cả data này được lưu trữ và xử lý theo thứ tự đề xuất sản phẩm mà khách hàng yêu thích nhất khi mua.
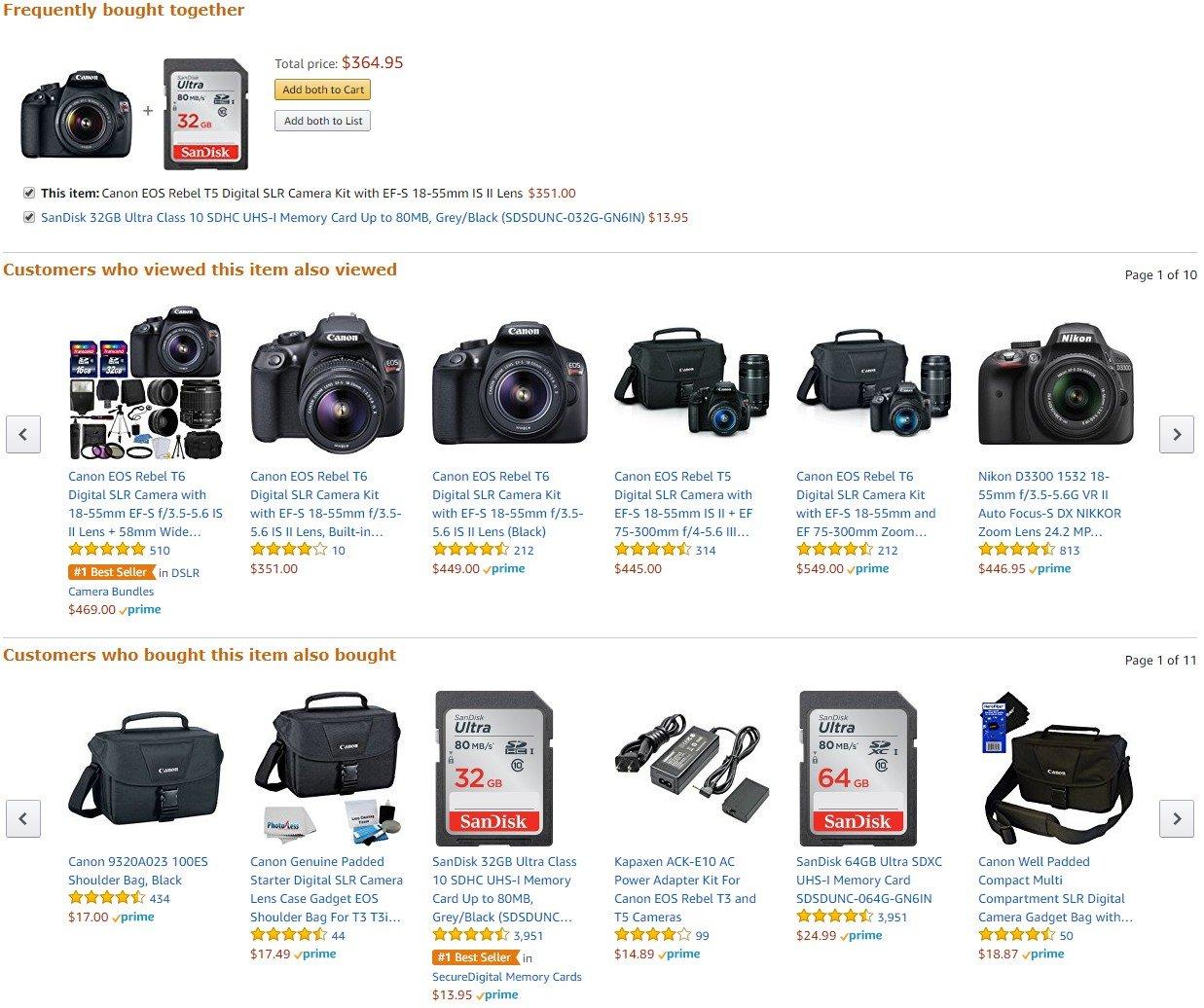
- Nếu bạn mởi 1 trang sản phẩm, bạn có thể nhìn thấy action này ở dưới : “Frequently bought together”, “Customers who bought this item also bought” and “Customers who viewed this item also viewed”. Các thông tin này được sử dụng để recommend deals / discounts và xếp hạng sản phẩm trong kết quả tìm kiếm
![]()
- Tất cả các dữ liệu này phải được xử lý rất nhanh, điều này không khả thi với CSDL truyền thống.
