Bên Trong Node.js [2] - Thư Viện Libuv
Bài đăng này đã không được cập nhật trong 4 năm
Ở bài viết trước ta đã tìm hiểu về cách vận hành của các javascript engine, và một engine tiêu biểu là V8 của Chrome. Tuy nhiên vấn đề là các javascript engine chỉ xuất hiện ở browser, tức là chỉ dịch được ngôn ngữ javascript trên browser. Ta không thể dịch ở các nơi khác, chính vì lẽ đó mà node.js mới ra đời. Node.js giúp chuyển đổi mã javascript ngay trên hệ điều hành mà không cần đến browser, và nó hoạt động ở cả Window, Linux hay Mac.
Cấu trúc
Để hiểu làm thế nào node.js có thể dịch được Javascript ta phải biết cấu tạo bên trong nó.
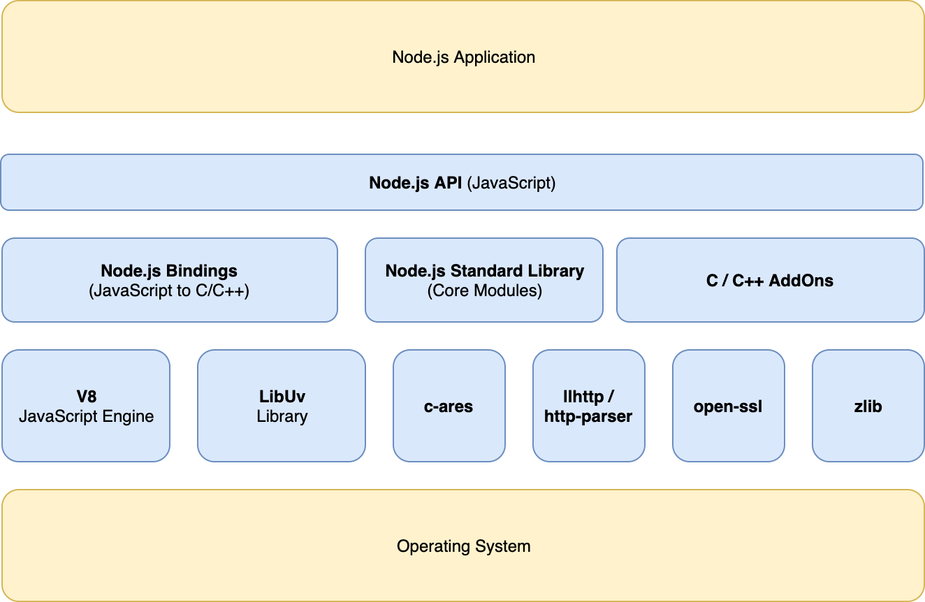
Các thành phần bao gồm
- V8: đã giới thiệu ở bài trước.
- libuv: bao gồm Thread Pool, Event Loop và Event Queue. Là thư viện C đa nền tảng tập trung vào các tác vụ I/O bất đồng bộ.
- Node.js Standard Library: bao gồm các thư viện, chức năng liên quan đến hệ điều hành như
setTimeout,fs,http. - c-ares: thư viện C cho DNS bất đồng bộ được sử dụng trong dns modules.
- llhttp: trình phân tích cú pháp request/response HTTP.
- open-ssl: các chức năng mã hoá được sử dụng trong TLS(SSL), crypto module.
- zlib: nén và giải nén bằng chạy đồng bộ, bất đồng bộ và streaming.
- Node.js API: cung cấp JavaScript API được sử dụng bởi các ứng dụng.
Như vậy tổng quát là Node.js là nơi có thể thực thi code JS bên ngoài trình duyệt. Và vì được xây bởi V8 nên Node.js có thể tận dụng mọi tính năng của V8.
