Áp dụng cách chạy assembly của CPU vào coding cho python
1. Giới thiệu
Chào các bạn, hôm nay bài viết của mình sẽ trình bày về cách mà CPU chạy code, sau đó, chúng ta sẽ đi sâu vào cách mà developers như chúng ta, có thể áp dụng nó trong việc coding thế nào. Nghe hơi 'ảo' có đúng không? Vì thường các developers sẽ cần lập trình trên các ngôn ngữ high level để speed up việc ra feature mới, tốn ít effort, mà CPU thì … low level, làm sao developers chúng ta có thể tận dụng nó được? Store 1 biến và làm phép tính tổng thôi cũng đã mệt quá rồi, còn chưa kể đến việc compatibility, CPU code không có portable, đó là lý do mà chúng ta có các ngôn ngữ lập trình. Viết low level có mà trễ deadline chết !!! Làm sao nó có thể là sự thật, bớt giỡn đi. Bài viết này mình sẽ đưa các bạn cách mà các bạn có thể speed up công việc của mình dựa theo cơ chế chạy code của CPU. Mình sẽ đơn giản hoá những chỗ không cần thiết để đi nhanh vào chủ đề
2. CPU và cách mà máy tính chạy code của bạn
Như các bạn đã biết, CPU viết tắt là Central Processing Unit, là bộ vi xử lý trung tâm của máy tính, CPU đảm nhiệm việc chạy code trên máy tính của các bạn. Code của các bạn viết dạng text, máy tính không hiểu gì, máy tính chỉ biết các con số 0 và 1 thui, người ta sẽ design ra mã assembly (còn gọi là mã máy), nói nôm na là những quy tắc mã hoá các số 0-1 để kêu máy tính làm việc A, làm việc B, ...
Nói chung thì có 3 phương thức để ngôn ngữ lập trình chạy code của bạn trên 1 CPU:
2.1. Compiled (biên dịch)
Source code của các bạn sẽ được 'phân tích', và sẽ được chuyển đổi sang mã máy, để ra 1 file hoàn chỉnh gọi là executable. Trên Windows, cái executable gọi là .exe, còn trên Linux nó không có extension. Các bạn sẽ chạy file đó để run chương trình.

2.2 Interpreted (thông dịch)
Source code của các bạn sẽ không được chuyển sang mã máy liền, nó vẫn ở dạng text, và sẽ có 1 chương trình đọc từng dòng source của các bạn, và chuyển sang chạy mã máy từng dòng
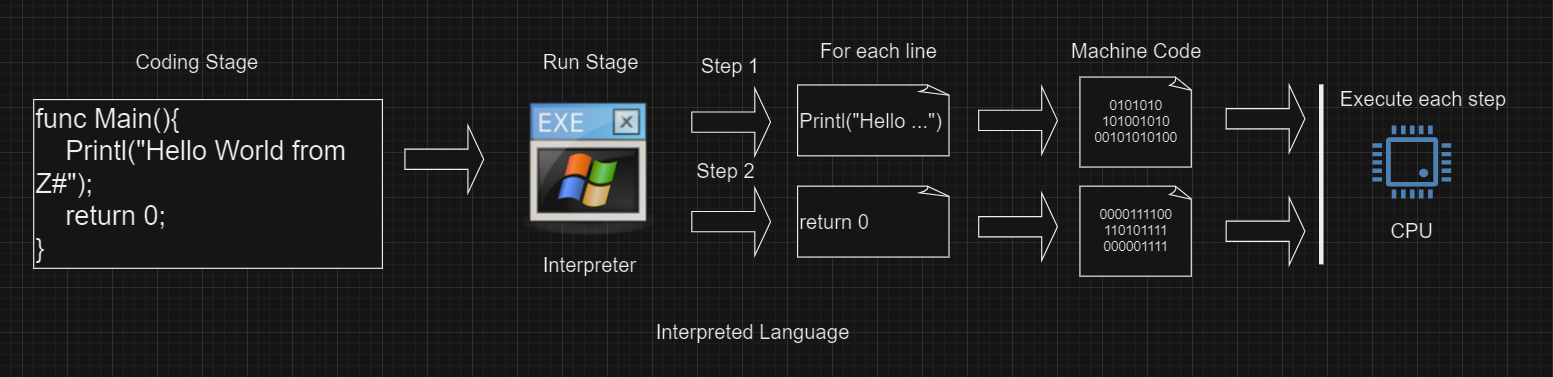
2.3. Hybrid/Customize (kết hợp/tuỳ chỉnh)
Có cần phải luôn luôn theo 2 phương pháp này không? Sẽ làm sao nếu chúng ta 'sáng tạo' ? Có trứng luộc thì có trứng rán, trứng ốp la, trứng nướng cũng là 1 cái trứng thôi mà nhiều nếu thử nhiều cách thì sẽ ra nhiều món ăn khác nhau. Thứ tự thực hiện các bước cũng quan trọng, khi bạn nấu mì trộn bạn sẽ bỏ hành vào trước khi đổ nước sôi, hay bạn sẽ đổ nước sôi rồi mới bỏ hành? Có cần phải luôn luôn chọn 1 giải pháp? Như nấu món cá bạn có thể chiên cá qua trước rồi mới kho, 2 phương pháp trong cùng 1 món!!!
