Apache ZooKeeper: Phân tích chuyên sâu kiến trúc và cách sử dụng trong môi trường production ở quy mô hàng triệu người dùng như ZaloPay (Phần 1)
I. Introducing

Disclaimer: this post is a condensed version of our findings and research on ZooKeeper's source code, books, and various other sources. It's possible that some information may not be entirely accurate or may have been previously shared elsewhere. This post is intended solely for sharing and informational purposes.
Distributed systems are fundamentally challenged by the requirement to maintain a consistent state across a cluster of independent nodes. In these environments, the absence of a centralized authority often leads to race conditions, partial failures, and the "split-brain" phenomenon, where different segments of a cluster possess conflicting views of the truth.
Apache ZooKeeper was developed as a foundational solution to these challenges, providing a centralized coordination kernel that enables highly reliable distributed services such as configuration management, naming, synchronization, and group membership. By abstracting the complexities of consensus into a simple, hierarchical API, ZooKeeper allows developers to focus on application logic while the service manages the intricacies of fault tolerance and strict operation ordering
The architectural philosophy of ZooKeeper is predicated on the idea of a high-performance coordination service that favors read-heavy workloads.
It achieves this through a replicated state machine model where every server in the ensemble maintains an i n-memory database of the entire DataTree, which offer reading are served locally,providing exceptional latency and throughput, writes are coordinated through a specialized consensus protocol known as ZooKeeper Atomic Broadcast (ZAB) - this is complicated thing and we will talk as seperated part later.
This dual approach ensures that ZooKeeper can handle thousands of requests per second while maintaining strict ordering guarantees, making it an essential component for the modern data stack, including systems like Kafka, HBase, and Hadoop, and others , .....
II. Transactional Mechanics
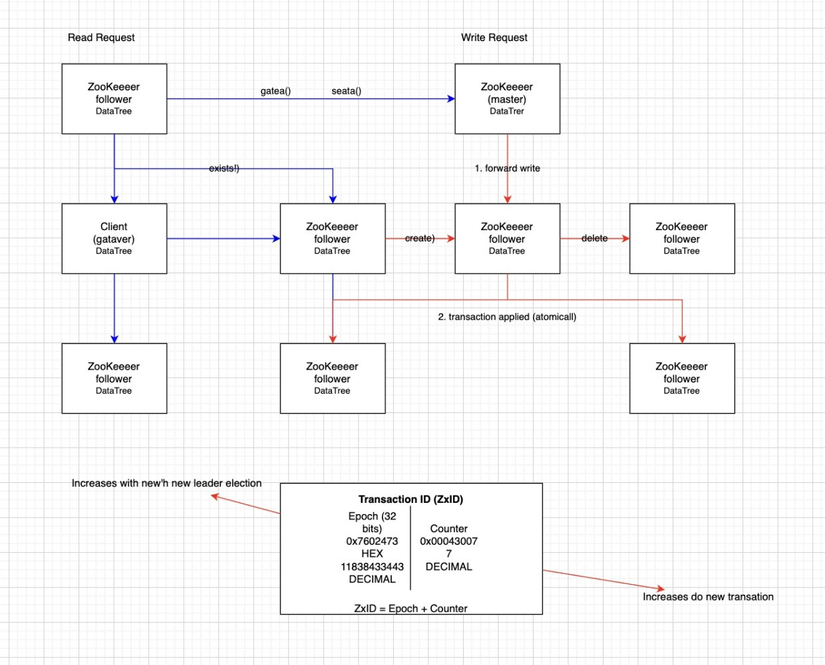
1. Data Flow Patterns
1.1. The read path (local)
The blue arrows on the left represent Read Requests (like getData(), exists(), or getChildren()).
- Local Processing: When a client sends a read request, it can be handled by any server it is connected to (Follower or Observer).
- Scalability: Because the server doesn't need to talk to the Leader to give you data, you can add more servers to the cluster to handle millions of read requests per second.
- Trade-off: This is "eventual consistency." Since a Follower handles it locally, it might be a few milliseconds behind the Leader's latest update.
1.2. The Write Path (concentrus)
The red arrows on the right represent Write Requests (like create(), setData(), or delete()).
