Agent Chunking – Kỹ thuật phân tách dữ liệu theo vai trò trong hệ thống AI Agent
Trong các hệ thống AI Agent hiện đại, việc chia nhỏ dữ liệu (chunking) không còn đơn thuần là tách văn bản theo độ dài token hay đoạn logic. Để Agent đưa ra phản hồi chính xác và có tính chuyên môn hóa cao, dữ liệu cần được tổ chức theo vai trò và nhiệm vụ cụ thể của từng Agent. Cách tiếp cận này được gọi là Agent Chunking là cơ chế phân tách dữ liệu theo nhiệm vụ nhằm hạn chế nhiễu và tối ưu hiệu quả truy xuất.
Bài viết dưới đây giúp bạn hiểu rõ cách vận hành, lý do cần triển khai và cách tích hợp Agent Chunking vào pipeline RAG hoặc hệ thống Agent Orchestration.
Agent Chunking là gì?
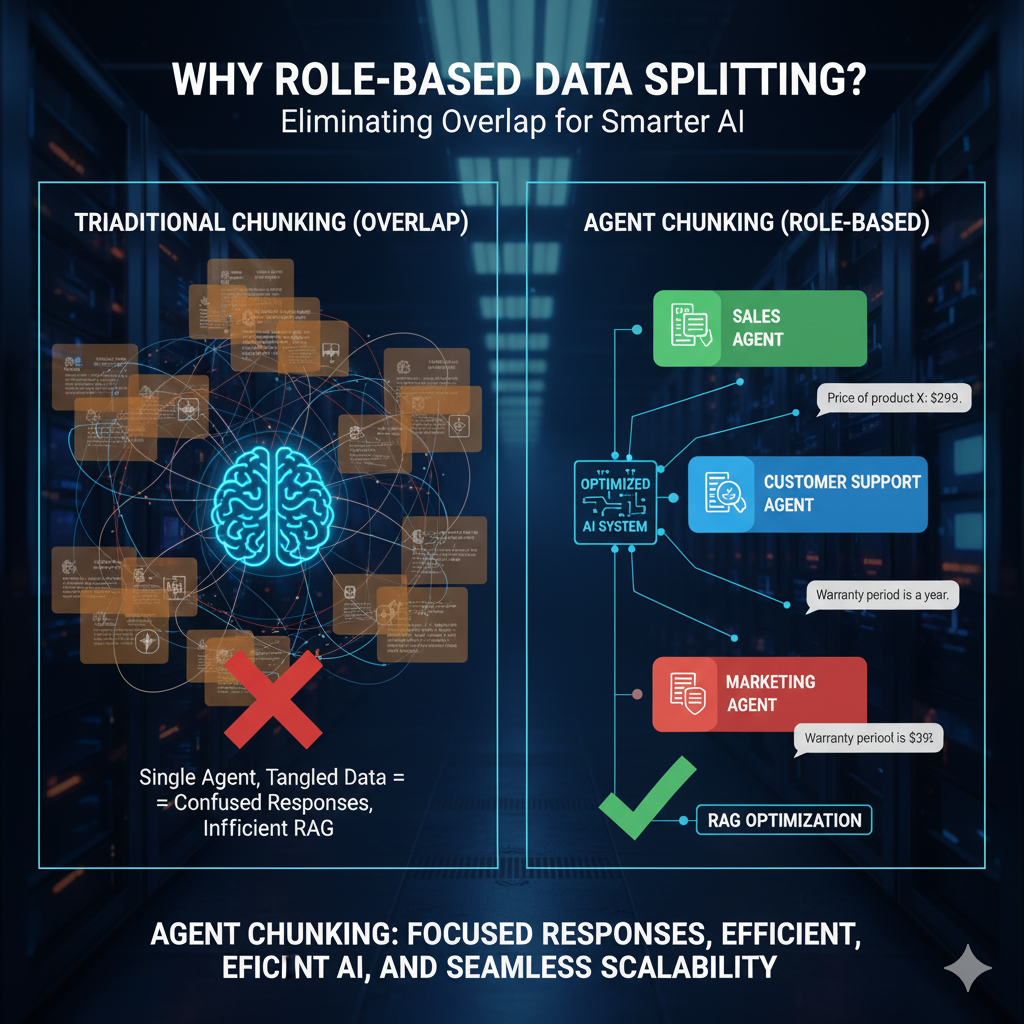
Trong các mô hình truyền thống, chunking thường dựa vào token limit, ngắt đoạn theo số ký tự hoặc theo ngữ nghĩa cơ bản. Tuy nhiên, cách chia này dễ tạo ra tình trạng “context contamination”, Agent phải xử lý dữ liệu không liên quan đến nhiệm vụ của nó.
Agent Chunking là cơ chế phân chia văn bản dựa trên role (vai trò) và task (nhiệm vụ) cụ thể của từng Agent. Thay vì đưa toàn bộ kho dữ liệu vào một Agent duy nhất, mỗi Agent chỉ nhận các phần dữ liệu phục vụ đúng chức năng của nó.
Ví dụ thực tiễn:
- Agent Sales: chỉ cần thông tin về sản phẩm, giá, ưu đãi, tồn kho.
- Agent CSKH: cần dữ liệu quy trình đổi trả, SLA, hướng dẫn bảo hành.