Ví dụ như python áp dụng cả 2, source code của các bạn sẽ được 'compiled', nhưng không ra mã máy liền, mà ra dạng bytecode của Python, sau đó cái bytecode đó sẽ được 'interpreted' chạy bởi python executable, cách này sẽ giúp cho cái bytecode được portable, và sẽ dễ xử lý hơn, đỡ phải strip space, parse text sang syntax, etc etc. Nếu mình không muốn compile trước để run thì sao, mình muốn khi chạy mới compile, vì làm thế mình sẽ biết được chỗ nào mới thật sự chạy nhiều để compile đúng cái đó thui, mấy chỗ ít chạy mình có thể tạm lờ đi cho tới khi nó được chạy, thế thì mình có JIT (Just In Time Compiler), và vô vàn cách khác nữa
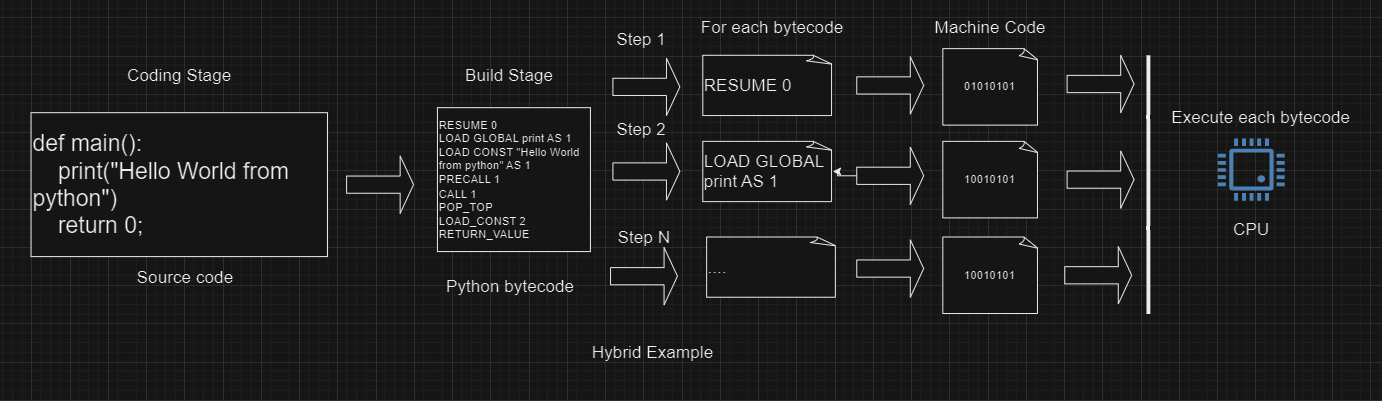
- Có 1 issue ở đây, là mã máy không có tương thích với all machines. Android xài ARMs, x86 CPU architecture. PC của các bạn xài x86-64 architecture. Mỗi CPU architecture nó có các rule khác nhau về cách hoạt động. Đó là lý do tại sao mà các ngôn ngữ như Java và python convert sang dạng bytecode của riêng nó trước khi qua mã máy, vì nó sẽ giúp cho ngôn ngữ được 'portable' giữa các machine
3. Thuật toán example bằng assembly
Để cho đơn giản thì mình sẽ explain trên architecture x86 mà desktop PC của nước mình hay xài. Không bật compiler optimization Mình có hàm C sau sẽ tính tổng 2 số nguyên a và b
int sum(int a, int b){
return a + b;
}
int main(){
return sum(1, 4);
}
Dịch ra assembly sẽ ra đoạn code sau:
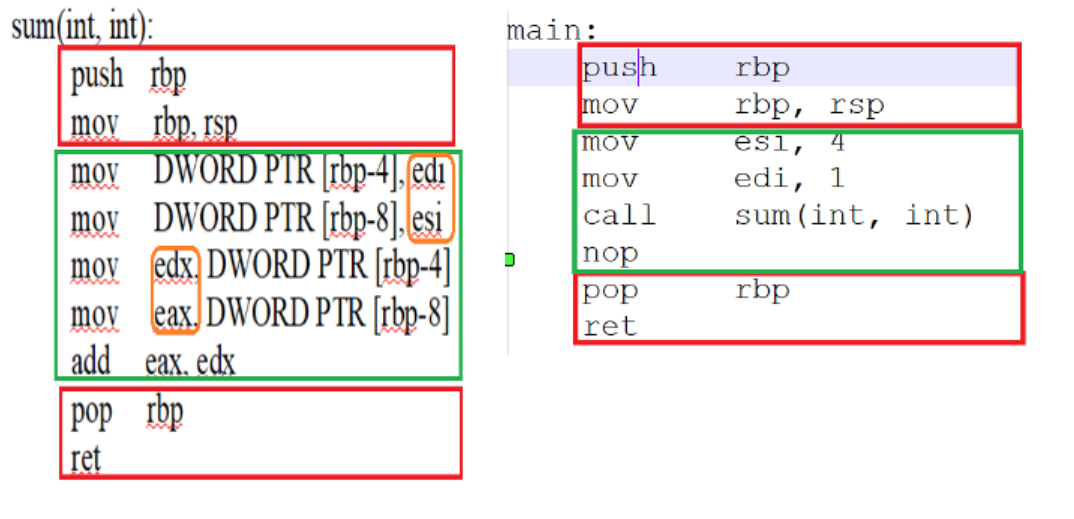
