AWS Redshift
Bài đăng này đã không được cập nhật trong 10 năm
Xin chào tất cả các bạn  )
Trong bài viết trước mình đã đưa ra một bài toán nhỏ để so sánh tốc độ query giữa MongoDB và Redshift. Và các bạn cũng đã thấy được tốc độ query rất khủng khiếp của Redshift trước MongoDB. Ở bài viết này mình sẽ giới thiệu với các bạn về cấu trúc của Redshift, cách mà Redshift thực hiện các câu query để hiểu tại sao Redshift lại có khả năng ghê gớm đến vậy.
)
Trong bài viết trước mình đã đưa ra một bài toán nhỏ để so sánh tốc độ query giữa MongoDB và Redshift. Và các bạn cũng đã thấy được tốc độ query rất khủng khiếp của Redshift trước MongoDB. Ở bài viết này mình sẽ giới thiệu với các bạn về cấu trúc của Redshift, cách mà Redshift thực hiện các câu query để hiểu tại sao Redshift lại có khả năng ghê gớm đến vậy.
1. Kiến trúc hệ thống tổng quát
Đầu tiên chúng ta sẽ đi vào kiến trúc hệ thống của Redshift. Dưới đây là hình vẽ mô tả về kiến trúc của Redshift.
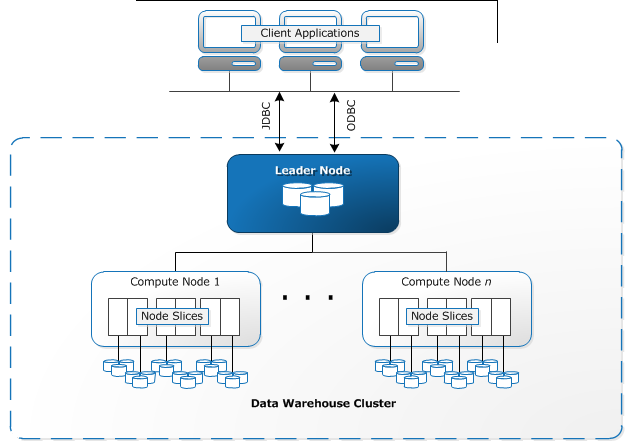
Client Application và Connection
Amazon Redshift được xây dựng dựa trên PostgreSQL với chỉ một chút thay đổi. Do đó nếu ứng dụng của bạn đang sử dụng SQL, chỉ cần vài thay đổi nhỏ thì bạn đã có thể chuyển sang Redshift. Những điểm khác nhau giữa PostgreSQL và Redshift bạn có thể tìm hiểu ở link sau đây.
Vì được xây dựng dựa trên PostgreSQL nên Redshift hỗ trợ việc kết nối giữa application và hệ thống qua JDBC and ODBC drivers.
Cluster
Bây giờ chúng ta sẽ đi sâu hơn vào cấu trúc của Redshift. Thành phần core trong kiến trúc của Redshift là Cluster. Trong Cluster sẽ có một hoặc nhiều Database. Để truy câp vào Cluster bạn sẽ cần đường link cửa cluster , tên database và password. Mỗi cluster sẽ được tạo thành bởi 1 hay nhiều Node. Khi Cluster được tạo nên bởi nhiều Node thì Redshift sinh thêm Leader Node.
Leader Node
Nhiệm vụ đầu tiên của Leader Node là kết nối với application để nhận query cũng như trả kết quả. Nhiệm vụ thứ 2 là xử lý, truyền query excution plan tới từng Compute Node. Đồi với những câu lệnh query phức tạp thì Leader Node còn truyền xuống các Compute Node các bước query và chính Leader Node tổng hợp kết quả trả về từ Compute Node để có thể ra được kết quả. Như vậy bước xử lý câu query và tổng hợp kết quả được thực hiện quả Leader Node còn thực hiện nó thì sẽ là ở các Node con.
Compute Node
Compute Node chính là nơi thực hiện các câu lệnh query sau đó trả kết quả lại cho Leader Node tổng hợp lại. Điểm đặc biệt ở đây chính là mỗi Compute Node sẽ có CPU, Memory và Storage cho riêng mình. Cấu hình cụ thể sẽ tùy thuộc vào Plan mà bạn chọn khi tạo Cluster. Ví dụ nếu dữ liệu của bạn cực kì khủng khiếp thì bạn có thể chọn cho mình max là 36 vCPU, 244Gb Memory và 16TB Storage (hihi). Bạn có thể tham khảo link dưới đây cho cấu hình từng Cluster và Node:
https://aws.amazon.com/redshift/pricing/
Node Slices
Mỗi một Compute Node tiếp tục được chia nhỏ ra thành các Node Slice. Mỗi một Node Slice sẽ được phân chia đều CPU, Memory và Storage từ Compute Node đó. Với 1 query mà Compute Node nhận được từ Leader Node, Compute Node tiếp tục truyền xuống cho từng Node Slice để các Slice này thực hiện đồng thời query.
