Bên trong mã nguồn Qdrant - P1
Lời mở đầu
Chào mọi người. Cũng phải gần 3 năm mới quay lại đây để chia sẻ những thứ hay ho cho mọi người. Bắt đầu series em yêu khoa học sẽ là 1 database vector khá nổi - Qdrant.
Lý do chọn Qdrant thì là dạo gần hay code Rust nên chọn đại 1 cái open source viết bằng Rust.
Let go !
1. Qdrant là gì ?
Qdrant là một hệ quản trị cơ sở dữ liệu vector (Vector Database) và là công cụ tìm kiếm tương đồng mã nguồn mở rất nổi tiếng hiện nay. Nó được thiết kế chuyên biệt để phục vụ cho các ứng dụng AI thế hệ mới, các mô hình học máy và các mô hình ngôn ngữ lớn (LLM).
2. Dùng Jemalloc trên Linux và macOS
2.1. "Bộ cấp phát bộ nhớ" (Allocator) là gì?
Khi một database như Qdrant chạy, nó liên tục cần thêm bộ nhớ RAM để lưu trữ dữ liệu mới (ví dụ: khi nạp thêm vector) và giải phóng RAM khi dữ liệu đó bị xóa đi.
Mặc định, hệ điều hành (Linux, Windows, macOS) đều có sẵn một "ông" chuyên làm nhiệm vụ này (gọi là System Allocator). Tuy nhiên, "ông" mặc định này được thiết kế cho các tác vụ chung chung, nên đôi khi làm việc khá chậm và dễ gây ra hiện tượng phân mảnh bộ nhớ khi phải xử lý hàng triệu dữ liệu nhỏ liên tục.
2.2. Jemalloc là gì và tại sao Qdrant lại dùng nó?
-
Jemalloc là một bộ cấp phát bộ nhớ tùy chỉnh được phát triển bởi Jason Evans (ban đầu dùng cho hệ điều hành FreeBSD và sau đó được Facebook sử dụng rộng rãi).
-
Jemalloc nổi tiếng vì:
- Tránh phân mảnh: Nó quản lý RAM rất tốt, không để lại các "lỗ hổng" bộ nhớ lãng phí.
- Tốc độ cực nhanh: Đặc biệt tối ưu cho các hệ thống chạy đa luồng (CPU như Qdrant. Khi nhiều luồng cùng đòi cấp RAM một lúc, Jemalloc xử lý mượt mà hơn bộ cấp phát mặc định rất nhiều.
3. mmap
3.1. mmap là gì?
mmap (Memory Map - Ánh xạ bộ nhớ) là một hệ thống lệnh trong hệ điều hành (như Linux/Unix) cho phép ánh xạ trực tiếp một file từ ổ cứng (HDD/SSD) vào không gian bộ nhớ ảo của một ứng dụng.
Thông thường, khi một ứng dụng muốn đọc file, nó phải làm theo cách truyền thống:
-
Ổ cứng đọc dữ liệu vào vùng đệm của hệ điều hành (Page Cache).
-
Hệ điều hành copy dữ liệu đó một lần nữa vào vùng đệm của ứng dụng (User Space).
Với mmap: Bước copy thứ hai bị loại bỏ. Ứng dụng có thể tương tác với file trên ổ cứng giống hệt như thể nó là một mảng dữ liệu khổng lồ đang nằm sẵn trên RAM. Hệ điều hành sẽ tự động quản lý việc nạp dữ liệu từ ổ cứng lên RAM khi ứng dụng cần đến (gọi là cơ chế Page Fault).
3.2. Tại sao Qdrant lại sử dụng mmap?
Các cơ sở dữ liệu vector như Qdrant phải đối mặt với một bài toán rất khó nhằn: Dữ liệu vector cực kỳ lớn.
Một tập dữ liệu chứa hàng trăm triệu vector 1536 chiều (như của OpenAI) có thể dễ dàng ngốn hàng trăm GB đến cả TB dung lượng. Nếu nạp toàn bộ vào RAM, chi phí phần cứng sẽ cực kỳ đắt đỏ. Nếu để hết dưới ổ cứng và đọc theo cách truyền thống, tốc độ tìm kiếm sẽ chậm như rùa.
mmap chính là giải pháp dung hòa hoàn hảo cho Qdrant nhờ các lý do sau:
- Phá vỡ giới hạn dung lượng RAM: Nhờ mmap, Qdrant có thể mở các file chứa dữ liệu vector lớn hơn rất nhiều so với dung lượng RAM vật lý hiện có của máy chủ. Có thể chạy một database vector dung lượng 500GB trên một cỗ máy chỉ có 64GB RAM mà ứng dụng không bị crash vì thiếu bộ nhớ.
