Bên trong Kafka: log segment, page cache và cách nó scale
Kafka không nhanh vì RAM
Một hiểu nhầm phổ biến là hệ thống muốn nhanh thì phải phụ thuộc nhiều vào RAM. Nhưng Kafka lại đi theo hướng ngược lại: tối ưu cho disk, cụ thể là sequential disk I/O.
Trong khi nhiều hệ thống queue truyền thống cố gắng giữ dữ liệu trong memory để giảm latency, Kafka chấp nhận ghi xuống disk ngay từ đầu. Điều này nghe có vẻ chậm, nhưng thực tế lại rất nhanh nếu dữ liệu được ghi theo kiểu tuần tự.
Với disk hiện đại (đặc biệt là SSD), việc ghi tuần tự có throughput rất cao và ổn định. Kafka tận dụng điều này bằng cách biến mọi ghi dữ liệu thành append-only. Không seek ngẫu nhiên, không overwrite, không fragment chỉ đơn giản là ghi nối tiếp.
Kết quả là:
- Throughput cao hơn kỳ vọng
- Latency ổn định
- Không bị phụ thuộc vào memory size
Điểm quan trọng cần hiểu: Kafka không chống lại disk, mà thiết kế để disk trở thành lợi thế.
Log segment: vì sao Kafka không lưu một file duy nhất
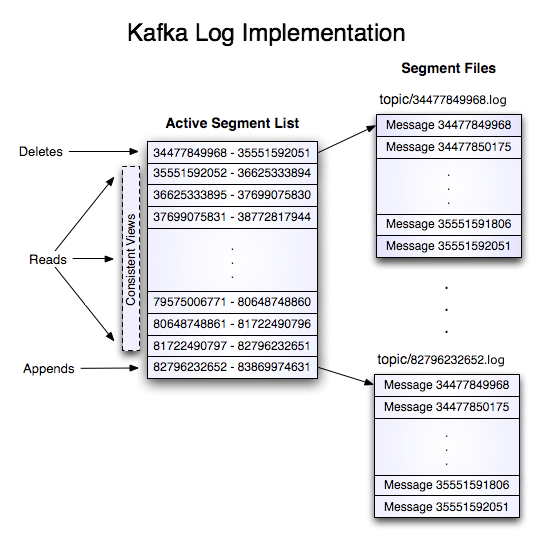 Nếu Kafka chỉ append vào một file duy nhất, file đó sẽ nhanh chóng trở nên khổng lồ và khó quản lý. Đó là lý do Kafka chia log thành nhiều segment nhỏ.
Nếu Kafka chỉ append vào một file duy nhất, file đó sẽ nhanh chóng trở nên khổng lồ và khó quản lý. Đó là lý do Kafka chia log thành nhiều segment nhỏ.
Mỗi partition thực chất là một chuỗi các file:
000000000000.log
000000000100.log
000000000200.log
Mỗi file tương ứng với một khoảng offset nhất định. Khi file hiện tại đạt đến kích thước cấu hình (ví dụ 1GB), Kafka sẽ tạo một segment mới.
Cách làm này mang lại nhiều lợi ích:
- Không cần load toàn bộ log vào memory
- Dễ dàng xóa dữ liệu cũ theo retention policy
- Giúp OS quản lý cache hiệu quả hơn
Quan trọng hơn, segment giúp Kafka giữ được đặc tính append-only nhưng vẫn kiểm soát được kích thước dữ liệu theo thời gian.
Index: Kafka không scan log như bạn nghĩ
 Một câu hỏi thường gặp là: nếu Kafka chỉ là log append, vậy khi đọc dữ liệu nó có phải scan toàn bộ file không?
Một câu hỏi thường gặp là: nếu Kafka chỉ là log append, vậy khi đọc dữ liệu nó có phải scan toàn bộ file không?
Câu trả lời là không.
Kafka duy trì một index riêng cho mỗi segment, ánh xạ giữa offset và vị trí byte trong file. Khi consumer cần đọc từ một offset cụ thể, Kafka sẽ:
- Tìm segment chứa offset đó
- Dùng index để nhảy đến vị trí gần nhất
- Đọc tuần tự từ đó
Điều này giúp Kafka giữ được lợi thế của sequential I/O mà vẫn đảm bảo khả năng truy cập nhanh.
Page cache: Kafka “mượn RAM” từ OS
Kafka không tự quản lý cache phức tạp như nhiều hệ thống khác. Thay vào đó, nó dựa vào page cache của hệ điều hành.
Khi Kafka ghi dữ liệu xuống disk, thực tế dữ liệu sẽ đi qua page cache trước. Điều này tạo ra hai hiệu ứng:
- Ghi dữ liệu nhanh như memory write
- Đọc dữ liệu gần như không chạm disk nếu còn trong cache
Kafka không cần implement caching layer riêng vì OS đã làm rất tốt việc này.
Điểm thú vị là Kafka gần như “đẩy trách nhiệm cache” xuống kernel, và tận dụng tối đa cơ chế sẵn có thay vì reinvent.
Zero-copy: gửi dữ liệu mà không cần copy
Khi consumer fetch dữ liệu, Kafka không đọc file vào user space rồi gửi qua network theo cách truyền thống. Thay vào đó, nó sử dụng cơ chế zero-copy (thường qua sendfile).