Nhìn hơi rối phải không? Các bạn cứ hiểu nôm na là mã máy CPU làm việc với các 'register', x86-64 thì có 16 general purpose registers: rax, rbx, rcx, rdx, rbp, rsp, si, rdi, r8->r15. Theo góc nhìn của developers, bạn có thể view 16 cái registers đó là 16 cái biến, giống như lập trình mà giới hạn số biến vậy, thêm 1 cái nữa là hầu như bạn khó có thể thao tác nhiều hơn 3 toán tử trên 1 assembly line, vd: add eax, edx sẽ là eax = eax + edx, phép toán này có 3 phần tử, nếu bạn muốn làm như vậy thì sao eax = eax + edx + ebx + esp? Thế thì bạn sẽ phải chia ra thành nhiều assembly code.
eax = eax + edx
eax = eax + ebx
eax = eax + esp
Ủa mà register eax, edx, ebx, esp đâu ra vậy? Nó là các access mode khác tương ứng cho rax, rdx, rbx, rsp, chữ 'r' đi đầu chỉ là sẽ dùng register đó như là 1 biến 64 bit, chữ 'e' đi đầu chỉ là sẽ dùng register đó như là 1 biến 32 bit.
Vì mình chỉ được xài 16 biến nên mình cần phải 'swap' register(s) qua lại, setup register cho đúng theo 1 quy ước cho sẵn, sau khi ra khỏi hàm mình phải revert lại state ban đầu
Code assembly mình sẽ chia ra 2 khung đỏ và 1 khung xanh lá cây. Khung đỏ tượng trưng cho việc setup và clean up registers khi ra/vào 1 hàm. Khung xanh lá cây chính là code chính của hàm đó.
Giống như cách chạy code bình thường, code sẽ bắt đầu từ hàm main, và chạy từ trên xuống dưới, gọi hàm thì nhảy vào hàm, xong return ra.
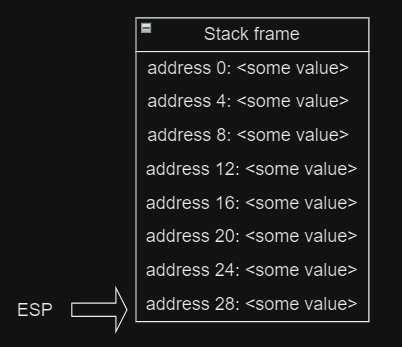
Ủa mà biến a, b của chúng ta đi đâu rùi? Trong lập trình, các local variables sẽ được lưu vào stack, các bạn có thể xem khung đỏ ở 2 hàm, nó giống nhau phải không? Hãy tưởng tượng cái stack trong memory như là 1 kệ sách, bạn có thể thêm cuốn sách vào phía trên (gọi là push), khi bạn muốn lấy 1 phần tử, bạn chỉ có thể lấy thằng trên cùng (gọi là pop, như trong hình pop sẽ lấy Book 3, rùi Book 2, rùi Book 1).