- Tận dụng tối đa bộ đệm của Hệ điều hành (OS Page Cache): Qdrant không cần phải tự viết code để quản lý việc "khi nào thì nạp vector nào vào RAM, khi nào thì xóa bớt". Hệ điều hành làm việc này tốt hơn bất kỳ ai.
- Tốc độ tìm kiếm tối ưu với Zero-Copy: Khi thực hiện tìm kiếm ANN search trên các cấu trúc index như HNSW, Qdrant cần truy cập ngẫu nhiên vào các điểm dữ liệu rất nhanh. Vì mmap loại bỏ bước copy dữ liệu giữa các vùng bộ nhớ (Zero-copy), CPU có thể đọc trực tiếp các vector từ Page Cache, giúp giảm thiểu độ trễ xuống mức tối đa.
- Thời gian khởi động gần như tức thì
4. Raft
4.1. Raft là gì?
Raft là một thuật toán đồng thuận (consensus algorithm). Nhiệm vụ lớn nhất của nó là giúp một nhóm máy tính làm việc nhịp nhàng với nhau và đồng ý với nhau về một trạng thái dữ liệu duy nhất, ngay cả khi có vài máy trong hệ thống bị sập hoặc mất mạng.
Trước khi có Raft, thế giới dùng Paxos một thuật toán cực kỳ phức tạp và khó hiểu đến mức các kỹ sư thường đùa rằng "chỉ có tác giả mới hiểu được nó". Raft ra đời năm 2014 với mục tiêu tối thượng: Dễ hiểu và dễ cài đặt.
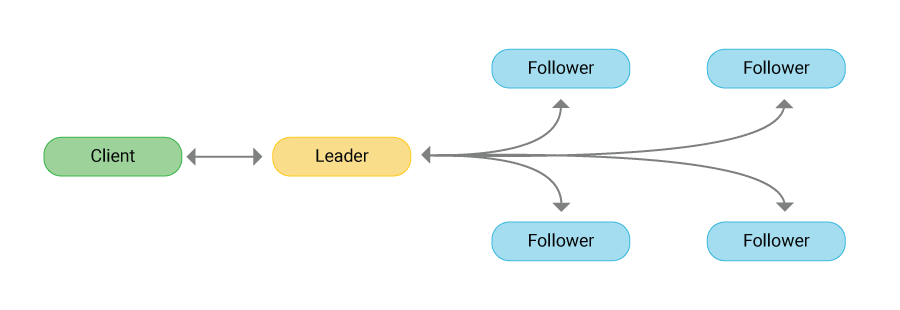
Cách thức hoạt động của Raft:
- Bầu cử Leader: Các máy (node) trong hệ thống sẽ bỏ phiếu để chọn ra một máy làm "Trưởng nhóm" (Leader). Các máy còn lại là "Thành viên" (Follower).
- Mọi việc qua tay Leader: Khi bạn muốn ghi dữ liệu mới, bạn phải gửi cho Leader.
- Đồng bộ dữ liệu: Leader sẽ copy dữ liệu đó gửi cho các Follower. Chỉ khi đa số Follower xác nhận đã nhận (gọi là đạt Quorum), Leader mới chính thức lưu lại và báo thành công cho bạn.
- Tự phục hồi: Nếu Leader hẹo, các Follower sẽ tự động phát hiện và bầu ra một Leader mới trong vài mili-giây.
4.2. Tại sao Qdrant lại dùng Raft?
 Qdrant là một Distributed Vector Database. Khi dữ liệu của quá lớn, không thể nhét hết vào một máy mà phải chia ra nhiều máy khác nhau để quản lý.
Qdrant là một Distributed Vector Database. Khi dữ liệu của quá lớn, không thể nhét hết vào một máy mà phải chia ra nhiều máy khác nhau để quản lý.
