Bên trong mã nguồn SeaweedFS (Blob storage) - P1
Lời mở đầu
Tiếp tục series hỏi hỏi từ các repo mã nguồn mở. Bài này ta sẽ đi tìm hiểu seaweedfs là một hệ thống tệp phân tán mã nguồn mở, có tốc độ cao và khả năng mở rộng lớn, được thiết kế đặc biệt để lưu trữ và truy xuất hiệu quả hàng tỷ tệp tin.
Ban đầu, dự án được lấy cảm hứng từ kiến trúc Haystack của Facebook để giải quyết bài toán lãng phí bộ nhớ RAM khi lưu trữ số lượng khổng lồ các tệp tin nhỏ (như ảnh đại diện, logo, bài viết). Anh em có thể đọc trước bài viết Haystack - Cách facebook lưu trữ hàng tỷ bức ảnh
SeaweedFS chính là một Blob Storage (Object Storage), tương tự như Amazon S3, Google Cloud Storage hay MinIO.
Cũng có dự định viết bài này phải tầm 2 năm về trước, nhưng lười giờ mới có động lực để viết.
1. Giới thiệu một chút
Seaweedfs được lấy ý tưởng từ Haystack của Facebook.
Trước khi có Haystack, Facebook lưu trữ ảnh qua mạng NFS, mỗi bức ảnh là một tệp riêng biệt . Thiết kế này gặp vấn đề nghiêm trọng với hệ thống tệp POSIX truyền thống vì siêu dữ liệu (metadata/inode) quá lớn, không thể lưu hết vào bộ nhớ đệm (RAM) được.
POSIX (viết tắt của Portable Operating System Interface) là một bộ tiêu chuẩn được đặt ra để đảm bảo tính tương thích giữa các hệ điều hành khác nhau (chủ yếu là các hệ điều hành hệ Unix như Linux, macOS, BSD).
Tiêu chuẩn POSIX được thiết kế từ hàng chục năm trước cho các máy tính thông thường, nơi số lượng tệp tin ở mức vừa phải. Nó không được tối ưu cho kịch bản lưu trữ hàng tỷ tệp tin dung lượng nhỏ (như ảnh đại diện, ảnh feed) như Facebook sau này.
Trong các hệ thống tệp tuân theo tiêu chuẩn POSIX (như ext4 trên Linux), một tệp tin không phải là một khối liền mạch duy nhất. Nó được chia làm hai phần: Dữ liệu thực tế (nội dung bức ảnh) và Siêu dữ liệu (Metadata).
Inode (viết tắt của Index Node) chính là cấu trúc dữ liệu lưu trữ phần Metadata đó.
Tại sao "POSIX + Inode" lại làm Facebook "sụp đổ" ở quy mô lớn?
Khi muốn xem một bức ảnh trên Facebook (theo cơ chế cũ):
- Hệ thống phải tìm tên tệp trong thư mục để lấy số inode tương ứng.
- Hệ thống đọc inode đó để biết dữ liệu ảnh nằm ở khối đĩa nào.
- Hệ thống đến khối đĩa đó để đọc bức ảnh lên và gửi cho bạn.
Để quá trình này diễn ra nhanh, hệ điều hành sẽ cố gắng lưu toàn bộ các inode (metadata) này vào bộ nhớ đệm (RAM).
Tuy nhiên, với Facebook, số lượng ảnh lên đến hàng tỷ. Dù mỗi inode chỉ nặng khoảng vài trăm bytes, nhưng nhân với vài tỷ tệp tin thì dung lượng metadata sẽ lên tới hàng Terabyte, vượt quá khả năng lưu trữ của RAM tại thời điểm đó.
Mặc dù các bức ảnh mới/phổ biến được phân phối nhanh qua mạng CDN, Facebook lại có lượng truy cập khổng lồ vào long tail – tức là các bức ảnh cũ, ít phổ biến. CDN không thể chứa hết lượng ảnh này, đẩy toàn bộ gánh nặng truy xuất siêu dữ liệu về máy chủ gốc.