Flow truyền thống:
Disk → Kernel → User space → Kernel → Network
Flow của Kafka:
Disk → Kernel → Network
Bằng cách bỏ qua bước copy vào user space, Kafka:
- Giảm CPU usage
- Giảm memory copy
- Tăng throughput network
Đây là một trong những lý do Kafka có thể handle lượng data lớn mà vẫn giữ hiệu năng ổn định.
Partition: scale bằng cách chia nhỏ log
Kafka scale không phải bằng cách tăng sức mạnh của một node, mà bằng cách chia dữ liệu thành nhiều partition.
Mỗi partition là:
- Một log độc lập
- Có thể nằm trên node khác
- Có thể được consume song song
Ví dụ một topic có 10 partition thì có thể có 10 consumer xử lý cùng lúc.
Tuy nhiên, điều này đi kèm một trade-off rõ ràng: Kafka chỉ đảm bảo thứ tự trong từng partition, không đảm bảo global ordering. Vì vậy, việc chọn key partition là quyết định rất quan trọng trong thiết kế.
Replication và ISR: cân bằng giữa consistency và availability
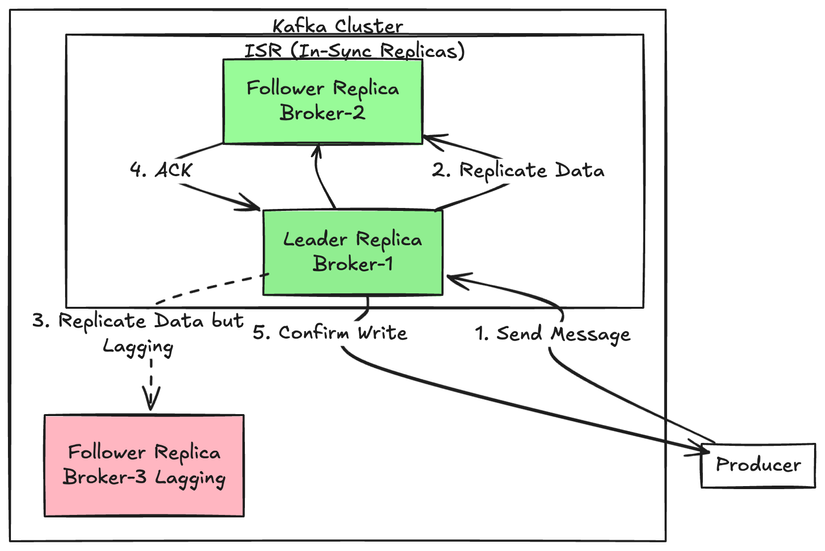 Kafka không chỉ lưu dữ liệu ở một node. Mỗi partition có thể có nhiều replica để đảm bảo fault tolerance.
Kafka không chỉ lưu dữ liệu ở một node. Mỗi partition có thể có nhiều replica để đảm bảo fault tolerance.
Trong các replica đó:
- Leader: xử lý read/write
- Follower: replicate dữ liệu
Kafka duy trì một tập gọi là ISR (in-sync replicas), những replica đang theo kịp leader.
Khi producer gửi dữ liệu với cấu hình acks=all, Kafka sẽ chỉ confirm khi tất cả ISR đã ghi xong. Điều này đảm bảo dữ liệu không bị mất, nhưng cũng làm tăng latency.
Ngược lại, nếu chọn acks=1, hệ thống nhanh hơn nhưng có rủi ro mất dữ liệu khi leader chết.
Đây là một ví dụ điển hình của trade-off trong distributed system:
- Consistency cao → latency cao
- Latency thấp → chấp nhận rủi ro
Vì sao Kafka scale tốt hơn nhiều hệ thống queue?
Khi ghép tất cả lại, ta sẽ thấy Kafka scale tốt không phải vì một yếu tố đơn lẻ, mà vì sự kết hợp:
- Append-only → tối ưu disk I/O
- Segment → quản lý dữ liệu hiệu quả
- Page cache → tận dụng RAM của OS
- Zero-copy → tối ưu network
- Partition → scale ngang dễ dàng
Kafka không cố gắng tối ưu từng phần riêng lẻ, mà thiết kế toàn bộ hệ thống xoay quanh một nguyên lý: log tuần tự + tận dụng tối đa cơ chế của OS.
Kết luận
Kafka không phải nhanh vì nó dùng công nghệ đặc biệt hay phần cứng mạnh. Nó nhanh vì thiết kế của nó phù hợp với cách hệ điều hành và phần cứng hoạt động.
Thay vì chống lại disk, Kafka biến disk thành lợi thế. Thay vì tự quản lý cache, Kafka tận dụng page cache. Thay vì copy dữ liệu nhiều lần, Kafka dùng zero-copy. Và thay vì scale theo chiều dọc, Kafka chia nhỏ dữ liệu để scale ngang.
Khi nhìn Kafka từ bên trong, ta sẽ thấy đây không chỉ là một hệ thống streaming, mà là một ví dụ điển hình của việc thiết kế đúng với bản chất của hệ thống bên dưới.
Và đó cũng là lý do Kafka có thể xử lý lượng dữ liệu rất lớn mà vẫn giữ được hiệu năng ổn định trong các hệ thống production.
All rights reserved