Tuy nhiên stack trong assembly sẽ 'đếm ngược', register ESP/RSP sẽ làm nhiệm vụ là con trỏ của stack, khi bạn push 1 item gì đó, biến ESP sẽ giảm đi theo đúng cái size của cái cần push
Mình sẽ push thử 2 biến integer tượng trưng cho a và b, 1 integer là 32 bits, 32 bits là 4 bytes, nên thanh ghi ESP sẽ giảm thiểu theo 4*2 = 8 bytes, nên cái stack tiếp theo sẽ như sau:
Bây giờ ta có thể cho ESP giảm đi 8 đơn vị, vd mình muốn clean up (pop) 2 biến a và b thì sao? Mình chỉ đơn giản tăng ESP lên 8 đơn vị lại
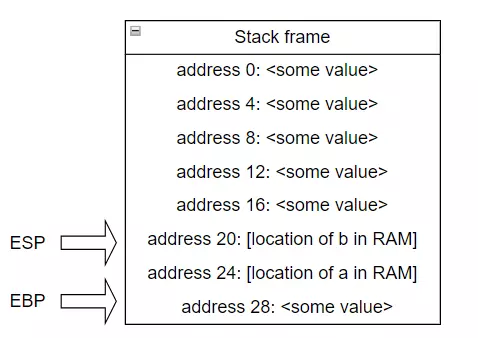
Ủa mà sao lại có thêm EBP? Register EBP/RBP được gọi là Base Frame Pointer, bạn cứ hình dung là assembly code push và pop nó ngầm định là sẽ thay đổi ESP register, nên việc tính toán vị trí các biến local sẽ khó khăn, nên trước khi vô hàm thì cần copy ESP vào EBP, để làm 'base' (cơ sở), vì cái EBP không thay đổi trừ khi mình bảo nó thay đổi. Giống như 1 hoạ sĩ, lúc bạn vẽ tranh/chụp ảnh thì bạn cần có 1 cái gì đó để 'tựa vào', nếu bạn không có nó thì gió có thể cuốn bức tranh của bạn bay mất (hay bạn rung tay), cái điểm tựa đó gọi là 'base' (cơ sở). EBP giờ sẽ là address 28.
Vậy là biến a sẽ ở vị trí EBP – 4 (24), và biến b sẽ ở vị trí EBP – 8 (20), logic generate assembly code của ta như 1 cái quạt, gió có thể thổi ESP thay đổi tuỳ thích, và nó sẽ không ảnh hưởng tới vị trí local variable của mình. Khung đỏ ở đầu function đã push RBP, là 1 register 64bit, cho nên tương đương với việc cấp phát 8 bytes cho 2 biến a, b. Đồng thời setup base pointer bằng việc copy ESP register. Khung đỏ ở cuối function pop RBP lại, có nghĩa là giải phóng 8 bytes cho 2 biến, đồng thời cũng restore cái value đã push vào RBP lại.
Back lại khung xanh lá cây, ở hàm main set EDI và ESI register là 1 và 4, thì này là convention các argument của 1 function sẽ đi vô các thanh ghi này. Khung xanh lá cây của hàm add pass arguments vô stack address, sau đó transfer vào register eax, edx, sau đó cộng 2 cái đó lại và store vào eax. Thanh ghi eax sẽ là return value của hàm, nên đó giải thích sao mà không cần specify thanh ghi gì trong return. Và trong C chỉ đc return 1 cái thui, mấy cái còn lại phải qua con trỏ, hay còn gọi là 'mutate', kỹ thuật này mình sẽ dùng cho chương sau.
4. Stack Frame
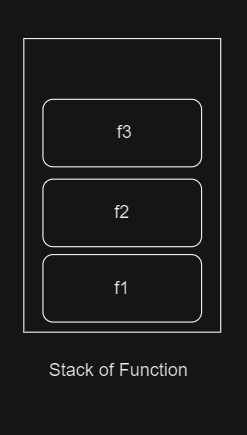
Không chỉ việc setup local variable cần dùng stack, việc gọi hàm cũng cần dùng stack, vd bạn có 3 hàm, hàm f1 gọi f2, hàm f2 gọi f3
Khi f3 chạy xong, nó sẽ được pop, f2 chạy xong, nó sẽ được pop, mỗi stack frame có 1 local variable riêng cho chính nó, thì stack của bạn sẽ là.
Debugger sẽ support show Stack Frame cho bạn trên UI. Bạn có thể check qua debugger trên IDE của mình, nó khá là useful.
5. Lưu ý
Bạn có thể chú ý vài 3 điểm:
- CPU sẽ phải setup input, và restore/revert lại trạng thái bình thường.
- CPU dùng stack để store các biến local.