2. Social Media
-
Các trang social media thường chứa lượng data khổng lồ về pictures, videos, likes, posts, comments,... Không chỉ được lưu trữ trên nền tảng big data, nó còn có thể xử lý và phân tích để đưa ra các đề xuất trên nội dung mà người dùng yêu thích.
![]()
-
Không chỉ lưu trữ data ngoài ra còn có thể xử lý và phân tích để đưa ra những đề xuất mà người dùng hứng thú. Ví dụ: Khi bạn search cụm từ "SamSung" trên Amazon và di chuyển đến facebook. Trên facebook sẽ hiển thị quảng cáo cho những cái tương tự.
-
Đây là một trường hợp sử dụng big data vì có hàng triệu trang web quảng cáo trên facebook và hàng tỷ người dùng.
-
Lưu trữ và xử lý thông tin này để hiển thị quảng cáo phù hợp cho đúng user có nhu cầu, không thể thực hiện bằng CSDL truyền thống trong cùng một khoảng time.
-
Mục tiêu đúng khách hàng và đúng quảng cáo là rất quan trọng vì người mà tìm kiếm SamSung sẽ thích thú để click vào những quảng cáo của SamSung hơn là những quảng cáo của Apple.

III. Format data trong Big Data
Có 1 câu hỏi đã được đặt ra ngay từ đầu là "Vì sao chúng ta không thể sử dụng CSDL truyền thống cho big data".
Để trả lời câu hỏi trên đầu tiên chúng ta cần nắm format của big data là gì?
Format của big data được phân thành 3 loại:
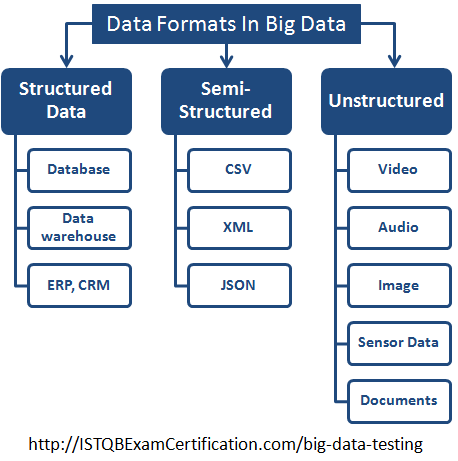
1. Structured Data
- Liên quan đến các dữ liệu được tổ chức ở mức cao
- Được lưu trữ dễ dàng trong bất cứ database nào
- Có thể dễ dàng lấy/ tìm kiếm dữ liệu bằng cách sử dụng các câu query đơn giản.
2. Semi Structured Data
- Không được tổ chức chặt chẽ
- Thường không được lưu trữ trong database.
- Có thể lưu trữ database quan hệ sau khi được xử lý và convert sang định dạng có cấu trúc.
3. Unstructured data
- Không có xác định cụ thể format
- Nó không theo mô hình dữ liệu có cấu trúc
- Images, Videos, documents, mp3 có thể được coi là Unstructured data mặc dù chúng có cấu trúc bên trong.
- Có tới 80% data được tạo ra trong một tổ chức là phi cấu trúc.
