6996 thắc mắc nho nhỏ trong Ruby và ROR (phần 2)
Bài đăng này đã không được cập nhật trong 4 năm
Chào các bạn, ở phần trước mình đã nói về các thắc mắc nhỏ trong Active Record của Rails, ở phần này, mình cũng tiếp tục nói về phần đó, tuy nhiên sẽ chia sẻ trọng tâm về SQL, Rails mình chỉ dùng để tạo ví dụ mà thôi. OK, LET'S GO.
SQL Constraint
Ràng buộc (Constraint) là các qui tắc được áp đặt cho các cột dữ liệu trên table. Chúng được sử dụng để giới hạn kiểu dữ liệu nhập vào một bảng. Điều này đảm bảo tính chính xác và tính đáng tin cậy cho dữ liệu trong Database. Ràng buộc (Constraint) có thể là column level hoặc table level. Ràng buộc cấp độ cột chỉ được áp dụng cho các cột, trong khi ràng buộc cấp độ bảng được áp dụng cho toàn bộ table. Khi làm một ứng dụng rails, trong Model chắc hẳn các bạn thường xuyên sử dụng Active Record Validations. Tuy nhiên, phải lưu ý rằng, Rails cung cấp cho chúng ta một số phương thức cập nhật dữ liệu trực tiếp vào database mà không thông qua Active Record Validations như update_all, update_column,...Vì vậy, đối với một số dữ liệu quan trọng thì không an toàn tí nào. May thay, trong SQL lại tồn tại constraint, giúp cho dữ liệu của chúng ta an toàn hơn. Cùng tham khảo ví dụ sau nhé. Mình tạo model User sử dụng devise.
class User < ApplicationRecord
devise :database_authenticatable,
:registerable,
:recoverable,
:rememberable,
:trackable,
:validatable
end
Trong file config của devise, mình config validation như sau:
# ==> Configuration for :validatable
config.password_length = 10..128
config.email_regexp = /\A[^@]+@example\.com\z/
Có thể thấy rằng mình thực hiện validate với password có độ dài tối thiểu là 10 kí tự và tối đa là 128 kí tự, email phải có đuôi @example.com, à ha, bạn có nghĩ chừng đó là đủ, tôi đã dùng devise, tôi đã config định dạng email để vailidate. Tuy nhiên, như mình đã nói ban đầu, việc mình làm vừa rồi chỉ giúp chúng ta validate dữ liệu ở tầng Rails application, cụ thể hơn là validate một object trên Rails, và nếu mình sử dụng hàm update_column thì coi như tèo. Xem tiếp nhé, trong database mình tạo 1 tài khoản user như sau:
viblo_development=# select * from users;
-[ RECORD 1 ]----------+-------------------------------------------------------------
id | 2
email | foo@example.com
encrypted_password | $2a$11$9ZUDVurrRxlv5NwWTXqVOu.BQQrb.UCto4jIfrykh9iIBpG/sEYue
reset_password_token |
reset_password_sent_at |
remember_created_at |
sign_in_count | 0
current_sign_in_at |
last_sign_in_at |
current_sign_in_ip |
last_sign_in_ip |
created_at | 2018-01-20 02:43:45.07622
updated_at | 2018-01-20 02:43:45.07622
Bây giờ mình sẽ thử cập nhật email của user nhé
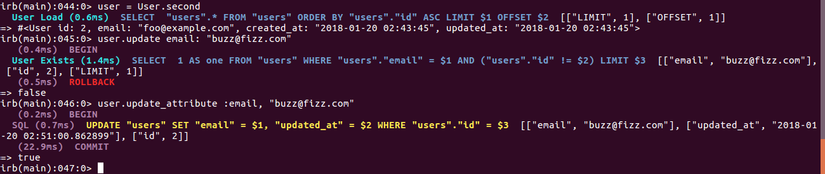 Có vẻ như validate k có tác dụng lắm nhỉ. Bây giờ mình sẽ thử tạo một SQL constraint, hiện tại thì Rails vẫn chưa hỗ trợ chúng ta phương thức tạo một constraint, vì vậy, để tạo constraint chúng ta buộc phải sử dụng SQL thuần thông qua migration trong rails như sau:
