Áp dụng Context Caching với Redis để Tối ưu Tốc độ Phản hồi cho Chatbot AI
Khi xây dựng hệ thống chatbot hoặc trợ lý AI, một trong những vấn đề phổ biến là người dùng thường lặp lại cùng một truy vấn. Nếu mỗi lần bot đều phải chạy lại toàn bộ pipeline từ tìm kiếm dữ liệu, gọi LLM, đến sinh câu trả lời hệ thống sẽ chậm và tốn chi phí không cần thiết. Giải pháp ở đây là context caching, và Redis chính là “vũ khí” lý tưởng để thực thi nó.
Context Caching trong Hệ thống AI là gì?
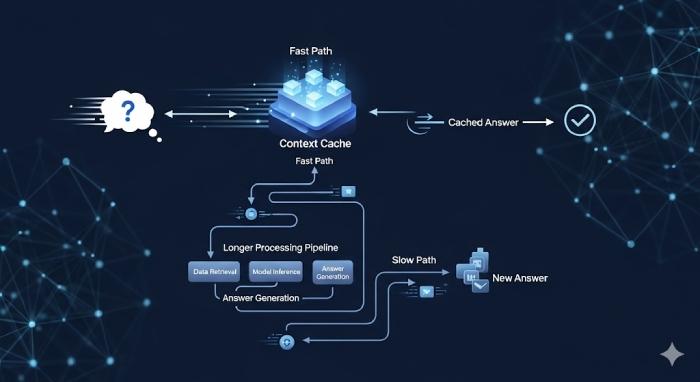
Hiểu đơn giản, context caching hoạt động như một bộ nhớ đệm trung gian. Khi người dùng gửi câu hỏi, hệ thống sẽ:
- Check xem truy vấn đó đã từng được xử lý chưa.
- Nếu có, lấy kết quả ngay từ cache (bỏ qua toàn bộ pipeline).
- Nếu chưa, gọi LLM/pipeline để xử lý rồi lưu lại kết quả cho lần sau.
Cách này đặc biệt hữu ích cho các use case dạng FAQ, tư vấn tự động, hoặc hỗ trợ khách hàng, nơi cùng một câu hỏi được lặp lại hàng trăm lần mỗi ngày.
Vì sao Redis là lựa chọn tối ưu cho Context Cache?
Redis là in-memory key-value store cực nhanh, gần như trở thành chuẩn mặc định cho caching trong hệ thống backend. Một vài lý do khiến Redis “ăn điểm” với dev:
- Latency cực thấp – chỉ vài mili-giây mỗi request.
- TTL (Time To Live) – có thể đặt thời gian sống cho từng key để tránh dữ liệu lỗi thời.
- Hỗ trợ nhiều cấu trúc dữ liệu – string, hash, list, set... rất linh hoạt cho mọi kiểu lưu trữ.
- Tích hợp đơn giản – có client cho Node.js, Python, Go, Java,...
Trong bối cảnh chatbot AI, Redis không chỉ cache session hay token, mà còn có thể cache toàn bộ phản hồi của LLM, giúp giảm độ trễ phản hồi xuống gần như tức thì.
Cách Triển khai Context Caching với Redis
Giả sử bạn có một chatbot hỗ trợ khách hàng trong TMĐT. Các câu hỏi kiểu như “Thời gian giao hàng bao lâu?” hoặc “Chính sách đổi trả thế nào?” là những ứng viên hoàn hảo để cache.
Bước 1: Chuẩn hóa truy vấn thành cache key
Trước khi lưu, cần normalize câu hỏi, viết thường, loại bỏ ký tự đặc biệt, thay dấu cách bằng _:
const normalized = normalizeText(userQuestion);
const cacheKey = `faq:${normalized}`;
Bước 2: Kiểm tra cache trước khi gọi LLM
Nếu dữ liệu đã có, trả về ngay:
const cached = await redis.get(cacheKey);
if (cached) return cached;
Bước 3: Xử lý mới và lưu cache
Nếu chưa có, gọi pipeline/LLM, sau đó lưu kết quả kèm TTL (ví dụ: 1 giờ):
const answer = await callLLM(normalized);
await redis.set(cacheKey, answer, 'EX', 3600);
return answer;
Lần sau người dùng hỏi lại, bot chỉ cần trả về kết quả từ Redis, nhanh, nhẹ, và không tốn token.
Lợi ích Kỹ Thuật của Context Caching
- Tốc độ phản hồi gần như real-time — không cần chờ LLM sinh text.
- Tiết kiệm tài nguyên và chi phí — giảm số lần gọi model hoặc truy vấn vector DB.
- Kết quả thống nhất — mọi người dùng cùng truy vấn nhận phản hồi giống nhau.
- Khả năng mở rộng cao — giảm tải cho hệ thống chính khi traffic tăng.
Trên thực tế, BizChatAI – nền tảng Chatbot AI của Bizfly, cũng đang áp dụng kỹ thuật này để tăng tốc phản hồi FAQ và xử lý hội thoại quy mô lớn. Redis giúp BizChatAI trả lời ngay lập tức các câu hỏi lặp lại, đồng thời giảm chi phí vận hành cho doanh nghiệp khi chạy chatbot đa kênh.

Một số Best Practice cho Dev khi Dùng Context Cache
- Normalize mọi truy vấn trước khi lưu để tránh cache trùng key.
- Đặt TTL hợp lý: FAQ có thể để lâu, dữ liệu thời gian thực (giá, tồn kho) nên giới hạn vài phút.
- Theo dõi hit/miss ratio bằng log hoặc metrics để tối ưu cache policy.
- Invalidate cache khi dữ liệu gốc thay đổi, ví dụ: cập nhật chính sách mới.
Kết luận
Context caching bằng Redis là một kỹ thuật nhỏ nhưng mang lại tác động lớn trong việc tối ưu hiệu suất hệ thống AI. Nó giúp giảm độ trễ phản hồi, tiết kiệm tài nguyên, và cải thiện trải nghiệm người dùng — những yếu tố quan trọng khi bạn đưa chatbot AI hoặc hệ thống RAG vào môi trường production.
Nếu bạn đang phát triển một chatbot hoặc trợ lý ảo, hãy tích hợp Redis cache ngay từ giai đoạn thiết kế pipeline – đó là cách đơn giản nhất để đạt hiệu năng cao mà không cần “đốt” thêm GPU hay token.
Nguồn tham khảo: https://bizfly.vn/techblog/ap-dung-context-caching-de-tang-toc-phan-hoi-voi-redis.html
All rights reserved
