Bài 4: Unsupervised learning
Trong bài trước, bạn đã thấy unsupervised learning (học không giám sát) là gì, và một dạng của nó gọi là clustering (phân cụm).
Bây giờ, chúng ta sẽ đưa ra một định nghĩa chính thức hơn một chút về học không giám sát và xem qua một số dạng khác ngoài phân cụm.
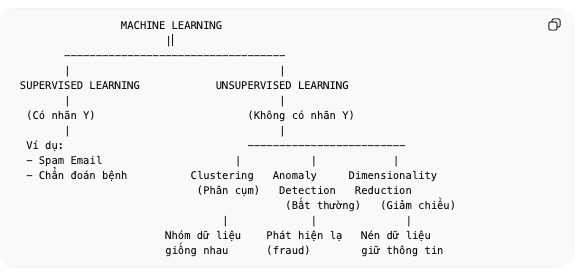
Trong supervised learning (học có giám sát), dữ liệu bao gồm:
Đầu vào (X) Nhãn đầu ra (Y)
Còn trong unsupervised learning, dữ liệu chỉ có:
Đầu vào (X) ❌ Không có nhãn (Y)
➡️ Nhiệm vụ của thuật toán là:
Tìm ra cấu trúc Hoặc mẫu (pattern) Hoặc điều gì đó thú vị trong dữ liệu
Chúng ta đã thấy một ví dụ là clustering (phân cụm): 👉 Nhóm các điểm dữ liệu giống nhau lại với nhau
Trong khóa học này, bạn sẽ học 3 loại chính của unsupervised learning:
- Clustering (Phân cụm) Nhóm dữ liệu tương tự lại
- Anomaly Detection (Phát hiện bất thường) Phát hiện các sự kiện lạ Ứng dụng: Phát hiện gian lận tài chính 💳 Giao dịch bất thường → có thể là lừa đảo
- Dimensionality Reduction (Giảm chiều dữ liệu) Nén dữ liệu lớn thành dữ liệu nhỏ hơn Nhưng vẫn giữ được nhiều thông tin nhất có thể
👉 Nếu bạn chưa hiểu rõ 2 phần này, đừng lo — sẽ học sau.
🧠 Câu hỏi kiểm tra hiểu bài
Hãy phân loại các ví dụ:
✔️ Unsupervised Learning: Google News (nhóm tin tức) → clustering Market Segmentation (phân khúc khách hàng) ✔️ Supervised Learning: Spam email (có nhãn spam / không spam) Chẩn đoán bệnh tiểu đường (có nhãn có / không bệnh)
All rights reserved