Kế tiếp để hiểu được rõ hoạt động của Node.js ta sẽ không đi chi tiết từng thành phần vì nó vô cùng phức tạp và tốn rất nhiều thời gian, đồng thời không phải ai cũng cần biết tất cả mọi thứ như vậy, nên ta sẽ chỉ hiểu về cơ chế gọi là Asynchronous Event-Driven Nonblocking I/O của Node.js
Trước khi ta bắt đầu sẽ đi qua các khái niệm:
I/O
I/O là quá trình giao tiếp (lấy dữ liệu vào, trả dữ liệu ra) giữa một hệ thống thông tin và môi trường bên ngoài. Với CPU, thậm chí mọi giao tiếp dữ liệu với bên ngoài cấu trúc chip như việc nhập/ xuất dữ liệu với memory (RAM) cũng là tác vụ I/O. Trong kiến trúc máy tính, sự kết hợp giữa CPU và bộ nhớ chính (main memory – RAM) được coi là bộ não của máy tính, mọi thao tác truyền dữ liệu với bộ đôi CPU/Memory, ví dụ đọc ghi dữ liệu từ ổ cứng đều được coi là tác vụ I/O.
Do các thành phần bên trong kiến trúc phụ thuộc vào dữ liệu từ các thành phần khác, mà tốc độ giữa các thành phần này là khác nhau, khi một thành phần hoạt động không theo kịp thành phần khác, khiến thành phần khác phải rảnh rỗi vì không có dữ liệu làm việc, thành phần chậm chạp kia trở thành một bottle-neck, kéo lùi hiệu năng của toàn bộ hệ thống.
Dựa theo các thành phần của kiến trúc máy tính hiện đại, tốc độ thực hiện tiến trình phụ thuộc:
- CPU Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi tốc độ xử lý của CPU
- Memory Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi dung lượng khả dụng và tốc độ truy cập của bộ nhớ
- Cache Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi số lượng ô nhớ và tốc độ của các thanh cache khả dụng
- I/O Bound: Tốc độ thực hiện tiến trình bị giới hạn bởi tốc độ của các tác vụ IO
Do tốc độ I/O thường rất chậm so với các thành phần còn lại, bottle-neck thường xuyên xảy ra ở đây. Người ta thường xét đến I/O Bound và CPU Bound, cố gắng đưa các process bị giới hạn bởi I/O bound về CPU bound để tận dụng tối đa hiệu năng.
Blocking I/O vs Nonblocking I/O
Blocking I/O
Yêu cầu thực thi một IO operation, sau khi hoàn thành thì trả kết quả lại. Pocess/Theard gọi bị block cho đến khi có kết quả trả về hoặc xảy ra ngoại lệ.
Nonblocking I/O
Yêu cầu thực thi IO operation và trả về ngay lập tức (timeout = 0). Nếu operation chưa sẵn sàng để thực hiện thì thử lại sau. Tương đương với kiểm tra IO operatio có sẵn sàng ngay hay không, nếu có thì thực hiện và trả về, nếu không thì thông báo thử lại sau.
Synchronous vs Asynchronous
Synchronous:
Hiểu đơn giản: Diễn ra theo thứ tự. Một hành động chỉ được bắt đầu khi hành động trước kết thúc.
Asynchronous:
Không theo thứ tự, các hành động có thể xảy ra đồng thời hoặc chí ít, mặc dù các hành động bắt đầu theo thứ tự nhưng kết thúc thì không. Một hành động có thể bắt đầu (và thậm chí kết thúc) trước khi hành động trước đó hoàn thành.
Sau khi gọi hành động A, ta không trông chờ kết quả ngay mà chuyển sang bắt đầu hành động B. Hành động A sẽ hoàn thành vào một thời điểm trong tương lai, khi ấy, ta có thể quay lại xem xét kết quả của A hoặc không. Trong trường hợp quan tâm đến kết quả của A, ta cần một sự kiện Asynchronous Notification thông báo rằng A đã hoàn thành.
Vì thời điểm xảy ra sự kiện hành động A hoàn thành là không thể xác định, việc bỏ dở công việc đang thực hiện để chuyển sang xem xét và xử lý kết quả của A gây ra sự thay đổi luồng xử lý của chương trình một cách không thể dự đoán. Luồng của chương trình khi ấy không tuần tự nữa mà phụ thuộc vào các sự kiện xảy ra. Mô hình như vậy gọi là Event-Driven.