Hậu quả là: Khi RAM hết chỗ, hệ thống buộc phải đọc inode từ ổ cứng. Mỗi lần người dùng tải một bức ảnh, hệ thống phải tốn 3 lần đọc ổ cứng (1 lần tìm tên, 1 lần đọc inode, 1 lần đọc dữ liệu ảnh).
Để giải quyết triệt để việc này, Facebook đã phát triển Haystack – hệ thống gộp hàng triệu bức ảnh nhỏ vào một tệp lớn duy nhất, từ đó giảm số lượng inode xuống tối thiểu và có thể lưu trọn vẹn vị trí của ảnh trong RAM.
2. Giải pháp cốt lõi của Haystack
Chìa khóa để giải quyết vấn đề là phải giảm lượng thao tác đĩa (disk I/O) xuống mức tối đa:
- Haystack làm điều này bằng cách gộp hàng triệu bức ảnh vào trong một tệp duy nhất rất lớn (khoảng 100 GB) thay vì mỗi ảnh một tệp.
- Bằng cách loại bỏ các siêu dữ liệu không cần thiết, Haystack giảm lượng siêu dữ liệu cho mỗi bức ảnh xuống mức cực nhỏ (khoảng 10 byte), cho phép toàn bộ cấu trúc chỉ mục (chứa thông tin về vị trí tệp, kích thước) được đưa thẳng vào RAM. Nhờ vậy, Haystack chỉ mất tối đa một thao tác đĩa để đọc nội dung ảnh
3. Kiến trúc hệ thống Haystack
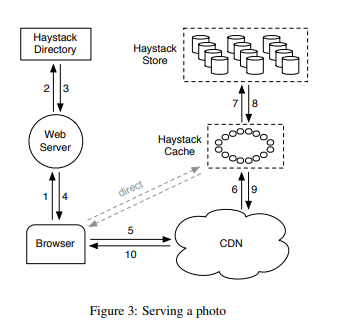
Haystack Store: Đảm nhiệm việc lưu trữ ảnh vĩnh viễn trên các phân vùng vật lý lớn. Các ảnh mới được ghi theo dạng append-only vào cuối tệp vật lý, và mỗi máy chủ lưu một bản đồ ánh xạ trên RAM để tìm ảnh ngay lập tức.
Haystack Directory: Đóng vai trò bộ não điều hướng, ánh xạ các phân vùng logic sang phân vùng vật lý, quản lý cân bằng tải và quyết định khi nào một máy chủ đã đầy để chuyển sang trạng thái "chỉ đọc" (read-only).
Haystack Cache: Hoạt động như một CDN nội bộ. Thành phần này đóng vai trò bảo vệ các máy chủ Store đang ở trạng thái ghi khỏi việc bị quá tải do lượng yêu cầu đọc lớn từ những bức ảnh mới vừa được tải lên.
Mình nói hơi nhiều về Haystack trong bài này để anh em hiểu về nó, khi mình nói về seaweedfs anh em sẽ dễ hiểu hơn.