- Agent Marketing: cần insight hành vi người dùng, dữ liệu chiến dịch, báo cáo phân tích.
Cách phân bổ này giúp môi trường dữ liệu của từng Agent trở nên “sạch”, ít nhiễu và tối ưu cho mô hình truy xuất.

Vì sao cần chia dữ liệu theo vai trò/nhiệm vụ?
Giảm tải dữ liệu cho từng Agent
Agent chỉ xử lý phần dữ liệu gắn với nhiệm vụ → giảm compute, cải thiện độ trễ phản hồi.
Tăng độ chính xác của câu trả lời
Do hạn chế nhiễu ngữ cảnh, xác suất trả lời sai chủ đề thấp hơn đáng kể.
Tối ưu cho cơ chế RAG
RAG retrieval trở nên chính xác hơn khi truy vấn chỉ được thực hiện trên tập chunk phù hợp. Thay vì tìm trên toàn vector store → giảm thời gian truy vấn & tránh kéo phải dữ liệu không liên quan.
Dễ dàng mở rộng hệ thống Agent
Khi thêm một Agent mới, chỉ cần bổ sung tập dữ liệu riêng của Agent đó. Không ảnh hưởng đến hệ thống cũ.
Tăng khả năng kiểm soát và audit dữ liệu
Mỗi Agent có phạm vi dữ liệu độc lập → dễ kiểm tra, cập nhật, sửa đổi, hoặc rollback.
Quy trình triển khai Agent Chunking (dành cho Dev)
Dưới đây là quy trình tiêu chuẩn để build Agent Chunking trong môi trường RAG hoặc Agent-Orchestration:
Bước 1: Khai báo vai trò (Role Definition)
Xác định rõ các Agent bạn sẽ vận hành:
SalesAgentSupportAgentMarketingAgentFinanceAgent
Việc phân vai trò càng rõ, chunking càng chính xác.
Bước 2: Phân tích và gom nhóm dữ liệu gốc
Thông thường, dữ liệu nằm ở nhiều định dạng:
- PDF, docs, hợp đồng, policies
- Bảng giá, danh mục sản phẩm
- Quy trình nội bộ
- Báo cáo phân tích, KPI
Bạn cần phân loại trước khi chunking, đảm bảo dữ liệu có “boundary” rõ ràng.
Bước 3: Chunk theo ngữ nghĩa + nhiệm vụ (Hybrid Chunking)
Cách triển khai:
-
Dùng NLP libraries: SpaCy, NLTK, VnCoreNLP, Underthesea
-
Cắt dựa trên:
- Đoạn văn
- Tiêu đề logic
- Khối bảng
- Cấu trúc tài liệu
-
Tránh chia theo token thuần túy vì dễ mất context.
Đảm bảo mỗi chunk đủ dài để giữ ngữ cảnh nhưng đủ nhỏ để dễ index.
Bước 4: Gắn nhãn metadata cho từng chunk
Ví dụ metadata:
{
"doc_id": "product_01",
"role": "Sales",
"task": "pricing",
"chunk_id": "sales_03"
}
Metadata là yếu tố quyết định giúp Agent routing và retrieval chính xác.
Bước 5: Tích hợp vào pipeline RAG hoặc Agent-Orchestrator
Khi người dùng truy vấn:
- Lớp router xác định truy vấn thuộc Agent nào
- Agent chỉ tìm embedding trong các chunk được gán metadata tương ứng
- RAG thực hiện semantic search trên tập dữ liệu đã lọc
- Agent tạo phản hồi với LLM + context retrieved
Cách làm này giúp toàn bộ hệ thống vận hành liền mạch và chính xác.
Ứng dụng thực tế của Agent Chunking trong doanh nghiệp
Chatbot bán hàng
Chỉ đọc dữ liệu sản phẩm → phản hồi chính xác về giá, ưu đãi, tồn kho.
CSKH tự động
Tập trung vào quy trình nội bộ → trả lời câu hỏi đổi trả, bảo hành mà không bị “nhiễu”.
Marketing Agent
Phân tích dữ liệu hành vi, insight, báo cáo → tự động gợi ý nội dung hoặc email cá nhân hoá.
Tự động hóa báo cáo
Agent tài chính có thể xây dựng báo cáo doanh thu dựa trên dữ liệu trực tiếp từ chunk tài chính.
Đào tạo nội bộ
Agent Training chỉ đọc handbook, SOP, lộ trình làm việc → hỗ trợ onboarding nhân sự mới.
Kết luận
Agent Chunking không chỉ là một kỹ thuật cắt nhỏ dữ liệu mà là một chiến lược tổ chức tri thức cho hệ thống AI Agent. Khi dữ liệu được phân chia theo nhiệm vụ, mô hình không chỉ chính xác hơn mà còn dễ mở rộng, tối ưu chi phí và giảm thiểu rủi ro nhiễu ngữ cảnh.
Đối với các đội ngũ phát triển AI, đây là một kỹ thuật quan trọng cần được ưu tiên trong mọi dự án xây dựng hệ thống Agent chuyên nghiệp.
Nguồn tham khảo: https://bizfly.vn/techblog/agent-chunking-chia-du-lieu-theo-vai-tro-nhiem-vu-trong-ai-agent.html
All rights reserved