Event Driven
Asynchronous và Event-Driven không phải là một điều gì quá mới mẻ. Thực tế nó đã tồn tại trong ngành khoa học máy tính từ những ngày đầu. Cơ chế ngắt (Interrupt) là một signal thông báo cho hệ thống biết có một event vừa xảy ra.
Khi ngắt xảy ra, hệ thống buộc phải dừng chương trình đang chạy để ưu tiên chạy một chương trình khác gọi là Chương Trình Phục Vụ Ngắt (Interrupt Service Routine) rồi mới quay trở lại thực hiện tiếp chương trình đang chạy dở.
Có hai loại ngắt: Ngắt Cứng và Mgắt Mềm. Ngắt mềm được gọi bằng một lệnh trong ngôn ngữ máy (và hợp ngữ, dĩ nhiên). Ngắt cứng thì chỉ có thể được gọi do các linh kiện điện tử tác động lên hệ thống.
Vậy thành phần nào trong node.js là thứ mang lại cơ chế Asychronous Event-Driven Non-Blocking I/O. Câu trả lời đấy chính là libuv - thư viện multi-platform hỗ trợ asynchronous I/O.
libuv
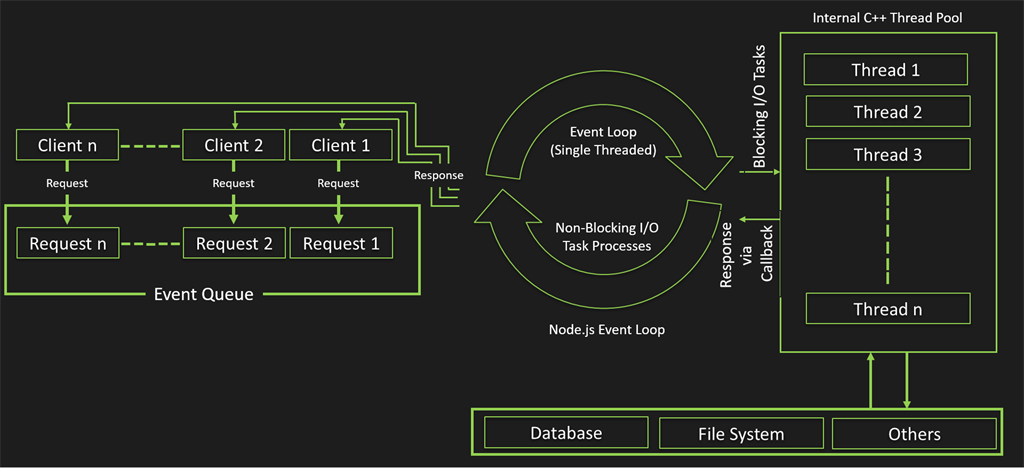
Thông qua hình ta thấy libuv bao gồm các thành phần là: Event Queue, Event Loop và Threal Pool.
Nếu như ở các ngôn ngữ như PHP hay Java, để giải quyết vấn đề nhiều yêu cầu cùng một lúc người ta sử dụng khái niệm đa luồng, tức là ứng với mỗi yêu cầu sẽ sinh ra một luồng mới để giải quyết. Nhưng vì node.js sử dụng đơn luồng tức là mọi yêu cầu đều nằm trên một luồng chính (main thread). Nên các yêu cầu sẽ phải nằm trong Event Queue để đợi thực hiên, khi đó Event Loop sẽ tiến hành thực thi các tác vụ trên một luồng duy nhất theo cơ chế non-blocking I/O. Để giảm tải các tác vụ nặng nề, chúng sử dụng thêm Thread Pool.
