[Bàn tiếp về Crawling] Quét dữ liệu bất động sản bằng Python
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Các website bất động sản hàng đầu thế giới là một kho dữ liệu quý hiếm cung cấp các thông tin, giá trị cũng như người dùng rất lớn. Bất kỳ cơ sở dữ liệu của website nào về bất động sản tại Hoa Kỳ cũng đều có thể chứa ~100 triệu thông tin về các hộ gia đình. Những thông tin căn hộ này bao gồm các dữ liệu về mua bán, cho thuê hoặc thâm chí những ngồi nhà không còn đăng ký trên thị trường ( đã được sang nhượng hoặc cho thuê ). Các dữ liệu này cũng cung cấp một tính toán về tiền thuê đối với các tài sản ( cụm từ chuyên môn : Zestimates). Việc này giúp cho các chủ sở hữu cũng như khách hàng lập các kế hoạch tốt hơn đối với việc ước tính các giá trị bất động sản tại thời điểm hiện tại.
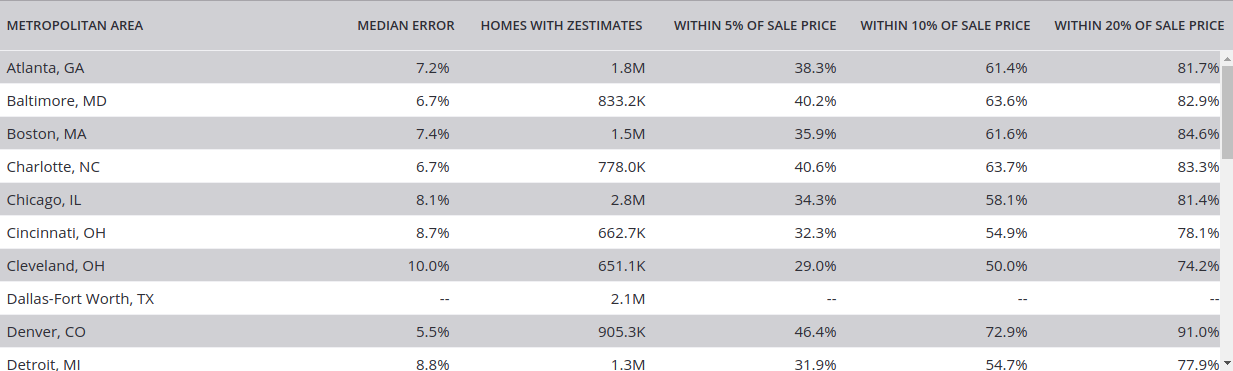
Khi bàn về việc mua hoặc cho thuê các bất động sản, việc đầu tiên khách hàng hay quan tâm là giá trị thuê của sản phẩm tương đương xung quanh vị trí cần thuê, cũng như các thông tin cơ bản của bất động sản đó ( số phòng, kích thước, mô tả, hình ảnh v...v...).
Tại sao phải Crawling dữ liệu từ các trang website bất động sản
Các dữ liệu giống như nguồn sống của các công ty, việc sử dụng dữ liệu linh hoạt hiệu quả mới tạo được nguồn thu lợi nhuận khổng lồ. Nhất là đối với lĩnh vực bất động sản, việc có lượng dữ liệu về khách hàng cũng như nguồn hàng mới nhất và chính xác luôn hỗ trợ giao dịch thành công. Một mô hình Machine Learning dự đoán giá dựa vào các thuộc tính xung quanh của Zestimates ™ của Z.60 chính là dựa vào việc crawling dữ liệu và áp dụng một mô hình phân tích thời gian thực để tạo ra giá trị thực.
Thiết lập Scrape đơn giản:
#import all the required modules
import re
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
import sys
import warnings
from requests_html import HTMLSession
#declare a session object
session = HTMLSession()
#ignore warnings
if not sys.warnoptions:
warnings.simplefilter("ignore")
url_array=[] #array for urls
asin_array=[] #array for asin numbers
with open('asin_list.csv', 'r') as csvfile:
asin_reader = csv.reader(csvfile)
for row in asin_reader:
url_array.append(row[0]) #This url list is an array containing all the urls from the excel sheet
#The ASIN Number will be between the dp/ and another /
start = 'dp/'
end = '/'
for url in url_array:
asin_array.append(url[url.find(start)+len(start):url.rfind(end)]) #this array has all the asin numbers
#declare the header.
