Aws Lambda Function: trigger đọc file khi upload file csv lên s3 xử lý và lưu vào postgres
Bài đăng này đã không được cập nhật trong 2 năm
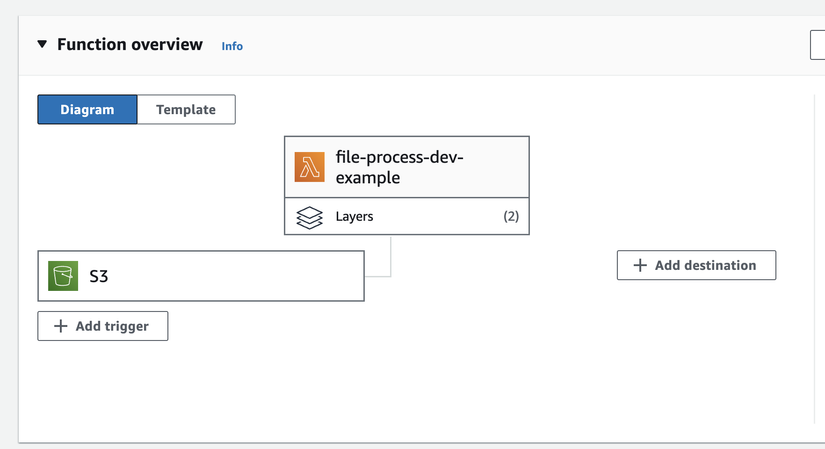 Có nhiều cách trigger File khi upload lên s3 để xử lý như native aws có Glue, nhưng chi phí glue khá mắc và mình cũng developer trên quyết định chọn tự xử lý bằng Lambda trigger.
Đầu tiên chuẩn bị:
Có nhiều cách trigger File khi upload lên s3 để xử lý như native aws có Glue, nhưng chi phí glue khá mắc và mình cũng developer trên quyết định chọn tự xử lý bằng Lambda trigger.
Đầu tiên chuẩn bị:
Python 3.9 AWS Cli EC2 Amazon linux 2
- Tạo IAM Để Lambda có thể lấy file thì mình tạo role tên lambda-role sau đó attach quyền access tới s3
Lưu ý: Nếu các bạn sử dụng vpc thì từ aws lambda không thể connect trực tiếp đến s3 vì s3 là global service
Để kết nối thì mình sẽ sử dụng 1 dịch vụ là VPC Endpoint
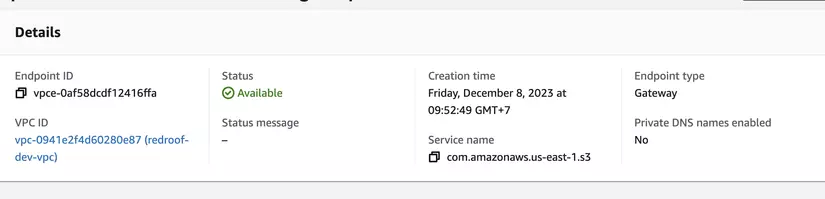 Sau đó attach endpoint đã tạo vào subnet mà bạn muốn
Sau đó attach endpoint đã tạo vào subnet mà bạn muốn
- Tạo Lambda function
import json
import urllib.parse
import boto3
import botocore
import pandas as pd
from io import StringIO
from sqlalchemy import create_engine
from sqlalchemy.types import *
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
try:
s3_client = boto3.client('s3', region_name='your_region',
aws_access_key_id='your_access_key_id',
aws_secret_access_key='your_access_key',
config=botocore.config.Config(s3={'addressing_style':'path'})
)
except Exception as e:
print(e)
raise e
Base = declarative_base()
#
class U_RAW_EXAMPLE_2023(Base):
__tablename__ = "example_table"
id = Column(Integer, primary_key=True)
record_1 = Column(String)
record_2 = Column(Integer)
host = 'your_host'
port = 5443
service_name = 'your_db_name'
user = 'your_user'
password = 'your_password'
sql_driver = 'postgresql'
to_engine: str = sql_driver + '://' + user + ':' + password + '@' + host + ':' + str(port) + '/' + service_name
print(to_engine)
def lambda_handler(event, context):
print("Received event: " + json.dumps(event))
engine = create_engine(
to_engine,isolation_level="AUTOCOMMIT"
)
factory = sessionmaker(bind=engine)
session = factory()
conn = engine.connect()
# Get the object from the event and show its content type
s3_Bucket_Name = event["Records"][0]["s3"]["bucket"]["name"]
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
print("key: " + key)
try:
response = s3_client.get_object(Bucket=s3_Bucket_Name,Key=key)
print("CONTENT TYPE: " + response['ContentType'])