4. Volume & index file
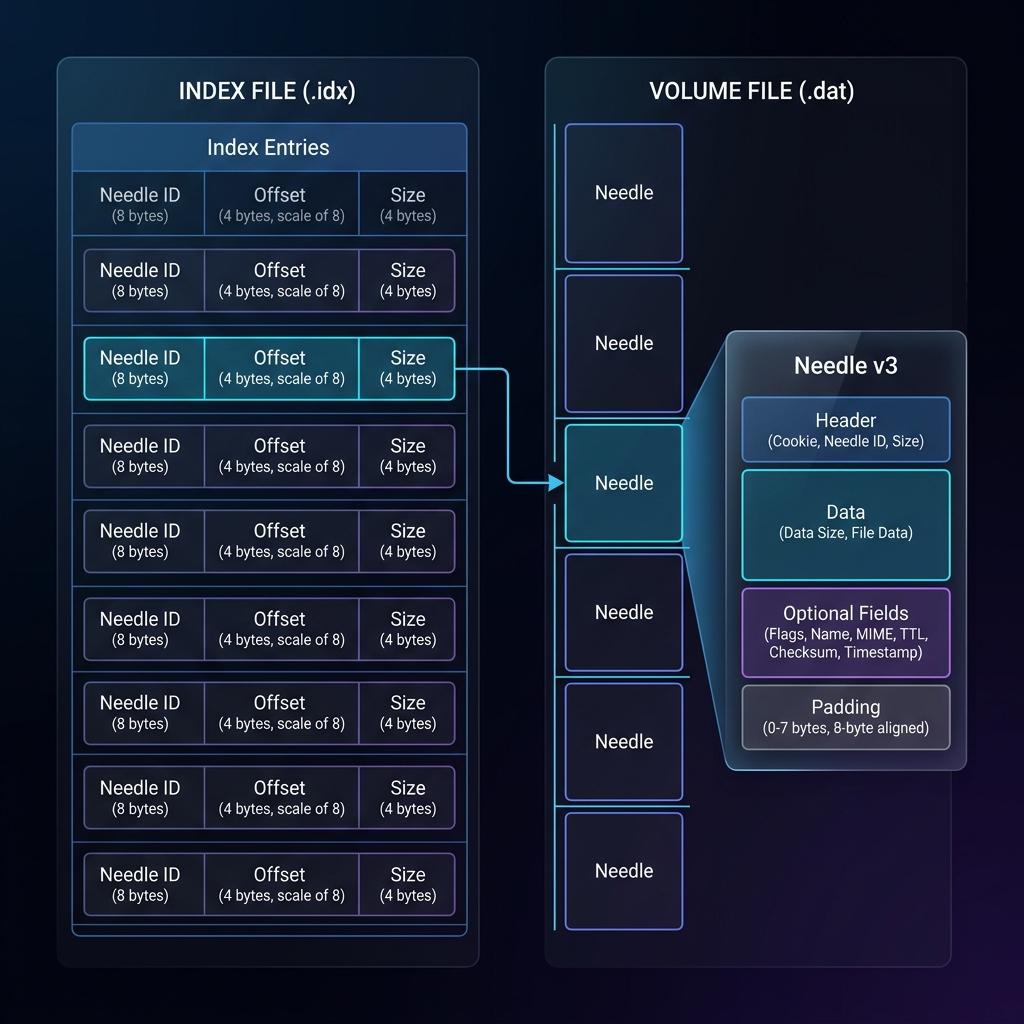
Như các phần trên đã nói việc quản lý các file riêng lẻ, inode gây quá tải với hệ thống quản lý file bình thường. Vậy thì làm cho file ít lại là được. Thế nên họ nghĩ ra lưu các file nhỏ vào 1 file to.
Một Volume trong SeaweedFS chính là một "hộp chứa khổng lồ" (thường có dung lượng tối đa 32GB) dùng để gom hàng triệu tệp tin nhỏ lại và lưu trữ chúng tập trung trên ổ đĩa.
Mỗi một Volume sẽ tương ứng với hai tệp tin thực tế nằm trong thư mục lưu trữ:
- Tệp dữ liệu (.dat): Đây là nơi chứa nội dung thực tế của tất cả các tệp tin người dùng tải lên. Các tệp tin này (gọi là Needle) được xếp hàng dọc và nối tiếp nhau từ đầu đến cuối tệp .dat.
- Tệp chỉ mục (.idx): Là một tệp mục lục nhỏ đi kèm. Nó ghi lại danh sách: "Tệp tin có ID này thì nằm ở vị trí (Offset) nào trong tệp .dat và có kích thước (Size) là bao nhiêu".
Nằm ở ngay 8 byte đầu tiên của tệp .dat, chứa các cấu hình cốt lõi của cả Volume đó (superblock):
- Version: Phiên bản định dạng của Volume.
