Bảo vệ dữ liệu trên AWS S3
Bài đăng này đã không được cập nhật trong 5 năm
Tổng quan
AWS Simple Storage Service (AWS S3) là dịch vụ lưu trữ dữ liệu trên mạng Internet. Nó có giao diện web đơn giản, giúp bạn có thể dễ dàng thực hiện lưu trữ và truy xuất dữ liệu ở bất kì thời điểm nào, bất cứ nơi nào. S3 có cấu trúc theo từng bucket, mỗi bucket sẽ chứa nhiều objects. Object có thể là folder hay cũng có thể là các file dữ liệu. Một object có thể có nhiều object con lồng bên trong.
Vì là dịch vụ lưu trữ dữ liệu nên việc bảo mật, bảo vệ dữ liệu của S3 cần phải được đặc biệt quan tâm. Các thông tin cần bảo mật là account để đăng nhập S3, access key, private key, hoặc là quyền truy cập đối với các dữ liệu, .... S3 cung cấp tương đối nhiều phương thức để người sử dụng có thể làm điều này, bạn đọc có thể tham khảo tại link Các cách này thì đều có ưu, nhược điểm riêng, tuy nhiên, chúng đều tương đối dễ dàng để sử dụng, thêm nữa là document của S3 thì lại khá đầy đủ nên việc tích hợp vào hệ thống là không khó. Trong bài viết này mình sẽ nói về một vài phương thức được sử dụng phổ biến.
Versioning
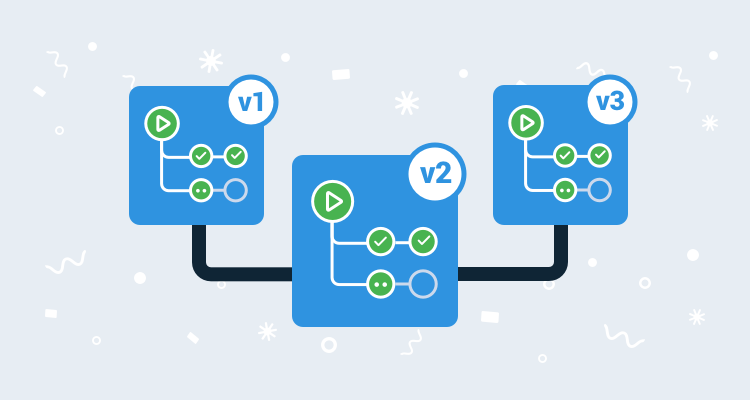
Versioning được hiểu đơn giản là đánh phiên bản (version) cho dữ liệu. Khi gọi request tạo mới thì object được tạo ra, khi gọi request update thì cập nhật object, đấy là flow bình thường. Tuy nhiên, với bucket được cấu hình để có versioning thì với mỗi lần update, object sẽ được tạo mới và đánh phiên bản. Khi có request get thì dữ liệu ở phiên bản mới nhất sẽ mặc định được trả ra. Ngoài ra, bạn có thể lấy object ở version cụ thể bằng cách gọi request get với params là version của object.
Đặc biệt, khi delete thì object sẽ được xử lí như thế nào? Có 2 option xóa object khi sử dụng versioning là đánh dấu đã xóa hoặc xóa thật sự (có thể hiểu là xóa logic và xóa vật lí)
- Khi gọi request đánh dấu xóa (xóa logic) thì object vẫn tồn tại trong S3 nhưng sẽ bị gắn nhãn xóa (delete marker), mọi request gọi đến object này đều bị trả ra lỗi 404 not found. Nếu muốn lấy lại object này thì chỉ đơn giản là gọi lại request để xóa delete marker.
- Khi gọi request xóa thật sự (xóa vật lí) thì object sẽ bị xóa vĩnh viễn khỏi S3 và không thể lấy lại.
Mặc định, request xóa object với bucket cấu hình versioning là xóa logic.
Phương pháp này giúp giảm thiểu rủi ro khi mà lỡ gọi request không đúng, làm object bị overwrite hoặc bị xóa thì có thể khôi phục lại. Tuy nhiên, nhược điểm của phương pháp này là sẽ tạo ra rất nhiều S3 object cần phải lưu trữ.
Access control

Access control có nghĩa là quản lí quyền truy cập. Tức là cung cấp quyền truy cập khác nhau với các tài khoản khác nhau. Ví dụ như chỉ có tài khoản root mới có thể thay đổi dữ liệu (update, create, delete), còn các tài khoản thường (hay còn gọi là IAM user) sẽ chỉ có quyền đọc. Hoặc là chỉ định một nhóm user có quyền đọc ghi dữ liệu ở một bucket cụ thể.
Với mỗi request gửi lên, S3 sẽ kiểm tra xem user nào là người gọi request, bucket nào được sử dụng, object nào được tương tác, kiểu tương tác là đọc, ghi, xóa hay cập nhật. Sau đấy, nó sẽ gộp tất cả thông tin trên lại với nhau để xử lí và trả ra response phù hợp: là lỗi hay là thực thi request.
Phương pháp này giúp giảm thiểu rủi ro khi mà user cố tình tương tác với dữ liệu không nằm trong phạm vi kiểm soát của mình. Nó đặc biệt hữu ích với các hệ thống lớn, thông tin cần được bảo mật giữa các service trong hệ thống.
Logging and monitoring