Có vẻ như validate k có tác dụng lắm nhỉ. Bây giờ mình sẽ thử tạo một SQL constraint, hiện tại thì Rails vẫn chưa hỗ trợ chúng ta phương thức tạo một constraint, vì vậy, để tạo constraint chúng ta buộc phải sử dụng SQL thuần thông qua migration trong rails như sau:
class AddEmailConstraintToUsers < ActiveRecord::Migration[5.1]
def up
execute %{
ALTER TABLE
users
ADD CONSTRAINT
email_must_be_company_email
CHECK ( email ~* '^[^@]+@example\\.com' )
}
end
def down
execute %{
ALTER TABLE
users
DROP CONSTRAINT
email_must_be_company_email
}
end
end
Tiến hành migrate và cập nhật lại dữ liệu xem điều gì xảy ra nhé:
 Sau khi cố tình update một email sai tên miền thì nó đã không cập nhật dữ liệu lên datatbase và trả về cho chúng ta một Exeption. Vì vậy , đối với các dữ liệu quan trọng thì chúng ta nên chú ý nhé, framework không phải lúc nào cũng an toàn như chúng ta vẫn nghĩ đâu.
Sau khi cố tình update một email sai tên miền thì nó đã không cập nhật dữ liệu lên datatbase và trả về cho chúng ta một Exeption. Vì vậy , đối với các dữ liệu quan trọng thì chúng ta nên chú ý nhé, framework không phải lúc nào cũng an toàn như chúng ta vẫn nghĩ đâu.
Perform Fast Queries with SQL Index
Chắc hẳn trong chúng ta ai cũng từng nghe qua Index trong SQL, nó giúp chúng ta truy vấn nhanh hơn, tìm kiếm nhanh hơn bla, bla, bla.... lý thuyết là một việc, còn chúng ta có áp dụng được hay không là một chuyện khác, ở đây, mình sẽ làm một ví dụ nho nhỏ về cách đánh INDEX trong SQL giúp cho việc truy xuất dữ liệu nhanh hơn ra sao nhé. Để bắt đầu chúng ta tiến hành tạo 1 bảng có tên là customers như sau:
class CreateCustomers < ActiveRecord::Migration[5.1]
def change
create_table :customers do |t|
t.string :first_name, null: false
t.string :last_name, null: false
t.string :email, null: false
t.string :username, null: false
t.timestamps null: false
end
add_index :customers, :email, unique: true
add_index :customers, :username, unique: true
end
end
Khởi tạo dữ liệu test với 350.00 record như sau:
350_000.times do |i|
Customer.create!(
first_name: Faker::Name.first_name,
last_name: Faker::Name.last_name,
username: "#{Faker::Internet.user_name}#{i}",
email: Faker::Internet.user_name + i.to_s +
"@#{Faker::Internet.domain_name}")
print '.' if i % 1000 == 0
end
Bây giờ chúng ta thử chạy câu lệnh tìm kiếm đơn giản trên sql xem thử thế nào nhé:
shine_development=# EXPLAIN ANALYZE
SELECT *
FROM
customers
WHERE
lower(first_name) like 'pat%' OR
lower(last_name) like 'pat%' OR
lower(email) = 'pat@example.com'
ORDER BY
email = 'pat@example.com' DESC,
last_name ASC ;
shine_development=#
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
(1) Sort (cost=1994.46..1996.33 rows=746 width=81) (actual time=100.825..100.829 rows=98 loops=1)
Sort Key: (((email)::text = 'pat@example.com'::text)) DESC, last_name
Sort Method: quicksort Memory: 38kB