body = response['Body']
csv_string = body.read().decode('utf-8')
dataframe = pd.read_csv(StringIO(csv_string))
print(body)
print(dataframe.head(3))
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
Viết xong code thì chuyển qua phần deployment
- Deploy lambda
Mình sử dụng serverless framework để deploy vì framework này rất tiện dụng và hỗ trợ đầy đủ các chức năng Tạo file serverless.yml với nội dung sau:
service: file-process
frameworkVersion: '3'
plugins:
- serverless-deployment-bucket
custom:
deploymentBuckets:
dev: lambda-bucket
role:
function: arn:aws:iam::{your_id}:role/lambda-role
hooks:
before:package:initialize:
- AWS_REGION={your_region} AWS_LAMBDA_FUNCTION_NAME=${self:service}-${opt:stage, 'dev'} HOST=${self:custom.host.${opt:stage, 'dev'}, ''}
package:
patterns:
- "example.py"
provider:
name: aws
runtime: python3.9
profile: {your_profile}
memorySize: 128
deploymentBucket:
name: ${self:custom.deploymentBuckets.${opt:stage, 'dev'}}
stage: ${opt:stage, 'dev'}
region: ${opt:region, '{your_region}}
vpc:
subnetIds:
- {your_subnet_ids}
securityGroupIds:
- {your_sg_ids}
iam:
role: arn:aws:iam::{your_id}:role/lambda-role
functions:
example:
handler: example.lambda_handler
events:
- s3:
bucket: example
event: s3:ObjectCreated:*
chạy lệnh sls deploy và tận hưởng function
Nào cùng test nào
Các bạn sẽ thấy oh no  ) no module named "pandas"
) no module named "pandas"
để xử lý lỗi này thì phải làm sao
AWS làm sẵn cho chúng ta 1 layer pandas, chỉ cần add layer pandas có sẵn của aws, quá dễ dàng

quay lại tận hưởng thành quả
Các bạn sẽ thấy oh no ) no module named "sqlalchemy"
Lại làm sao vậy
mà aws không làm sẵn layer sqlalchemy thì phải làm sao ạ
Những module liên quan đến cpython sẽ không thuộc native của aws runtime vì vậy chúng ta phải tạo layer hoặc attach vào source lúc deploy
Ở đây mình sẽ tạo layer, lưu ý là phải tạo layer trên ec2 amazon linux 2 thì mới có thể sử dụng cho lambda
mkdir packages \
cd packages \
python3 -m venv venv \
source venv/bin/activate \
mkdir python \
cd python \
pip3 install aws-psycopg2 -t .
pip3 install sqlalchemy -t .
cd ..
zip -r layer-v1.zip python
Để deploy layer lên aws ta dùng lệnh
aws lambda publish-layer-version --layer-name PythonLayer --zip-file fileb://layer-v1.zip --compatible-runtimes python3.9
sau đó attach layer cho lambda function
=> Test và tận hưởng nào
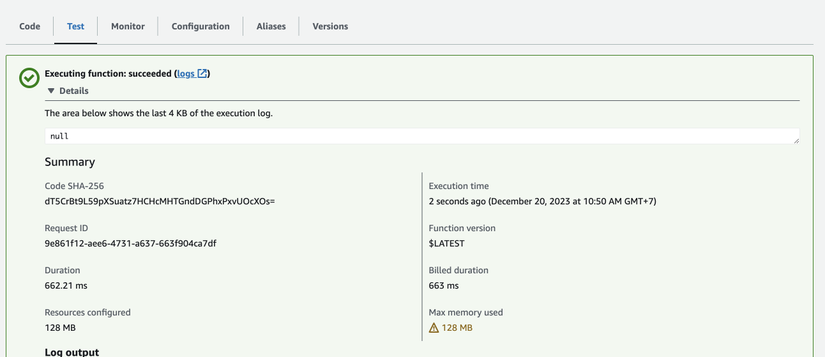
Đây là toàn bộ trải nghiệm, xử lý, có lỗi và fix lỗi của mình, hi vọng sẽ giúp ích được cho anh em khi làm việc.
All rights reserved