Internal network
Thành phần cuối cùng là Internal network. Redshift sử dụng một hệ thống private network với băng thông rộng, tốc độ cao để có thể kết nối giữa Leader Node và Compute Node. Đây là thành phần bảo đảm truyền query từ Leader Node tới Compute Node và truyền kết quả từ Compute Node tới Leader Node. Đây cũng là một thành phần rất quan trọng ảnh hưởng đến thời gian query mà mình sẽ giới thiệu đến các bạn sau này.
2. Lưu trữ dữ liệu
Distribution Style
Tiếp theo mình sẽ nói một chút về việc lưu trữ dữ liệu của Redshift. Như ở trên mình đã nói đến cấu trúc nhỏ nhất trong Redshift là các Node Slices và data của bạn được lưu trữ trên node slices này. Vậy thì Redshift phân bổ data đến các Node Slices như thế nào.
Khi bạn tạo bảng thì sẽ có trường bạn nên khai báo là Distribution Key. Distribution Key là một column trong bảng của bạn, và Redshift sẽ sử dụng giá trị của column này để phân chia data đến node slices tương ứng. Hiểu nôm na ví dụ bạn chọn distribution key là cột date. Thì những bản ghi có data là ngày 2016-04-24 sẽ ở trên cùng một node slice, hoặc trên cùng một node nếu như số lượng bản ghi có date là ngày 2016-04-24 quá nhiều... Việc phân bố cũng như lưu trữ xem node nào, nodes slice nào lưu trữ giá trị nào được quyết định và lưu trữ bởi Leader Node.
Ví dụ khi bạn query là date BETWEEN 2016-04-24 and 2016-04-25 , leader node thấy với những date là 2016-04-24 và 2016-04-25 thì chỉ được lưu ở node 1 và node 2. Khi đó thì query sẽ chỉ được 2 node này thực hiện. Qua đó tránh việc phải xử lý lượng dữ liệu không cần thiết. Do đó việc chọn Distribution Key là cực kì quan trọng khi thiết kế table.
Columnar Data Storage
Columnar Data Storage hiểu đơn giản là lưu trữ dữ liệu theo cột. Đây là một trong những yếu tố cực kì quan trọng giúp cho việc giảm đi một lượng cực kì lớn I/O requirements và lượng dữ liệu phải load trong quá trình query.
Cấu trúc lưu data kiểu truyền thống là lưu theo row (row-wise database storage) như bạn thấy dưới đây.
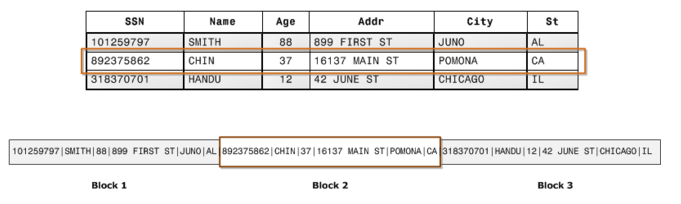
Mỗi một block sẽ lưu data của cả 1 row. Nghĩa là nếu mà row size lớn hơn block size thì bạn sẽ cần nhiều hơn 1 block để lưu data, còn nếu như row size nhở hơn block size thì trên 1 block sẽ lưu data của ít nhât 2 row. Kiểu lưu này phù hợp với những application là online transaction processing (OLTP). Ở những application kiểu này thì việc đọc và ghi liên quan đến toàn bộ dữ liệu hoăc chỉ là 1 lượng nhỏ dữ liệu. Do đó việc phải đọc và ghi qua bao nhiêu block không cần phải tối ưu vì bạn hoặc là xử lý trên toàn bộ block, hoặc chỉ cần xử lý trên 1 lượng block nhỏ.
Redshift sử dụng Columnar Data Storage, lưu theo cột để lưu dữ liệu như ban thấy dưới đây.
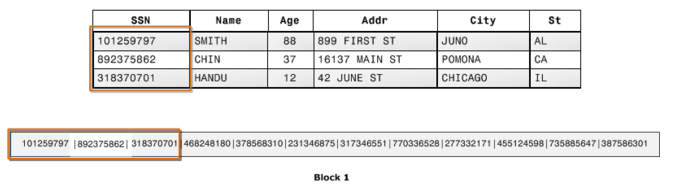
Như bạn thấy, thì trên 1 block thay vì lưu cả 1 row thì sẽ lưu theo cột. Tất nhiên trong bài viết này mình sẽ không đi sâu vào so sánh giữa Columnar Storage và Row-Wise Storage (chắc là sẽ có một bài riêng cho phần này (hihi)). Ở đây mình chỉ nói về điểm mạnh của Columnar Data Storage là:
- Khả năng query cực kì mạnh mẽ khi phải query lượng dữ liệu lớn.