Thread Pool
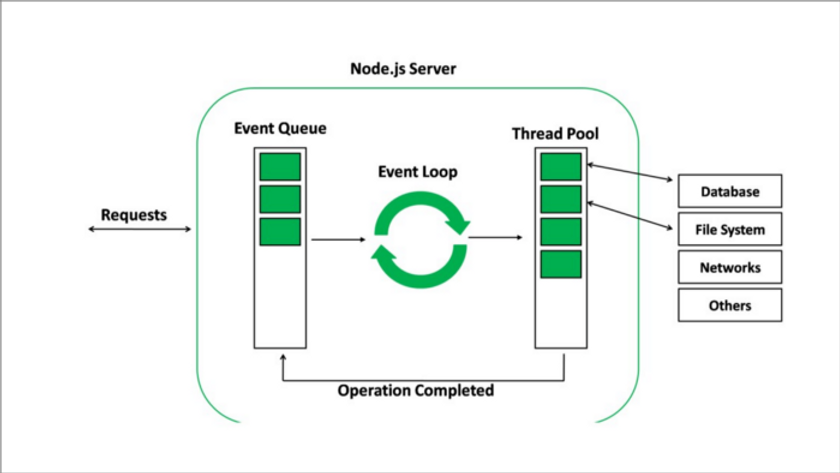
Thread Pool là những luồng riêng biệt độc lập với luồng chính ở Event Loop. Trong node.js chúng có thể database, file system, network và vài tác vụ khác. Khi yêu cầu từ Event Queue sang Event Loop, chúng sẽ kiểm tra có phải là tác vụ nặng hay không, nếu phải chúng sẽ được tải xuống Thread Pool và thực thi ở đấy. Điều này giúp luồng chính ở Event Loop giảm nguy cơ bị nghẽn và có thể xử lý các tác vụ đơn giản hơn.
Các tác vụ tốn kém phải xử lý ở Thread Pool thường sẽ là :
- File System: Các hoạt động được xử lý bởi module fs như
fs.write,fs.readStream. - Network Calls: Các yêu cầu mạng như
dns.resolve,dns.lookup,http.get,socket.connect. - Timers: các hoạt động liên quan đến thời gian như
setTimeout,setImmediatehoặcsetInterval.
Notes: Ở đây lưu ý rằng không phải tất cả tác vụ tiêu tốn thời gian đều là tác vụ I/O. Ví dụ như chương trình dưới đây:
for (var i = 0; i < 10000; i++) {
crypto.createHash(); // CPU intensive task
// or
sleep(2); // CPU intensive task
}
console.log('After CPU intensive task');
Trong đoạn code trên tác vụ chuyên sâu CPU sẽ chặn luồng chính và không thực thi lệnh console ngay lập tức như khi với các hoạt động I/O bất đồng bộ. Đơn giản là do tác vụ chuyên sâu CPU sẽ ràng buộc CPU phải được thực thi ngay lập tức, còn đối với tác vụ ràng buộc I/O, nó được chuyển tới libuv để được xử lý bất đồng bộ. Do đó node.js được coi là không phù hợp với các tác vụ chuyên sâu về CPU mà là phù hợp hơn với các tác vụ chuyên sâu về I/O.
Event Loop
Như đã đề cập ở trên Event Loop sẽ lấy yêu cầu từ Event Queue để xử lý. Thứ tự thực hiện với các hàm trong Event Loop như sau:
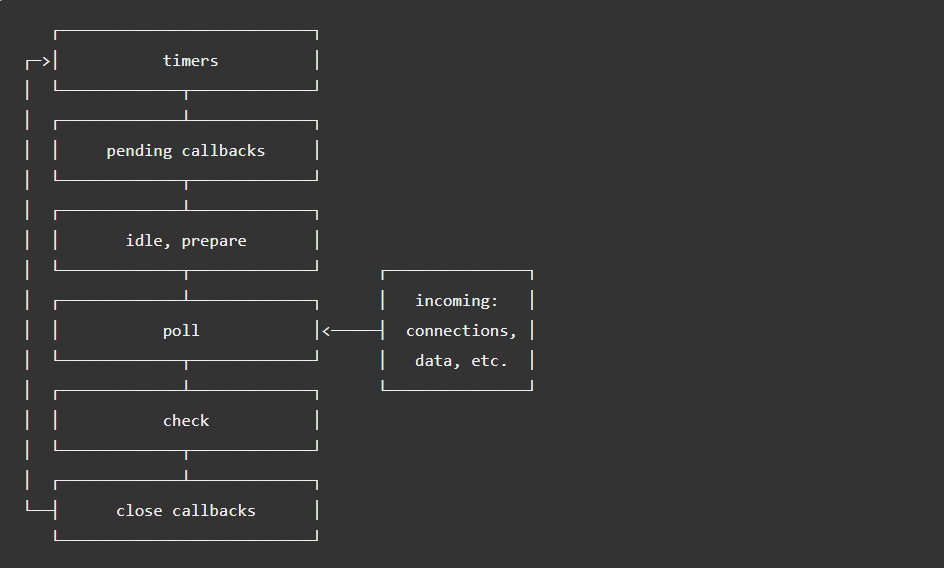
- timers: thực thi các hàm callback đã được lên lịch với
setTimeoutvàsetInterval. - I/O callbacks: thực hiện hầu hết tất cả các lệnh gọi lại ngoại trừ close callback, timers callback và
setImmediate(). - idle, prepare: dùng cho việc xử lý nội bộ của node.js.