- CPU chỉ return 1 value, nếu muốn return multiple values, thì phải 'mutate' các arguments, hiểu nôm na là thay đổi giá trị của argument mà không làm thay đổi vùng nhớ của nó:
Vd đoạn code python này:
list_a = [1,2,3,4]
list_a = [5]
Đoạn code trên thay đổi giá trị của list_a, tuy nhiên không 'mutate' nó, nó chỉ xoá cái list đi và cấp phát vùng nhớ khác. Nhưng đoạn code này:
list_a = [1,2,3,4]
list_a.clear()
list_a.extend([5])
Thì sẽ mutate cái list_a, nó vẫn là địa chỉ cũ, điều này là hữu ích cho bài viết này vì thông thường các ngôn ngữ sử dụng địa chỉ của 1 biến trong suốt quá trình run, nếu ta cấp phát vùng nhớ mới cho nó, thì cái biến đó chỉ được update 'bên ta', các hàm khác sẽ không thấy vì chúng chỉ xử lý trên địa chỉ cũ. Giống như trên Zalo có tính năng xoá tin nhắn và thu hồi tin nhắn, thu hồi thì xoá được 2 bên, còn xoá tin nhắn chỉ có 'bên ta'.
Ok, lý thuyết đã hết rồi, giờ qua bước áp dụng thôi, mình hy vọng các bạn đợi được tới đây.
6. Áp dụng vào thực tế
Use case 1: Monkey patching các hàm
-
Monkey patching là 1 khái niệm chỉ việc thay đổi các hàm, method của các class trong lúc run
-
Ủa? Thư viện của người ta đã code rùi, unittest rùi, qua mấy tháng development, tại sao mình lại đi thay đổi, chẳng phải phát sinh thêm bug sao?
-
Đúng là trong quá trình development bình thường, bạn không nên dùng Monkey Patching, bạn cũng không nên mù quáng mà đổi hàm của thư viện, nếu có thêm time thì bạn hãy code như bình thường.
-
Thế nhưng sẽ ra sao nếu:
-
1.1 Thư viện của các bạn có 1 bug, bug này chỉ use case của bạn mới bị, nên sẽ không được dev đặt priority cao? Có thể mất vài tuần để bên kia fix được cái bug, hoặc không bao giờ. Nguy chưa, lib support hết 80% rồi, còn 20% thì lại kẹt vậy. Thôi chúng ta nói với khách hàng là cái requirement này không được, hy vọng họ chấp nhận, và chắc team nào cũng 'kẹt' như mình thôi, library không support mà...
-
1.2 Bạn muốn thử nghiệm nhanh cách integrate 1 tính năng cho cả 1 product mà không cần tốn nhiều time, vd bạn thấy dự án bạn load json nhiều nhất, nên bạn cũng tò mò là có thể áp dụng cái thư viện parse json này làm nhanh app được không, nghe nói nhanh gấp 5 lần native lib !!! Chắc đợi 1-2 tuần cho tới khi bạn tìm ra code cũ và đảm bảo sửa hết những chỗ đó…
-
1.3 Thư viện của bạn luồng chạy không tương thích. Vd bạn muốn có 1 cách automated để scan tất cả các API Route của bạn để ra 1 Front End. Nên bạn dùng thư viện scan, việc này ổn. Tuy nhiên thư viện lúc boot sẽ scan API của bạn và đặt vào 1 Frontend UI, sẽ ra sao nếu bạn chạy system cloud và muốn bán API? Và bạn muốn users chỉ thấy các API mà họ trả tiền? Bạn search document của thư viện và, … oops, không có cách nào để filter hay làm gì cái API list một khi nó được generate lúc run. Nếu từ đầu chúng ta làm thì sẽ không bị cái issue này rùi, switch thư viện thui, à, có thể filter HTML ...
-
1.4 Thư viện có restriction. Ví dụ như bắt buộc project của bạn phải đọc 1 file 'EnglishModel.bin' ở thư mục lúc chạy code. Hoặc nó là wrapper qua code C vì performance, và mình cần pass tham số mà thư viện gốc C cần, tuy nhiên thư viện này đã đơn giản hoá rồi nên mình không thể nào trigger cái C arguments đó được
Solution:
Áp dụng pattern sau đây:
- Step 1: Dùng debugger và Step Into các hàm thư viện, đọc Call Stack cho tới khúc bị bug, ghi nhớ cái Call Stack tại thời điểm đó
- Step 2: Lưu reference của hàm cũ lúc boot time
- Step 3: Viết 1 hàm can thiệp, monkey patch hàm bị bug, hàm này sẽ hoạt động giống như cách CPU chạy assembly code
- Step 3.1: Set up tham số cần thiết theo yêu cầu của mình
- Step 3.2: Call lại hàm cũ với tham số compatible với khai báo hàm đó, lấy kết quả trả về
- Step 3.3: Trả về kết quả như ban đầu
Do code chúng ta high level nên 3.1 và 3.3 mình có thể add thêm 1 chút logic cho mình nữa, không cần phải giới hạn số biến, cũng như không cần giới hạn số toán tử trên 1 line of code, mình chỉ cần ensure tham số đúng như hàm cũ mong đợi, và trả về output như hàm gọi mong đợi.