Vậy các CSDL truyền thống không thể hỗ trợ cho big data bởi vì
- Các CSDL truyền thống như Oracle, MySQL, SQL Server không thể sử dụng cho big data bởi vì hầu hết dữ liệu là Unstructured data
- Đa dạng dữ liệu: Dữ liệu có thể là images, video, pictures, text, audio, ... Dữ liệu này không thể lưu trữ dưới dạng cột và dòng của RDBMS (Relational Database Management System)
- Khối lượng data được lưu trữ của big data là khổng lồ. Dữ liệu này cần được xử lý nhanh và điều này đòi hỏi dữ liệu phải được xử lý song song . Việc xử lý song song dữ liệu trong RDBMS sẽ rất tốn kém và không hiệu quả.
- CSDL truyền thống không được xây dựng để lưu trữ và xử lý data với khối lượng lớn/ kích thước lớn. Ví dụ: hình ảnh trên facebook, dữ liệu cho google map,...
- Vận tốc tạo dữ liệu: CSDL truyền thống không thể lưu trữ hoặc truy xuất cho những data có tốc độ tạo ra nhanh như là: 6000 tweet được tạo ra mỗi giây, 510.000 bình luận được tạo ra mỗi phút.
IV. Chiến lượt thực hiện test big data applications
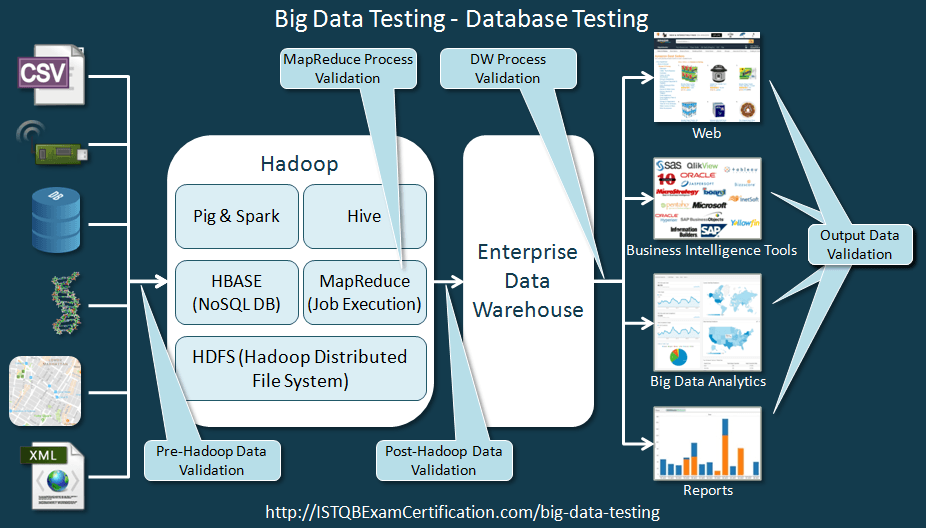
1. Hadoop là gì?
- Là một Apache framework mã nguồn mở được viết bằng java, cho phép xử lý phân tán (distributed processing) các tập dữ liệu lớn trên các cụm máy tính (clusters of computers) thông qua mô hình lập trình đơn giản.
- Hadoop được thiết kế để mở rộng quy mô từ một máy chủ đơn sang hàng ngàn máy tính khác có tính toán và lưu trữ cục bộ (local computation and storage).
2. Hướng dẫn cách cài đặt hadoop trên windows
https://www.youtube.com/watch?v=LUhSv06qrdA
3. Hadoop hoạt động như thế nào?
Giai đoạn 1
- Một user hay một ứng dụng có thể submit một job lên Hadoop (hadoop job client) với yêu cầu xử lý cùng các thông tin cơ bản
- Nơi lưu (location) dữ liệu input, output trên hệ thống dữ liệu phân tán.
- Các java class ở định dạng jar chứa các dòng lệnh thực thi các hàm map và reduce.
- Thiết lập cụ thể liên quan đến job thông qua các thông số truyền vào.
Giai đoạn 2
- Hadoop job client submit job (file jar, file thực thi) và các thiết lập cho JobTracker.