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'
}
all_items=[] #The final 2D list containing prices and details of products, that will be converted to a consumable csv
for asin in asin_array:
item_array=[] #An array to store details of a single product.
amazon_url="https://www.amazon.com/dp/"+asin #The general structure of a url
response = session.get(amazon_url, headers=headers, verify=False) #get the response
item_array.append(response.html.search('a-color-price">${}<')[0]) #Extracting the price
#Extracting the text containing the product details
details=(response.html.search('P.when("ReplacementPartsBulletLoader").execute(function(module){ module.initializeDPX(); }){}</ul>;
')[0])
details_arr=[] #Declaring an array to store individual details
details=re.sub("\n|\r", "", details) #Separate the details from text
details_arr=re.findall(r'\>(.*?)\<', details) #Store details in the array.
for i,row in enumerate(details_arr):
details_arr[i]=row.replace("\t","") #Remove tabs from details
details_arr=list(filter(lambda a: a != '', details_arr)) #Remove empty spaces.
details_arr=[row.strip() for row in details_arr] #Remove trailing and starting spaces.
#Store the details with the price in the same row
for row in details_arr:
item_array.append(row)
#Append this array to the master-array of items
all_items.append(item_array)
#Convert mmaster array to csv
with open("new_file.csv","w+", encoding="utf-8") as my_csv:
csvWriter = csv.writer(my_csv,delimiter=',')
csvWriter.writerows(all_items)
Thiết lập lấy dữ liệu trên Zillow
#!/usr/bin/python
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
import urllib.error
from bs4 import BeautifulSoup
import ssl
import json
import ast
import os
from urllib.request import Request, urlopen
# For ignoring SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
# Input from user
url = input('Enter Zillow House Listing Url- ')
# Making the website believe that you are accessing it using a mozilla browser
req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})
webpage = urlopen(req).read()
# Creating a BeautifulSoup object of the html page for easy extraction of data.
soup = BeautifulSoup(webpage, 'html.parser')
html = soup.prettify('utf-8')
property_json = {}
property_json['Details_Broad'] = {}
property_json['Address'] = {}
# Extract Title of the property listing
for title in soup.findAll('title'):
property_json['Title'] = title.text.strip()
break
for meta in soup.findAll('meta', attrs={'name': 'description'}):
property_json['Detail_Short'] = meta['content'].strip()
for div in soup.findAll('div', attrs={'class': 'character-count-truncated'}):
property_json['Details_Broad']['Description'] = div.text.strip()
for (i, script) in enumerate(soup.findAll('script',
attrs={'type': 'application/ld+json'})):
if i == 0:
json_data = json.loads(script.text)
property_json['Details_Broad']['Number of Rooms'] = json_data['numberOfRooms']
property_json['Details_Broad']['Floor Size (in sqft)'] = json_data['floorSize']['value']
property_json['Address']['Street'] = json_data['address']['streetAddress']
property_json['Address']['Locality'] = json_data['address']['addressLocality']
property_json['Address']['Region'] = json_data['address']['addressRegion']
property_json['Address']['Postal Code'] = json_data['address']['postalCode']
if i == 1:
json_data = json.loads(script.text)
property_json['Price in $'] = json_data['offers']['price']
property_json['Image'] = json_data['image']
break
with open('data.json', 'w') as outfile:
json.dump(property_json, outfile, indent=4)
with open('output_file.html', 'wb') as file:
file.write(html)
print ('----------Extraction of data is complete. Check json file.----------')
Chạy tập lệnh được lưu lại
python propertyScraper.py
Dữ liệu giả lập: LINK
Dữ liệu được crawling demo
{
"Details_Broad": {
"Number of Rooms": 4,
"Floor Size (in sqft)": "1,728"
},
"Address": {
"Street": "638 Grant Ave",
"Locality": "North baldwin",
"Region": "NY",
"Postal Code": "11510"
},
"Title": "638 Grant Ave, North Baldwin, NY 11510 | MLS #3137924 | Zillow",
"Detail_Short": "638 Grant Ave , North baldwin, NY 11510-1332 is a single-family home listed for-sale at $299,000. The 1,728 sq. ft. home is a 4 bed, 2.0 bath property. Find 31 photos of the 638 Grant Ave home on Zillow. View more property details, sales history and Zestimate data on Zillow. MLS # 3137924",
"Price in $": 299000,
"Image": "https://photos.zillowstatic.com/p_h/ISzz1p7wk4ktye1000000000.jpg"
}
{
"Details_Broad": {
"Number of Rooms": 4,
"Floor Size (in sqft)": "1,728"
},
"Address": {
"Street": "638 Grant Ave",
"Locality": "North baldwin",
"Region": "NY",
"Postal Code": "11510"
},
"Title": "638 Grant Ave, North Baldwin, NY 11510 | MLS #3137924 | Zillow",
"Detail_Short": "638 Grant Ave , North baldwin, NY 11510-1332 is a single-family home listed for-sale at $299,000. The 1,728 sq. ft. home is a 4 bed, 2.0 bath property. Find 31 photos of the 638 Grant Ave home on Zillow. View more property details, sales history and Zestimate data on Zillow. MLS # 3137924",
"Price in $": 299000,
"Image": "https://photos.zillowstatic.com/p_h/ISzz1p7wk4ktye1000000000.jpg"
}
Link trích dẫn chi tiết bài viết: Link
All rights reserved