- Forwarding: If a client sends a write to a Follower, that Follower must forward it to the Leader (Master).
- Quorum & Consensus: The Leader doesn't just save the data, it proposes a "transaction" to all Followers. Once a majority (quorum) agrees, the Leader commits it.
- Single-Threaded Application: The afraid of being inconsistency with update in multi thread environment -> Make sure each server uses a single thread to apply these changes. This ensures that if Transaction A happened before Transaction B, they are saved in that exact order everywhere.
2. The Anatomy of a ZxID
The box at the bottom explains the ZooKeeper Transaction ID (ZxID). Think of this as a timestamp that never lies. ZxID include two parts:
2.1. The High-Order Bits (Epoch E)
The first 32 bits represent the Epoch. This number increments every time a new Leader takes charge.
- Purpose: It acts as a "term number." Even if a previous leader comes back online, their old transactions will have a lower epoch than the current leader’s transactions.
2.2. The low-order bits (Counter C)
The remaining 32 bits represent the Counter. This increments for every single proposal (transaction) made within a specific epoch.
- Purpose: It provides a strict ordering of events during a single leader's reign. When a new epoch begins, this counter is reset to zero.
By packing the data this way, ZooKeeper achieves two critical goals:
- Total Ordering: Because the Epoch occupies the most significant bits, any ZxID from a newer epoch (ex E=2) will naturally be a larger number than any ZxID from an older epoch (the old one E=1) , regardless of the counter (C) can be still same. Mathematically I can compare for you:
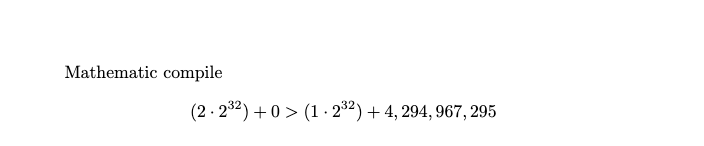
- Comparison Efficiency: Since it is stored as a single 64-bit long, the ensemble doesn't need complex logic to compare versions. A simple if (zxid1 > zxid2) instantly tells the system which state is more recent.
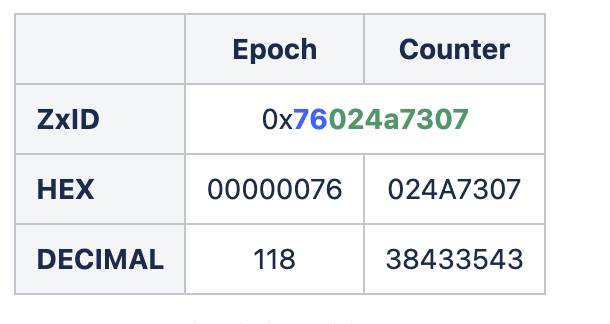
3. Mathematical Ordering
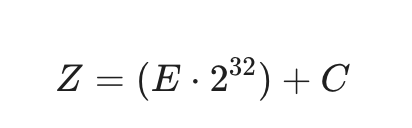
Total ordering is the most critical guarantee provided by ZooKeeper, ensuring that all state changes are applied in the same sequence across all nodes in the ensemble. This is achieved through the ZooKeeper Transaction ID, a 64-bit number that uniquely identifies every proposal.
The ZxID (Z) can be expressed mathematically as:
where E is the epoch and C is the counter. This bit-packing ensures that a simple numerical comparison of two ZxIDs correctly identifies their chronological order across different leadership terms
The use of 2^32 in the ZxID calculation is a practical application of bit manipulation to manage a 64-bit long integer. Think like this, you split the E into two different parts, each part has 32 bit integer, multiplyE by 2^32 equals to left shift E 32 elements (E<<32).
But the critial question is, is it still enough in high-throughput environments ? -> Next section
4. Overflow scenario
I think no, that is when re-election happenning. Because the counter is only a 32-bit integer, it can store approximately 4.2 billion transactions - like a demo above within a single epoch. In extremely high-throughput environments, such as those used by metadata-heavy Flink jobs, the counter may approach its maximum value. When a ZxID overflow is imminent, ZooKeeper proactively triggers a new leader election.