- Sau đó, master sẽ phân phối tác vụ đến các máy slave để theo dõi và quản lý tiến trình các máy này, đồng thời cung cấp thông tin về tình trạng và chẩn đoán liên quan đến job-client.
Giai đoạn 3
- TaskTrackers trên các node khác nhau thực thi tác vụ MapReduce và trả về kết quả output được lưu trong hệ thống file.
- Khi “chạy Hadoop” có nghĩa là chạy một tập các daemon, hoặc các chương trình thường trú, trên các máy chủ khác nhau trên mạng của bạn.
- Những daemon có vai trò cụ thể, một số chỉ tồn tại trên một máy chủ, một số có thể tồn tại trên nhiều máy chủ.
- Các daemon bao gồm: NameNode, DataNode, SecondaryNameNode, JobTracker, TaskTracker
4. Cấu trúc Hadoop
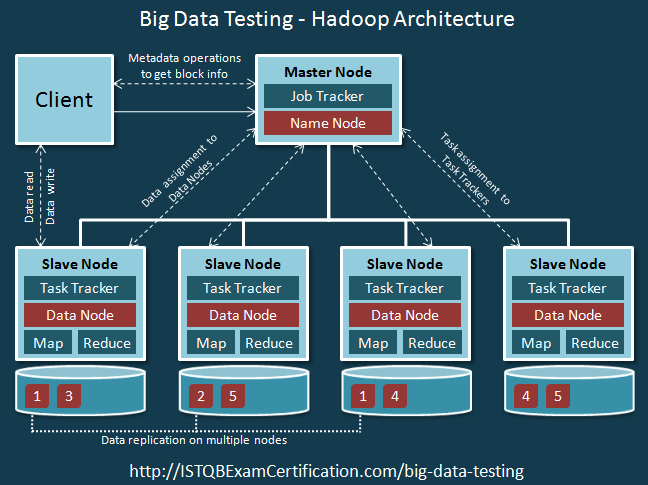
- Biểu đồ trên thể hiện cấu trúc của Hadoop. Mỗi node (Client, Master Node, Slave Node) đại diện cho một máy.
- Hadoop được cài đặt trên các máy client và kiểm soát công việc bằng cách tải cluster data, submit Map Reduce job và cấu hình xử lý của data.
- Tât cả các máy được tạo thành 1 cluster. Có thể có nhiều cluster trong network.
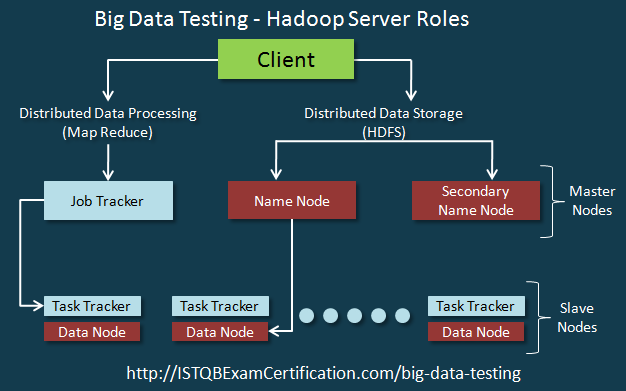
-
Master Nodes có 2 vai trò chính:
Đầu tiên là chúng xử lý lưu trữ phân tán dữ liệu bằng NameNodes.
Thứ hai là xử lý song song của dữ liệu (MapReduce) được điều phối bởi JobTracker.
-
Các NameNode thứ cấp sẽ hoạt động như NameNode dự phòng.
-
Slave nodes tạo thành các máy chủ. Chúng lưu trữ và xử lý dữ liệu. Mỗi Slave nodes sẽ có Data Node và Task Tracker.