Hiểu đơn giản thì đây là log và giám sát hệ thống. Logging and monitoring là điều cực kì quan trọng trong việc theo dõi, quan sát các bất thường đã và đang xảy ra với hệ thống, để từ đó người quản trị có thể dự đoán được các vấn đề đã, đang và sẽ xảy ra rồi tìm ra phương hướng giải quyết phù hợp. Khi sử dụng một dịch vụ bất kì nào thì việc xem log và khả năng debug được xem là một trong những vấn đề cần được quan tâm. Với S3 thì AWS cung cấp một số giải pháp sau đây:
-
Amazon CloudWatch Alarms: nguời quản trị ước chừng phạm vi cho một vài chỉ số nào đó, có thể là chỉ số về số byte của bucket, số object trong một bucket, số request get, số request post, số request bị lỗi (4xx, 5xx) ... Khi phạm vi ngưỡng này bị vượt quá thì sẽ có notification được gửi đến cho người quản trị (thông thường là mail). Vì thế, họ sẽ được cảnh báo nếu dung lượng của bucket quá lơn, số lượng request tăng đột biến, ... Một điều chú ý là Amazon CloudWatch Alarms không thể ngăn chặn hay từ chối xử lí action khi vượt quá ngưỡng, nó chỉ mang ý nghĩa đơn thuần là cảnh báo.
-
AWS CloudTrail Logs: ghi log cho các request mà gọi API để thay đổi object, bucket, tức là các request gọi API để create, update, delete. Các thông tin được ghi log là người tạo request, đối tượng request đến, action là gì, thời gian tạo request.
-
Amazon S3 Access Logs: các nội dung được ghi log tương tự như CloudTrail Logs, nhưng điểm khác biệt là các request gọi API get cũng được log. Hơn thế nữa, nó có thể log lại các thao tác mà không phải tạo ra bởi API, tức là các thao tác trên web browser.
-
AWS Trusted Advisor: tự động tính toán để đưa ra hướng tối ưu cho người quản trị về mặt giá tiền, cách tối ưu hệ thống, lỗ hổng bảo mật dựa trên các thông tin:
+ Log của các buckets + Kiểm tra bảo mật của các bucket mà có quyền truy cập mở + Kiểm tra khả năng phục hồi lỗi cho các bucket mà không bật chế độ versionning
Data encryption

Để tránh việc lưu trữ dữ liệu thô nguyên bản, gây nguy cơ lộ thông tin thì S3 cung cấp phương thức mã hóa dữ liệu. Cách thức hoạt động cơ bản của mã hóa (encryption) đều là dùng key và thuật toán mã hóa để từ chuỗi dữ liệu ban đầu sẽ thành chuỗi dữ liệu được mã hóa. Vì vậy, vấn đề cần quan tâm mỗi khi mã hóa là nên sử dụng thuật toán nào và nên lưu key ở đâu.
S3 có 2 cách chính để mã hóa dữ liệu, đó là mã hóa tại local (client-side encryption) hoặc là mã hóa tại S3 (server-side encryption). Chi tiết bạn đọc có thể tham khảo tại link
Với client-side encryption thì việc mã hóa sẽ diễn ra ở máy của end user hoặc server trung gian nào đó, sau đấy, dữ liệu đã được mã hóa sẽ đẩy lên S3 và lưu trữ ở đấy. Quá trình truy xuất dữ liệu sẽ diễn ra ngược lại, S3 object sẽ được trả ra theo request, khi client nhận được thì sẽ dùng key và thuật toán giải mã để giải mã object và nhận lại là dữ liệu. Thuật toán hay key lúc này đều do phía client tự quyết định, tự tích hợp, thế nên sẽ làm gia tăng nhân lực và thời gian, bù lại sẽ giúp client chủ động hơn, không bị phụ thuộc vào service bên ngoài.
Với server-side encryption thì dữ liệu nguyên bản sẽ được đẩy lên S3, S3 sẽ tự dùng thuật toán và key (được người quản lí thiết lập hoặc S3 quản lí) để mã hóa dữ liệu và cuối cùng là lưu vào thành các object. Khi có request để lấy object về thì sẽ phải kèm theo cả key mã hóa và S3 sẽ tiến hành giải mã và trả ra dữ liệu nguyên bản cho client. Vì mã hóa trên S3 nên người quản lí sẽ lựa chọn thuật toán nằm trong danh sách thuật toán mà S3 có thể xử lí (tương đối nhiều). Điều này làm độ yên tâm sẽ tăng cao hơn, vì dù gì một service to như vậy thì lỗ hổng về bảo mật sẽ rất ít, và gần như là không có. Chưa kể là nhân lực để tích hợp cách này vào hệ thống cũng sẽ giảm đáng kể. Tuy nhiên thì không có gì là miễn phí cả, S3 sẽ thu phí dựa trên số lượng object lưu trữ.
Với xu hướng hiện nay là quản lí tập trung, thêm nữa là chi phí cho server-side encryption của S3 cũng không quá đắt đỏ nên việc sử dụng phương thức này đang được ưu chuộng hơn là client-side encryption.
Kết
Bài viết nêu tóm tắt về một vài phương thức đang được sử dụng để quản lí, bảo mật dữ liệu lưu trữ trên s3 được hiệu quả và an toàn hơn. Tùy vào từng hoàn cảnh cụ thể về chi phí, về lợi ích mà bạn đọc hãy cân nhắc và sử dụng cách thức phù hợp.
Thank you!
All rights reserved