- Khả năng nén dữ liệu rất cao, qua đó giảm được lượng dữ liệu phải xử lý.
- Tốc độc query rất tốt nếu như chỉ liên quan đến một hay một vài cột trong bảng.
Column được lưu trên block theo thứ tự nào thì tùy thuộc vào Sort Key mà bạn khai báo khi tạo bảng.
3. Perfomance
Quay trở lại với vấn đề chính là tại sao Redshift có thể có tốc độ query cực kì tốt với lượng dữ liệu lớn. Thì có lẽ qua phần giới thiệu về system của Redshift các bạn cũng có thể đoán ra được phần nào. Dưới đây là những lý do chính.
Massively parallel processing
Với cấu trúc chia nhở data vào các compute node, các compute node lại được chia nhỏ thành các node slices. Và các node slices lại được cấp CPU, Memory, Storage để xử lý dữ liệu song song thì hiển nhiên là tốc độ query sẽ nhanh hơn rất nhiều. Ví dụ như bạn chọn cluster là ds1.xlarge với max node có thể là 32, mỗi node có max là 2 slices, thì với 64 process xử lý query song song hiển nhiên là nhanh hơn so với 1 process. Con số này sẽ còn khủng khiếp hơn khi sử dụng cluster dc1.8xlarge với tối đa 128 nodes và max là 32 slices trên 1 node (tất nhiên là nếu chọn con này thì bạn tốn lượng tiền lớn rồi (hihi)).
Columnar data storage
Như đã nói ở trên thì lưu dữ liệu theo cột sẽ tốn ít I/O và lượng dữ liệu phải load hơn. Columnar data storage cực kì hữu dụng nếu data của bạn cực kì lớn. Đây cũng là một trong những lý do chính giúp Redshift có tốc độ query rất nhanh khi so sánh vs MongoDB ở bài trước của mình.
Data Compression
Với kiểu lưu theo Columnar Data Storage thì Redshift cũng gây ấn tượng mạnh với khả năng nén dữ liệu. Với table có 8.5 triệu bản ghi như của mình, nếu như ở MongoDB lượng dữ liệu chiếm là 4.5Gb thì ở Redshift chỉ gần 1Gb, điều đó giúp cho lượng dữ liệu phải xử lý giảm đi rất rất nhiều qua đó tăng cao được performance. Redshift cung cấp rất nhiểu kiểu encode cho dữ liệu của bạn như raw, byte, delta, lzo... để bạn lựa chọn, qua đó nén một cách tối ưu nhất dữ liệu của mình.
Query Optimizer
Phân Engine xử lý query của Redshift có khả năng tối ưu hóa query với việc sử dụng (MPP-aware (Massive Parallel Processing))[https://en.wikipedia.org/wiki/Massively_parallel_(computing)] và những lợi thế có được từ Columnar data storage. Khi nhận được query thì Engine sẽ chuyển query plan thành code và sau đó chuyển code đó đến Compute Node để thực hiện. Để có thể hiểu rõ hơn về query plan cũng như flow thực hiện bạn có thể tham khảo link sau đây:
http://docs.aws.amazon.com/redshift/latest/dg/c-query-processing.html
Ngoài ra Redshift còn cung cấp cho bạn 1 loạt các bảng có sắn để bạn có thể phân tích flow của query qua đó giúp bạn cải thiện câu query. Ví dụ như bảng SVL_QUERY_SUMMARY cung cấp cho bạn thống kê query theo stream, bảng SVL_QUERY_REPORT cung cấp cho bạn thông tin query theo Node Slice, hay STL_ALERT_EVENT_LOG lưu trữ những thông báo mà nó ảnh hưởng đến performance của query... Bạn có thể tham khảo về cách phân tích, cách cải thiện câu query theo như link dưới đây:
http://docs.aws.amazon.com/redshift/latest/dg/c-query-tuning.html
4. Kết luận
Trong bài viết này mình đã giới thiệu cho các bạn về hệ thống của Redshift cũng như giải thích được phần nào lý do tại sao Redshift có hiệu năng cực kì tốt. Tuy nhiên để có thể sử dụng được một cách tốt nhất toàn bộ hiệu quả của Redshift thì cần sẽ có những tips riêng, nhất là đối với phần thiết kế bảng.
Trong bài tiếp theo mình sẽ giới thiệu cho các bạn làm thế nào để thiết kế bảng một cách tối ưu trong Redshift. Và đó cũng chính là cách để mình giảm câu query từ 10s xuống còn 4 giây như trong bài trước có nói (hihi).
Xin hẹn gặp lại các bạn ở bài viết sau (chao).
All rights reserved