- Replica Placement: Quy chế nhân bản (ví dụ: volume này cần được nhân bản sang bao nhiêu server khác, khác tủ rack hay khác trung tâm dữ liệu).
- TTL: Thời gian sống của các tệp tin trong volume (hết hạn sẽ tự động bị xóa).
=> superblock giúp triển khai các logic tương thích ngược với các volume có ver cũ hơn.
5. Cụ thể cách hoạt động của thao tác đọc
Bước 1: Client gửi yêu cầu đọc dữ liệu
Client gửi một yêu cầu HTTP GET (hoặc gRPC) tới Volume Server theo định dạng ID tệp tin: http://<volume-server-ip>/[VolumeID],[NeedleID][Cookie]
Ví dụ: /3,01af29c7d1
- VolumeID: 3
- NeedleID: 01af29
- Cookie: c7d1 (Khóa mật mã ngẫu nhiên để bảo mật tệp tin)
Bước 2: Khóa đọc & Tra cứu Index trong RAM (O(1))
- Hệ thống thiết lập một khóa đọc để đảm bảo dữ liệu không bị thay đổi hoặc nén trong lúc đang đọc.
- Tìm kiếm chỉ mục của tệp tin trong bộ nhớ RAM:
- Trường hợp 1: Nếu không tồn tại ID tệp tin Trả về ngay 404 Not Found mà không cần đụng vào ổ cứng.
- Trường hợp 2: Nếu tệp tin đã bị xóa (kích thước ghi nhận dạng âm hoặc Tombstone) Trả về 404 Not Found (hoặc báo lỗi tệp đã xóa).
- Trường hợp 3: Tìm thấy chỉ mục Trích xuất ra giá trị Offset (vị trí của tệp trên đĩa) và Size (độ dài dữ liệu).
Bước 3: Đọc trực tiếp từ đĩa (1 Disk Seek)
- Do Offset được lưu tối giản (scale of 8), Volume Server tính toán vị trí byte chính xác trên đĩa bằng công thức:
- Sử dụng cơ chế hệ thống đọc trực tiếp một phân đoạn dữ liệu có độ dài bằng Size từ vị trí ActualOffset trong file .dat. Quá trình này chỉ tốn đúng 1 lần dịch chuyển đầu đọc ổ đĩa (1 Disk Seek).
Bước 4: Xác thực tính hợp lệ (Validation)
- Xác thực Cookie: So sánh Cookie lưu trong Needle vừa đọc dưới đĩa với Cookie mà Client gửi lên. Nếu không khớp, lập tức từ chối. Điều này ngăn chặn việc tin tặc đoán mò ID tệp tin (brute-force).
- Xác thực Checksum (CRC32): Tính toán lại mã hash CRC32 của phần dữ liệu vừa đọc và đối chiếu với trường Checksum được lưu ở đuôi Needle. Bước này giúp phát hiện sớm các lỗi vật lý hỏng bit của ổ cứng.
Bước 6: Trả kết quả về cho Client
- Nếu tệp tin được lưu dưới dạng nén (kiểm tra bit flag FlagIsCompressed trong byte cờ hiệu), Volume Server sẽ tự động giải nén dữ liệu.
- Trả dữ liệu thô về cho Client kèm mã trạng thái 200 OK. Giải phóng khóa đọc RUnlock().
6. Cách tìm kiếm Needle Id tồn tại hay không ?
Do các file index sẽ được load vào RAM từ trước nên các thao tác tìm kiếm sẽ diễn ra trên RAM.
Thông thường, nếu dùng kiểu dữ liệu mặc định của Go là map[uint64]NeedleValue (Needle ID dài 8-byte) để lưu hàng triệu tệp tin, overhead (phần tiêu hao bộ nhớ quản lý map) của Go sẽ nuốt trọn dung lượng RAM.
SeaweedFS giải quyết việc này bằng cách chia nhỏ không gian khoá:
- Các Needle ID được chia thành các phân đoạn gọi là Segment.