Problem 1.1:
Cái library của bạn là 1 customer library có khả năng handle 122 tasks khác nhau, yêu cầu project bạn cần support được 30 cái tasks hoàn chỉnh trong vòng 6 tháng. Bạn đang implement 10 cái tasks cuối nữa. Các task số 29 addDDCP, và 30 addDDCP2 có chung 1 issue, library đã không support case này. Nên nếu bạn pass cái type này vào, bạn sẽ bị NameError do biến payload chưa có để mà return. Call stack cực kỳ phức tạp, có tới 5 levels mới tới được hàm này.
Stack frame sẽ như sau:
- Level 1: code của bạn, line 20
- Level 2: hàm f1 trong thư viện line 140
- Level 3: hàm f2 trong thư viện line 220
- Level 4: hàm f3 trong thư viện line 130
- Level 5: hàm f4 trong thư viện line 150
- Level 6: hàm generate_payload_for_add_api
- Level 7: hàm call_api (truyền cái payload của level 6 vào)
Sắp release rồi mà chỉ có 2 cái tasks vậy mà bạn phải xem hàng trăm source code chỉ để fix mấy cái 'nho nhỏ', trong khi mấy cái kia thì bạn chỉ cần đọc document, video hướng dẫn cách call API và vài tiếng là apply được. Mà bạn chỉ muốn nếu là addDDCP và addDDCP2 thì generate payload riêng cho nó thôi mà !!! Effort fix >>>>> kết quả mong đợi.
hàm gốc cần can thiệp
def generate_payload_for_add_api(task_name, task_parameters):
if task_name == “addABCD”:
payload = create_abcd_payload(task_parameters)
elif task_name == “addDEFG”:
payload = create_defg_payload(task_parameters)
# … 100+ cái else if
return payload
Đừng lo, áp dụng pattern này để giải cứu thôi, hàm chúng ta sẽ như là 'trợ lý' giúp hàm thiệt cung cấp missing data nếu nó không support được. Code bạn sẽ như sau:
import customer_library # ta muốn lấy module object
old_generate_payload_for_add_api = customer_library.generate_payload_for_add_api # backup hàm trong thư viện
def new_generate_payload_for_add_api(task_name, task_parameters):
if task_name == “addDDCP”: # add support for missing types
payload = create_ddcp_payload(task_parameters) # hàm mới của bạn
elif task_name == “addDDCP2”: # add support for missing types
payload = create_ddcp2_payload(task_parameters) # hàm mới của bạn
else:
payload = old_generate_payload_for_add_api(task_name, task_parameters) # gọi hàm cũ nếu không phải ngoại lệ
return payload
customer_library.generate_payload_for_add_api = new_generate_payload_for_add_api # assign hàm mới bằng cách mutate cái thư viện object
Ok với cách này bạn có thể tạm test lại kỹ và release cái code này ra được rồi, sau này nếu muốn bạn có thể refactor nó lại sau (đọc lại các đoạn code và take effort fix thật sự).
Problem 1.2:
Bạn đang xài thư viện json native lib của thư viện. Bạn thấy system bạn generate và parse phần lớn data json, và nó hơi mất thời gian, bạn research trên mạng thấy 1 thư viện json parse cực nhanh, tuy nhiên đoạn nào bạn cũng json loads, không gom vô 1 hàm common (nó chỉ có 1 dòng thôi mà) ? Không muốn mất nhiều time để thử nghiệm lib này? Sử dụng pattern này thôi. Bạn sẽ write 1 cái runtime translation cho cái hàm json loads. Bạn lập 1 bảng các khác biệt sau:
| Điểm khác biệt | Native json | Huge speed json lib |
|---|---|---|
| Tên hàm | json.loads | huge_speed_json.parse |
| Key parameter | <không có> | Default là chỉ chấp nhận key là string, muốn support key non-string thì pass parameters PARSE_NON_STRING_KEY |
| Object parameter | <không có> | Nếu muốn turn on object parsing support thì pass parameters PARSE_OBJECT, không thì chỉ parse các dạng basic như int, float, array, dict, ... |
| Return type | String | Bytes |
Ok, write runtime translation thôi
import json
import huge_speed_json
def new_json_loads(data, **keyword_arguments):
flags = [huge_speed_json.PARSE_NON_STRING_KEY, huge_speed_json.PARSE_OBJECT] # bạn có thể try 1 số flags khác để test performance
parsed_bytes = huge_speed_json.parse(data, flags=flags) # call hàm mới
return parsed_bytes.decode() # convert bytes sang string
json.loads = new_json_loads # mutate thư viện để relink hàm mới
Thế rồi hàm cũ đi đâu? Mình không cần nên thôi.