This forces the epoch to increment and resets the counter to zero, preserving the total ordering and preventing different transactions from sharing the same identifier.
III. Quorum Mode and Consensus Dynamics
Ok let's move to next part - consistency  ).
).
1. Concept
To ensure the consistency in a Zookeeper deployment, it is necessary to use the Quorum mode. A ZooKeeper Ensemble consists of a Leader and multiple Followers. The Leader is responsible for processing client update commands, such as create, setData, and delete - read above. These commands are transformed into transactions and proposed to the Followers, which accept and apply them in order.
Waiting for all servers to store their data before proceeding is not efficient. Therefore, a quorum is used, which is the minimum number of servers required to be present for a vote. This number is also the minimum number of servers that must store a client's data before informing the client that it is safely stored. To prevent split-brain - will talk later scenarios, the quorum should be an odd number.
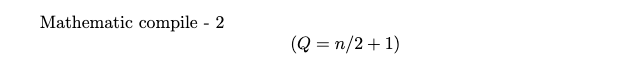
where Q s the required majority. This mathematical constraint provides a specific level of fault tolerance F, easy to see that system willl work in a condition where F = n-Q simultaneous node failures ( related to parittion network failure in SD).

Maintaining an odd number of servers is a critical best practice. An even-numbered cluster (ex 4 nodes) requires the same quorum size (3 nodes) as the next highest odd-numbered cluster (3 nodes), meaning it consumes more resources without providing additional fault tolerance.
2. Split-Brain Prevention
The primary objective of quorum-based voting is the prevention of "split-brain" scenarios. If a network partition divides a 5-node cluster into two segments of 3 nodes and 2 nodes, only the 3-node segment can achieve quorum. The 2-node segment, lacking a majority, will automatically transition to a standby state or reject write requests, ensuring that only one set of consistent updates is applied to the cluster.
But what actually happen with 2-node, how can they know and fix themself ?
At this time, t he system deliberately does not allow minority partitions to continue operating independently. The two isolated nodes do not “know” they are in the minority; they have no global awareness of the cluster topology beyond the connections and heartbeats they can currently observe. Instead, the safety is enforced purely by the mathematical and protocol-level constraints of the ZooKeeper Atomic Broadcast (ZAB) protocol combined with the Fast Leader Election algorithm.
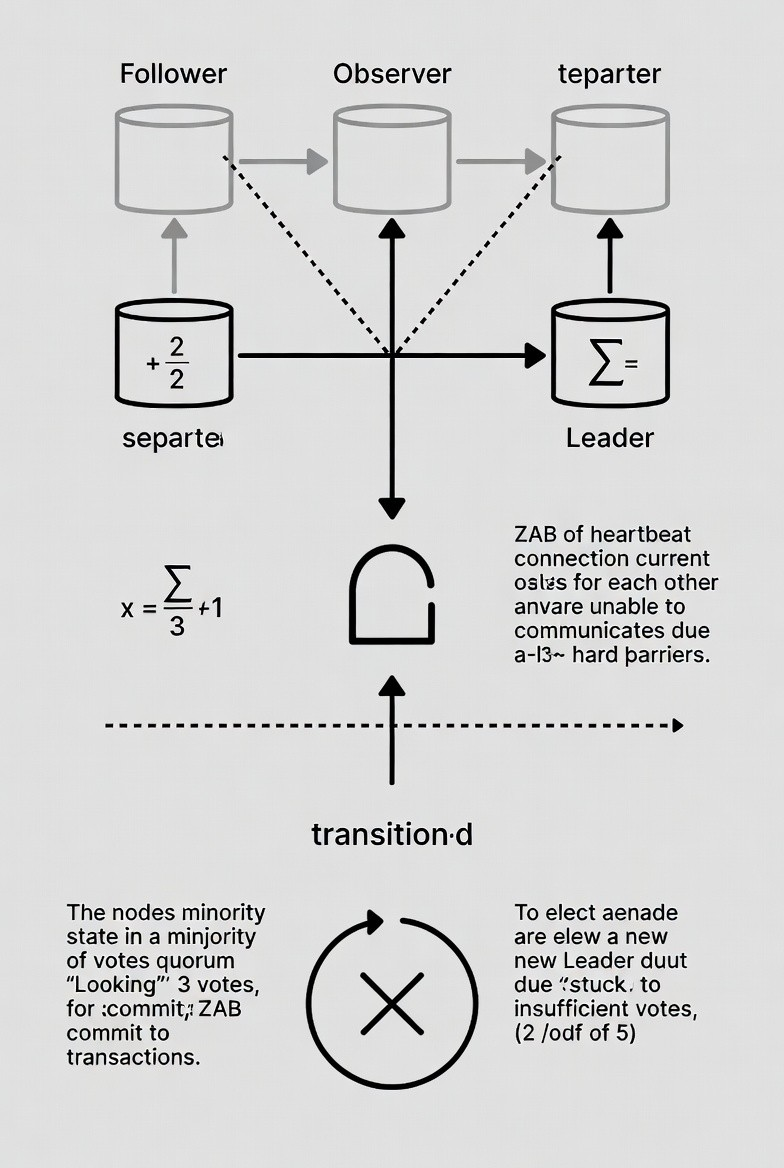
As soon as the partition happens, the two isolated nodes lose their periodic heartbeats (ticks) with the current leader, which resides in the majority partition (the side with 3 nodes). Heartbeat timeouts are governed by the tickTime and syncLimit / initLimit configuration parameters. Once the timeout threshold is crossed, each of the isolated nodes concludes that the current leader is unreachable and transitions into the LOOKING state.
In this state, the node initiates a new leader election round using the Fast Leader Election protocol (the default since ZooKeeper 3.4+).