- Mỗi Segment quản lý tối đa tệp tin.
- Một tệp tin có NeedleID sẽ thuộc về phân đoạn .
Bên trong mỗi Segment, thay vì lưu Needle ID gốc đầy đủ 8-byte (uint64), SeaweedFS chỉ lưu một Compact Key kiểu uint16 (chỉ tốn 2 bytes bộ nhớ): (Vì trong một phân đoạn tối đa chỉ có 50.000 phần tử nên giá trị này luôn vừa vặn trong kiểu uint16 từ 0 đến 65535).
Một bản ghi chỉ mục đầy đủ trong RAM chỉ tốn khoảng 10 bytes:
- key (CompactKey): 2 bytes
- offset (Vị trí trên đĩa): 4 bytes
- size (Kích thước tệp): 4 bytes
Tất cả các bản ghi này được lưu trong một mảng phẳng (slice) list []CompactNeedleValue và luôn được sắp xếp tăng dần theo key.
Quy trình tra cứu ID tồn tại:
- Xác định phân đoạn (Segment)
Tính toán nhanh: và tìm segment tương ứng trong map phân đoạn cm.segments[chunk].
Nếu phân đoạn này không tồn tại Kết luận ngay lập tức: Tệp KHÔNG tồn tại (không tốn thêm bất kỳ thao tác nào khác).
- Tối ưu hóa kiểm tra biên Nếu phân đoạn tồn tại, trước khi tìm kiếm nhị phân, hệ thống sẽ so sánh nhanh với các biên của mảng list trong Segment để tăng tốc tối đa:
Nếu phân đoạn tồn tại, trước khi tìm kiếm nhị phân, hệ thống sẽ so sánh nhanh với các biên của mảng list trong Segment để tăng tốc tối đa:
- Nếu mảng rỗng Không tồn tại.
- Nếu Key cần tìm bằng chính xác firstKey (phần tử nhỏ nhất segment) Trả về vị trí 0 (Tìm thấy).
- Nếu Key cần tìm bằng chính xác lastKey (phần tử lớn nhất segment) Trả về vị trí cuối cùng (Tìm thấy).
- Nếu Key nhỏ hơn firstKey hoặc lớn hơn lastKey Kết luận ngay lập tức: Không tồn tại.
- Tìm kiếm nhị phân Nếu không rơi vào các trường hợp biên trên, hệ thống sẽ tiến hành tìm kiếm nhị phân trên mảng đã được sắp xếp của Segment.
- Độ phức tạp thuật toán là . Do tối đa chỉ có phần tử, số lần so sánh tối đa trên RAM chỉ là lần, diễn ra trong vài nano giây.
- Nếu tìm thấy phần tử khớp Key:
- Hệ thống kiểm tra trường size. Nếu size < 0 hoặc bằng -1 (đã bị xóa trước đó) Trả về lỗi tệp đã xóa.
- Ngược lại Khôi phục lại Needle ID gốc (NeedleID = (50000 * chunk) + CompactKey) và trả về Offset và Size kèm cờ hiệu Tồn tại (ok = true).
7. Cập nhật file kiểu gì
Bước 1: Tiếp nhận yêu cầu cập nhật
Client gửi yêu cầu ghi tệp mới nhưng chỉ địnhVolume ID, Needle ID và Cookietrùng với tệp tin cũ đang có sẵn trên hệ thống.
Bước 2: Kiểm tra trùng lặp tuyệt đối
Nếu tệp mới hoàn toàn trùng khớp với tệp cũ về kích thước, nội dung và checksum Hệ thống không ghi gì thêm lên đĩa để tránh lãng phí I/O, trực tiếp trả về thành công
Bước 3: Xác thực bảo mật bằng Cookie
- Nếu nội dung có thay đổi, Volume Server sẽ đọc nhanh phần Header của Needle cũ đang nằm trên đĩa để lấy ra Cookie của nó.