keyword arguments đâu ra vậy? Vì khai báo hàm json.loads có thể truyền keyword arguments vào nên mình khai báo vậy để tương thích, chứ thật sự code không cần cái đó, tuy nhiên nếu thích bạn có thể compare 2 thư viện sâu hơn và translate tham số ra cho thích hợp
Làm sao tích hợp? Bạn chỉ cần import file python có chứa đoạn code này là nó sẽ được run
Muốn xoá translation thì làm sao? Comment đóng này lại thôi, bỏ 1 dòng import ra, sẽ nhanh hơn là sửa 43 chỗ json.loads trong project phải không? Mà có chắc chỉ có 43 chỗ hay không?
Problem 1.3:
Bạn research được là khi load list API lên thì đường dẫn của nó là “<base_url>/api_list/”. Bạn debug thấy được đoạn code đọc API list như sau:
class APIPresentation():
… # các hàm khác
@route(“/api_list”, methods=[“GET”])
@functools.lru_cache()
def get_api_list(self):
api_metadata = self.get_api_metadata()
api_definition_maps = {}
for group in api_metadata[“group”]:
api_definition_maps[group.get(“name”)] = self.get_api_list_by_group(group)
return api_definition_maps
Có 2 decorators được apply, decorator @route tạo 1 URL Route "/api_list" method GET trên browser, thì khi user bấm vào https://abc.com/api_list sẽ chạy hàm này, tuy nhiên có 1 issue, hàm này được cache bởi module functools, có nghĩa là nó sẽ không được chạy lần 2 khi đã ra kết quả, nhưng chúng ta chỉ cần filter mà thôi, cho nên mình có thể GET ALL tổng thể + filter ra, nên cái cache đó thật ra không cản trở chúng ta!!!
À mà sao không dùng inheritance? Nếu code bạn tạo gọi class đó thì chúng ta có thể kế thừa và override, tuy nhiên nếu thư viện tự động hoá cái step này, thì inheritance sẽ không work nếu thư viện KHÔNG hỗ trợ cách replace custom class và call stack phức tạp
Áp dụng pattern thôi:
from module_folder_1.module_folder_2 import module_contain_the_class
old_get_api_list = module_contain_the_class.APIPresentation.get_api_list
def get_api_list_callback_func(self):
all_api_definition_maps = self.get_api_list()
filtered_api_definition_maps = filter_api_logic(all_api_definition_maps) # logic riêng của bạn
return filtered_api_definition_maps
module_contain_the_class.APIPresentation.get_api_list = get_api_list_callback_func # mutate class object
Bằng cách trên, bạn đã tạo 1 hàm callback có thể bắt được sự kiện load API List, và có thể thay đổi cái biến theo dạng dễ dev - Hashmap hay Array, nó sẽ dễ hơn so với tạo 1 route khác, call route đó, lấy HTML, ngăn không cho users đi vào đó (mà bạn vẫn đi vào được), rùi filter HTML nhiều phải không?
Problem 1.4:
Giờ thư viện của các bạn là wrapper từ C qua python, và code thư viện hardcode bạn phải đặt 1 file EnglishModel.bin vào cùng folder project, Và library không cho option modify, và nếu inherit được để thế cái hàm thì chắc chắn bạn đã làm rồi. Đó là thư viện AI bạn đang cần nên đành phải xài thôi.
Tuy nhiên nếu bạn muốn có nhiều ngôn ngữ, thì bạn phải swap file EnglishModel.bin qua lại như cách CPU chạy code vậy, chưa kể cái tên file là English cũng gây khó hiểu cho người dùng.
Áp dụng pattern thui. Problem 1.2 chúng ta giảm tham số đi, thì problem này ta thêm tham số  )
)
Hàm gốc:
class APIModel:
def __init__(self, temperature, n_steps, frequency): # không có file path
# … other logics code ...
self.parse_model_file(“EnglishModel.bin”) # take a file path
# … other logics code ...
Hàm cần can thiệp:
import library
def set_api_model_path(file_path):
library.APIModel.NEXT_FILE_PATH = file_path # configure a file path
old__init__ = library.APIModel.__init__
def new__init__(self, temperature, n_steps, frequency):
# … other logics code ...
try:
model_file_path = self.NEXT_FILE_PATH # get from class attribute
except AttributeError:
model_file_path = "EnglishModel.bin"
self.parse_model_file(model_file_path) # take a file path
# … other logics code ...
library.APIModel.__init__ = new__init__
Vậy là bây giờ bạn có thể setup 1 folder tên models/ và để nhiều model vô rồi: EnglishModel, VietnameseModel, IndianEnglishModel, etc mà không cần overhead hoán đổi 1 file và giải thích cho khách hàng các language kia đi đâu lúc run, dùng try catch bạn sẽ giữ lại behavior cũ là không pass gì thì như class cũ.