Lúc này, Qdrant cần một "ông" để giữ cho toàn bộ hệ thống phân tán này không bị hỗn loạn. Raft chính là giải pháp hoàn hảo vì những lý do sau:
- Quản lý Cluster State đồng nhất: Trong Qdrant, dữ liệu cấu hình hệ thống cực kỳ quan trọng. Ví dụ: Collection này gồm bao nhiêu phân mảnh (shards)? Phân mảnh số 1 đang nằm ở máy nào? Máy số 2 vừa bị sập đúng không?. Mọi máy trong Cluster của Qdrant bắt buộc phải có câu trả lời giống hệt nhau cho những câu hỏi này
- Đảm bảo tính nhất quán cao cho Metadata: Khi tạo mới một Collection hoặc thay đổi cấu hình tìm kiếm, Raft đảm bảo rằng hành động này phải được ghi nhận thành công ở đa số các máy trước khi trả về kết quả
- Khả năng chịu lỗi cao
💡 Lưu ý: Qdrant chỉ dùng Raft cho các thao tác quản trị như tạo/xóa Collection, chuyển đổi vị trí Shard. Đối với dữ liệu Vector thực tế (thao tác Upsert dữ liệu, Tìm kiếm Vector), Qdrant sử dụng một cơ chế tối ưu riêng để đạt hiệu năng cực cao, chứ không bắt tất cả các vector phải đi qua "nút thắt" Raft.
5. Package WAL
5.1. WAL là gì ?
WAL là viết tắt của Write-Ahead Logging. Đây là một kỹ thuật tiêu chuẩn được sử dụng trong hầu hết các hệ quản trị cơ sở dữ liệu hiện đại (như PostgreSQL, SQLite, MySQL...) để đảm bảo tính toàn vẹn của dữ liệu và khả năng phục hồi khi hệ thống gặp sự cố đột ngột (như mất điện, sập nguồn).
5.2. Phân bổ đĩa trước
Việc tạo file mới và cấp phát dung lượng trên đĩa cứng (thông qua các hàm hệ thống như ftruncate hoặc fallocate) là một tác vụ I/O blocking và có độ trễ lớn.
Qdrant thiết kế một luồng chuyên biệt chạy nền tên là wal-segment-creator. Luồng này sẽ tự động tạo và định dạng sẵn các tệp segment rỗng (open-*) với kích thước cấu hình trước segment_capacity.
Khi segment hiện tại bị đầy, WAL chỉ cần hoán đổi cực kỳ nhanh chóng sang một segment đã chuẩn bị sẵn từ hàng đợi bất đồng bộ này, loại bỏ hoàn toàn độ trễ chờ cấp phát không gian đĩa từ luồng xử lý chính.
5.3. Sử dụng Memory-Mapped Files
Thay vì đọc/ghi thông qua các lệnh gọi hệ thống chuẩn vốn tốn chi phí copy dữ liệu giữa user-space và kernel-space, Qdrant ánh xạ trực tiếp các tệp tin WAL vào bộ nhớ thông qua thư viện memmap2.
Khi một segment bị đóng, trên hệ điều hành Linux, thư viện báo hiệu cho hệ điều hành giải phóng bộ đệm trang (page cache) nhằm tiết kiệm dung lượng RAM.
5.4. Flush
Khi một cơ sở dữ liệu như Qdrant nhận dữ liệu mới, nó ghi rất nhanh vào vùng nhớ mmap. Nhưng lúc này, dữ liệu mới chỉ nằm trên RAM (Page Cache). Nếu mất điện đột ngột, dữ liệu sẽ bốc hơi. Để an toàn, hệ thống buộc phải gọi lệnh ép dữ liệu từ RAM xuống ổ đĩa cứng.
Thao tác đẩy dữ liệu xuống đĩa vật lý để đảm bảo tính bền vững (fsync / msync) lại rất chậm. Qdrant hỗ trợ cơ chế flush bất đồng bộ bằng cách đẩy tác vụ flush vùng nhớ mmap cho một luồng riêng thực thi.
5.5. Căn lề bộ nhớ bằng toán tử Bitwise
Để tối ưu hóa tốc độ truy cập bộ nhớ của CPU (đọc các từ dữ liệu aligned luôn nhanh hơn unaligned), các entry trong WAL được thiết kế để luôn căn lề theo ranh giới 8-byte.
fn padding(len: usize) -> usize {
4usize.wrapping_sub(len) & 7
}
Các CPU hiện đại (x86_64, ARM64) là kiến trúc 64-bit. Đường truyền dữ liệu (Data Bus) giữa CPU và RAM được thiết kế để di chuyển cố định 8 byte (64 bit) dữ liệu trong một chu kỳ máy (gọi là 1 Memory Word). Các địa chỉ trên thanh RAM vật lý cũng được phân đoạn sẵn thành các khối liên tiếp bắt đầu tại địa chỉ chia hết cho 8 (0, 8, 16, 24...).
Nếu dữ liệu nằm đúng ranh giới chia hết cho 8, CPU chỉ cần phát 1 lệnh đọc duy nhất là lấy trọn vẹn giá trị.
All rights reserved