- So sánh Cookie của tệp tin cũ với Cookie mà Client gửi lên. Nếu không khớp Từ chối thao tác cập nhật, ngăn chặn hacker ghi đè phá hoại tệp tin của người dùng khác.
Bước 4: Append dữ liệu phiên bản mới vào .dat
- Hệ thống đóng gói dữ liệu mới thành một Needle mới.
- Thực hiện append (ghi nối tiếp) Needle mới này vào cuối tệp .dat.
- Lúc này, trong tệp .dat vật lý đang tồn tại cả hai phiên bản của tệp tin: phiên bản cũ nằm ở vị trí cũ (ở giữa file) và phiên bản mới nằm ở cuối file.
Bước 5: Tráo đổi chỉ mục trong RAM
- Trong bộ nhớ CompactMap, giá trị Offset cũ sẽ bị ghi đè hoàn toàn bằng Offset mới, và Size cũ được ghi đè bằng Size mới.
- Kể từ lúc này, mọi yêu cầu đọc gửi tới Needle ID này sẽ lập tức được dẫn hướng tới vị trí phiên bản mới ở cuối file .dat. Phiên bản cũ chính thức bị "mồ côi" (không còn ai trỏ tới nữa).
Bước 6: Cập nhật file .idx
- Ghi nhận chỉ mục đĩa: Một dòng index 16 bytes mới (chứa Needle ID, Offset mới, và Size mới) được ghi nối tiếp vào cuối file chỉ mục .idx trên đĩa.
- Trả về phản hồi 200 OK thông báo cập nhật thành công cho Client.
8. Xóa file kiểu gì ?
Do cách hoạt động là append-only cuối tệp, và cũng để đảm bảo hiệu năng nên cách xóa cũng hơi khác 1 xíu so với bình thường.
Bước 1: Tiếp nhận yêu cầu từ Client
Client gửi yêu cầu HTTP DELETE /3,01af29c7d1 tới Volume Server chứa Volume 3.
Bước 2: Khóa ghi và kiểm tra tồn tại
Bước 3: Ghi nhận lịch sử xóa xuống đĩa
- Hệ thống khởi tạo một Needle trống, nhưng vẫn giữ nguyên Needle ID và Cookie ban đầu
- Tiến hành append Needle trống này xuống cuối tệp dữ liệu .dat.
- Tại sao lại phải ghi thêm vào .dat khi xóa?: Để đảm bảo tính nhất quán dữ liệu bền vững. Nó cũng có cơ chế sửa chữa, sinh lại file .idx khi bị hỏng, bị mất, ...
Bước 4: Đánh dấu xóa trong RAM
Trong bộ nhớ SeaweedFS tìm đến phần tử chứa Needle ID này và đổi trường kích thước của nó:
- Nếu kích thước ban đầu lớn hơn 0 Đổi dấu thành số âm (size = -size)
- Nếu kích thước ban đầu bằng 0 Gán bằng giá trị hằng số đặc biệt TombstoneFileSize (-1)
Bất kỳ yêu cầu đọc nào tìm đến ID này sau đó, khi thấy kích thước âm hoặc bằng -1 sẽ lập tức trả về lỗi 404 Not Found (Tệp đã bị xóa)
Bước 5: Cập nhật file chỉ mục .idx Bước 6: Cập nhật chỉ số thống kê & Trả kết quả
Bao giờ thì dữ liệu cũ thực sự biến mất khỏi ổ cứng?
Anh em có thể thắc mắc các tệp tin cũ vẫn nằm trong .dat và chiếm dụng dung lượng ổ cứng. Vậy dọn dẹp nó kiểu gì ?
Tùy vào config tiến trình Vacuum sẽ chạy để dọn dẹp các tệp tin đó bằng cách:
- Ngắt liên kết Volume cần dọn dẹp khỏi hệ thống
- Tạo Volume và file index mới -> tiến hành copy các tệp tin (needle) vẫn còn hoạt động sang volume mới này.
- Xóa volume cũ và liên kết lại volume mới làm sạch vào hệ thống.
All rights reserved