- poll: truy xuất các sự kiện I/O mới, chấp nhận các kết nối đến và xử lý dữ liệu.
- check: xử lý hàm callback của
setImmediate. - close callbacks: thực thi các hàm callbacks cho các sự kiện close. Ví dụ:
socket.on("close").
Các thành phần khác
V8 Engine
Phần V8 đã tìm hiểu ở bài viết trước, giờ đây ta tìm hiểu về ứng dụng của V8 trong nodejs. V8 trong node bao gồm hai phần là call stack và memory heap.
- memory heap: vùng nhớ được dùng để lưu kết quả được tính toán ở các hàm trong call stack. Cũng như trong C++ nó có thể được cấp phát tĩnh hoặc cấp phát động.
- call stack: Hoạt động theo đúng nghĩa stack LIFO - Last In First Out. Khi chương trình thực thi đến hàm nào, thì hàm đó sẽ đẩy vào trong call stack. Và nó chỉ được lấy ra khi đã hoàn thành và return.
Node APIs
Chứa các hàm như setTimeout(), fs.readFile(), emitter,... Không phải bất cứ câu lệnh nào cũng được thực thi ngay trên call stack, ví dụ như những hàm trên sẽ được đưa sang Node APIs khi gọi đến.
Callback Queue
Nơi chứa các hàm ở Node APIs xuống. Nó sẽ ở đây chờ đến khi nào call stack rỗng để nhảy lên và thực thi tiếp các câu lệnh bên trong hàm.
Hoạt động
Ở trên ta đã có các khái niệm về nguyên lý hoạt động và các thành phần trong libuv cùng các thành phần khác. Nhưng chi tiết về quá trình hoạt động giữa các thành phần qua lại với nhau thì sao?
Ta có sơ đồ hoạt động như sau:
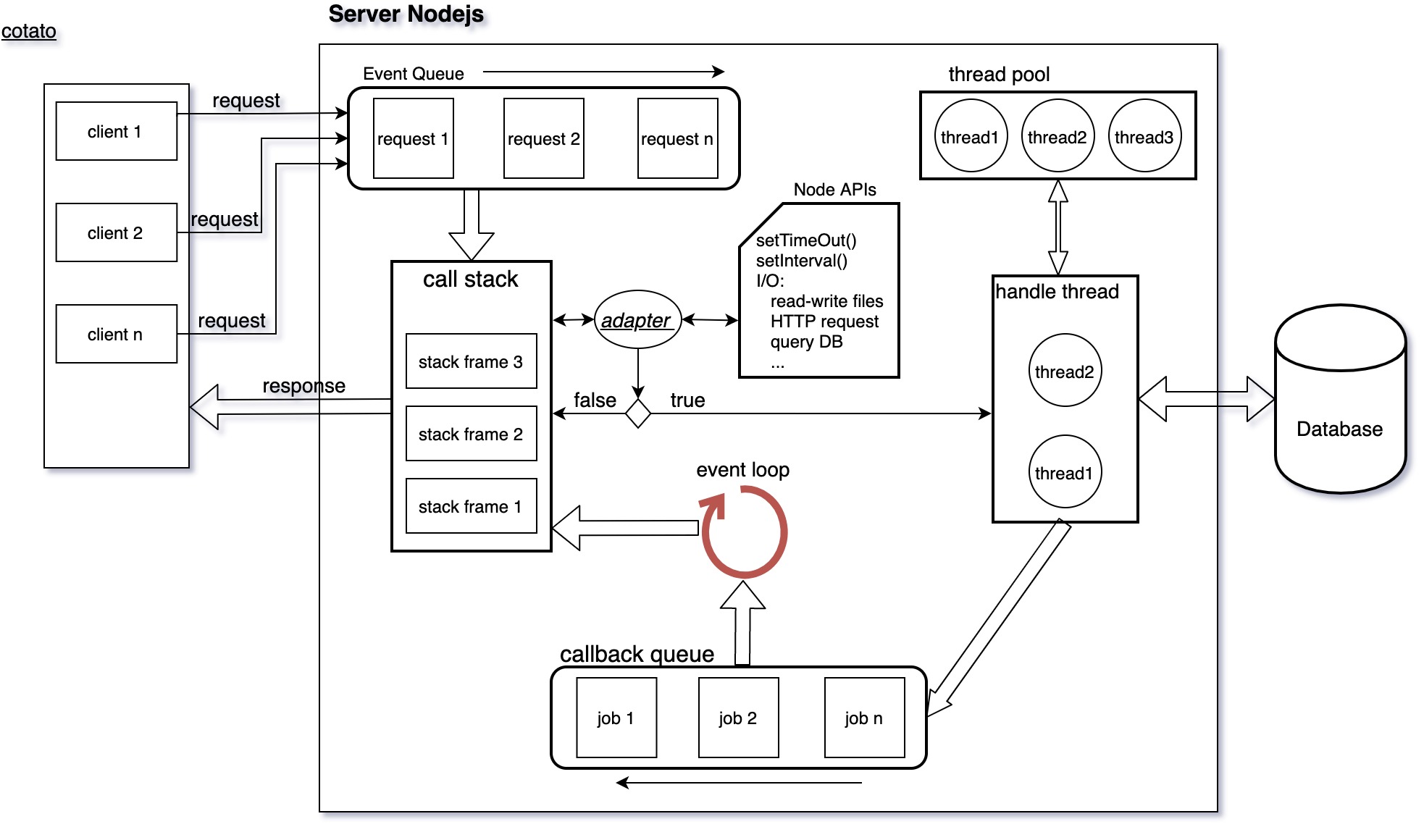