During the election, each node proposes itself (or the server with the highest zxid/epoch it has seen) as a candidate and broadcasts PROPOSAL messages to all peers it can still reach — in this case, only the other isolated node. Both nodes will vote for each other, resulting in a total of 2 votes. However, the election can only succeed if a candidate receives quorum support, where quorum is defined as more than half of the ensemble size (floor(n/2) + 1). For a 5-node ensemble, quorum = 3.
Since 2 < 3, neither node can gather sufficient votes to declare itself leader. The election round simply fails to produce a winner.
Because no leader is elected, the isolated partition remains permanently in the LOOKING state. Critically, ZAB’s broadcast phase requires a leader to propose transactions, collect acknowledgments from a quorum of followers (again, at least 3 nodes), and only then broadcast a COMMIT message. Without a valid leader, no proposals can be issued, no acknowledgments can be collected from a quorum, and therefore no COMMITs can ever be sent.
This creates a complete deadlock for write operations: the minority side is mathematically incapable of making forward progress.
At the same time, read operations remain possible (locally from the in-memory DataTree), but they are stale and non-authoritative. Any new write attempt sent to these nodes will either be rejected outright or forwarded toward a leader that cannot be reached, eventually timing out. Clients connected to the minority side will experience increasing connection losses, session expirations (if ephemeral znodes are involved), and read-your-writes violations if they switch between partitions.
This behavior is not a bug — it is the core safety invariant of ZooKeeper. By refusing to let a minority partition make any mutations, the protocol guarantees that there can never be two conflicting committed histories (split-brain). Only the partition that contains a quorum can ever elect a leader and continue accepting writes.
Once the network heals and connectivity is restored, the lagging nodes (the previous minority) will perform a full or incremental synchronization (DIFF/SNAP) with the current leader, bringing their DataTree back in line with the authoritative history. During this catch-up phase, they discard any uncommitted proposals they might have optimistically prepared and apply only the transactions that were durably committed by a quorum.
3. Advanced Quorum Configurations
For complex or geographically distributed deployments, ZooKeeper supports specialized quorum models:
- Hierarchical Quorums: This model splits servers into disjoint groups with assigned weights. A quorum is formed by obtaining a majority of votes from a majority of non-zero-weight groups. This configuration enables smaller quorums in wide-area deployments while ensuring that a majority of co-locations must be available to commit changes.
- Oracle Quorums: Designed primarily for 2-instance ensembles, this model utilizes an external "Oracle" (failure detector) to resolve consensus when one node fails. It solves the problem where a 2-node cluster normally requires both nodes to be up (a 100% quorum) to make decisions.
All rights reserved