-
Data Node là slave nhận các hướng dẫn từ NameNodes và thực hiện lưu trữ dữ liệu như bên dưới
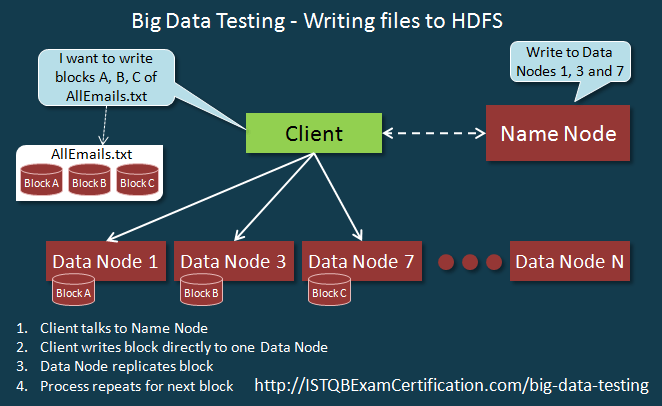
- TaskTracker là slave nhận các hướng dẫn từ JobTracker. Nó xử lý dữ liệu bằng MapReduce, đây là 1 quá trình gồm 2 bước như dưới
![]()
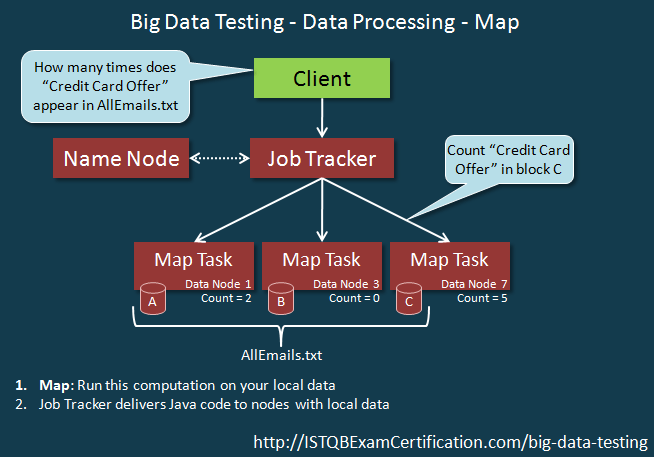
Chuỗi events của xử lý Reduce được hiển thị như dưới.
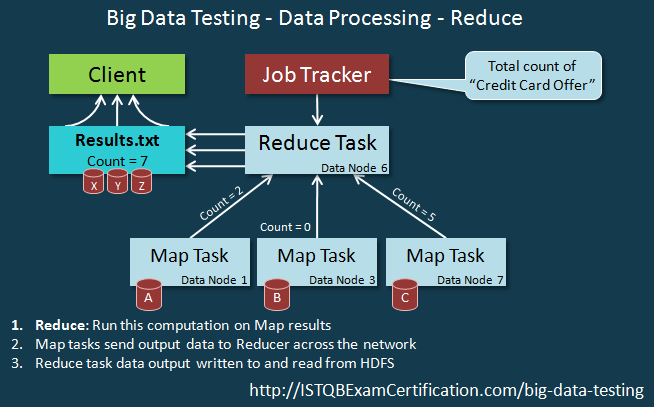
V. Kết luận
Big data đã và đang là một trong những vấn đề trung tâm, nhận được nhiều sự quan tâm trong cuộccách mạng công nghiệp lần thứ tư.
Big data chính là cốt lõi để sử dụng, phát triển internet vạn vật (IoT) vàtrí tuệ nhân tạo (AI).
Theo dự báo, cách mạng công nghiệp lần thứ tư sẽ tạo ra một lượng lớn dữ liệu, dự kiến đến năm 2020, lượng dữ liệu sẽ tăng gấp 50 lần hiện nay
Thông qua thu thập, phân tích và xử lý lượng big data này sẽ tạo ra những tri thức mới, hỗ trợ việc đưa ra quyết định của các chủ thể trên thế giới (doanh nghiệp, chính phủ,người dân).
VI. Reference
http://tryqa.com/big-data-testing/
https://www.guru99.com/big-data-testing-functional-performance.html
All rights reserved