- Khi có nhiều request được gửi từ nhiều client trong cùng một thời điểm, các request này sẽ được đưa vào event queue hoạt động theo cơ chế FIFO - First In First Out.
- Request được lấy ra ở event queue sẽ được đưa đến call stack để xử lý. Ở đây, trên server sẽ thực thi các hàm để có kết quả trả về cho request đó.
- Khi trong call stack thực thi một hàm của một request, hàm này cần phải query dữ liệu trong DB. Vì query vào DB là hoạt động I/O được quy định trong Node APIs. Do vậy nó không thể thực thi trên call stack được.
- Để kiểm tra hàm trong call stack có được Node APIs đảm nhiệm không, nó sẽ có một adapter chuyên check viêhc hàm đó có trong Node APIs hay không.
- Nếu hàm không thực thi một tác vụ liên quan đến I/O thì adapter sẽ trả về
false. Ví dụ, request yêu cầu lấy thời gian của server, khi đó chỉ cầnreturn new Date()rồi response về cho client. Như vậy hàm mà córeturn new Date()không liên quan đến Node APIs nên nó sẽ được xử lý ngay trong call stack với thời gian rất nhanh và trả về cho client luôn. - Nếu nó thực thi một tác vụ liên quan đến I/O thì adapter sẽ trả về
true. Ví dụ như việc query vào DB, sẽ cần một thời gian nhất định. Khi đó Node APIs biết mình cần phải xử lý cái hàm đó. Nó sẽ lấy ra khỏi call stack để cho call stack thực thi các hàm khác. Đồng thời phân cho 1 thread có trong thread pool để xử lý tác vụ I/O trong hàm vừa lấy ra. - Thread này sẽ được xử lý trong handle thread, lấy dữ liệu trong DB, sau khi xong sẽ được đẩy xuống callback queue chờ ngày được lên lại call stack.
Tham khảo
All rights reserved