Use case 2: Leo 'stack' như leo núi
Bình thường thì các bạn gọi hàm, hàm cha sẽ truyền tham số từ hàm con. Nếu hàm con cần lấy thêm thông tin từ hàm cha, thì bạn sẽ phải đổi tham số và kêu hàm cha truyền theo. Tuy nhiên hãy tưởng tượng bạn xài 1 framework cho việc testing, và bạn muốn lấy thông tin mà framework không cho phép lấy. Ví dụ như đoạn script sau:
Feature: Calculator Addition
Scenario: Add two numbers
Given the calculator is turned on
When I enter the number 5
And I enter the number 7
And I press the add button
Then the result should be 12
Framework hỗ trợ bạn các hàm để tạo ra cái script này, cũng như test setup và teardown (nhìn sơ qua cũng như cách mà CPU hoạt động mà cho test case). Tuy nhiên giả sử lúc run, bạn cần lấy ra cái feature name , và scenario name bằng code python để ghi ra report bằng file document format cho đúng yêu cầu. Giả sử khi bạn search document thì, họ không support. Thì làm sao?
Theo suy nghĩ thì framework sẽ chạy từng scenario và in ra kết quả, nên lúc chạy từng line of code liên quan tới scenario đó sẽ dễ lấy mà đúng không? Với lại stack chỉ là các phép toán cộng trên 1 cái địa chỉ mà thôi, nên nếu bỏ cái abstration đó mà đi thẳng vào implementation ta có thể làm toán cộng để lấy data hàm cha !!!
Cách giải quyết là khi teardown 1 test case, ta sẽ inspect stack trace, và xem hàm parent nào gọi, và lấy thông tin của nó. Ok ta thấy stack trace như thế này:
- execute_each_feature(feature_info)
- execute_each_scenario(feature_info, scenario_info)
- all_scenario_teardown() # hàm của bạn
À hoá ra là hàm parent của mình có cái biến feature_info, scenario_info, thế mà nó không có available cho hàm mình xài, thật là tiếc, nhưng không sao, mình sẽ leo stack 1 level và lấy cái biến feature_info và scenario_info từ hàm cha thôi.
def all_scenario_teardown():
parent_stack_frame = sys._getframe(1)
parent_stack_local_variables = parent_stack_frame.f_locals
feature_info = parent_stack_local_variables.get(“feature_info”)
scenario_info = parent_stack_local_variables.get(“scenario_info”)
# làm gì với cái thông tin này thôi
À nếu mà stack frame không phải lúc nào là 1 thì sao? Thì ta có thể for loop cho tới khi ta kiếm được caller mong muốn, nếu không kiếm ra thì bạn nên chọn parent function khác để lấy thông tin.
7. Kết luận
Bạn đã biết được cách mà CPU chạy code của bạn, bạn cũng đã biết cách mà CPU setup và clean up 1 hàm assembly code, và bạn cũng đã biết cách mà developers chúng ta có thể vận dụng nó để giảm thiểu thời gian
Tuy nhiên phương pháp này cũng có khuyết điểm là code nhìn rất rối, và code đọc không tự nhiên theo ý developers, với lại khúc monkey patch phải đảm bảo là cái code đọc hàm original chỉ được execute 1 lần, nếu nó execute > 1 lần là sẽ bị infinity recursion do 1 hàm mới gọi nó hoài, nên chỉ có thể áp dụng khi bí quá, không có nhiều time hay tình thế bắt buộc bạn phải làm, và bạn biết bạn đang làm gì, và chấp nhận rủi ro, anyways khi dev thì bạn nên viết code đẹp và dễ đọc nhé, phòng bệnh hơn chữa bệnh. Các bạn nghĩ có thể apply các technique này cho các ngôn ngữ khác không? Các bạn nghĩ có thể viết 1 class để automate việc monkey patching để khắc phục hạn chế không, thêm tính năng ví dụ unpatch? Comment cho mình biết nhé. Bye các bạn
8. Nguồn:
-
Vẽ diagram https://app.diagrams.net/
-
Compiler Explorer https://godbolt.org/
-
ChatGPT https://chat.openai.com/
-
Stack Overflow https://stackoverflow.com/
-
Pattern này mình tự nghĩ ra, nên không có refer bài viết khác. Nếu nó đã có trong sách nào rồi thì comment cho mình biết nhé, mình cũng tò mò muốn biết cái thuật ngữ của nó là gì.
All rights reserved