(2) -> Seq Scan on customers (cost=0.00..1958.87 rows=746 width=81) (actual time=0.079..100.620 rows=98 loops=1)
(3) Filter: ((lower((first_name)::text) ~~ 'pat%'::text) OR (lower((last_name)::text) ~~ 'pat%'::text) OR (lower((email)::text) = 'pat@example.com'::text))
Rows Removed by Filter: 49902
Planning time: 1.223 ms
(4) Execution time: 618.258 ms
Mình sẽ giải thích cho các bạn đoạn kết quả trên. Hãy chú ý các dòng mình có đánh số thứ tự nhé (1) Ở đây, cơ sở dữ liệu đang cho chúng ta biết rằng nó sắp xếp kết quả tìm kiếm. bằng mệnh đề order_by mà chúng ta đã sử dụng trong câu lệnh truy vấn. Chi tiết hơn với các số liệu như cost, row, bla, bla.. là những thông tin hữu ích cho việc tuning queries, tuy nhiên chúng ta không cần quan tâm đến nó trong trường hợp này, chỉ chú ý là nó sắp xếp kết quả trả về của bạn mà thôi. (2) Đây là phần quan trong nhất trong Query Plan này,, nó nói về thuật toán tìm kiếm trong câu query. "Seq Scan on customers" nghĩa là nó kiểm tra từng dòng trong bảng xem có đáp ứng với điều kiện ở câu truy vấn hay không. Trong trường hợp lượng dữ liệu lớn thì sẽ rất tốn thời gian cho câu query. (3) Dòng này cho chúng ta thấy cơ sở dữ liệu thực hiện mệnh đề where của chúng ta như thế nào, nó lọc từng dòng trong database với điều kiện ta truyền vào ở mệnh đề where. (4) Cuối cùng, cơ sở dữ liệu cho chúng ta thấy thời gian mà nó thực thi câu lệnh truy vấn. Trong trường hợp này là hơn nửa giây, đối với chúng ta, nửa giây chẳng đáng bao nhiêu, nhưng với cơ sở dữ liệu, đó là một khoảng vĩnh hằng. Bây giờ chúng ta thực hiện việc đánh index cho các trường mà chúng ta muốn tìm kiếm nhé
class AddLowerIndexesToCustomers < ActiveRecord::Migration[5.1]
def change
add_index :customers, "lower(last_name) varchar_pattern_ops"
add_index :customers, "lower(first_name) varchar_pattern_ops"
add_index :customers, "lower(email)"
end
end
Thực hiện migrate và cùng chạy lại câu lệnh tìm kiếm để xem tốc độ tìm kiếm dữ liệu có tăng lên không nhé
shine_development=# EXPLAIN ANALYZE
SELECT *
FROM
customers
WHERE
lower(first_name) like 'pat%' OR
lower(last_name) like 'pat%' OR
lower(email) = 'pat@example.com'
ORDER BY
email = 'pat@example.com' DESC,
last_name ASC ;
shine_development=#
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(1) Sort (cost=817.11..818.97 rows=746 width=81) (actual time=0.721..0.726 rows=98 loops=1)
Sort Key: (((email)::text = 'pat@example.com'::text)) DESC, last_name
Sort Method: quicksort Memory: 38kB
(2) -> Bitmap Heap Scan on customers (cost=24.43..781.51 rows=746 width=81) (actual time=0.150..0.579 rows=98 loops=1)
Recheck Cond: ((lower((first_name)::text) ~~ 'pat%'::text) OR (lower((last_name)::text) ~~ 'pat%'::text) OR (lower((email)::text) = 'pat@example.com'::text))
(3) Filter: ((lower((first_name)::text) ~~ 'pat%'::text) OR (lower((last_name)::text) ~~ 'pat%'::text) OR (lower((email)::text) = 'pat@example.com'::text))
Heap Blocks: exact=90
-> BitmapOr (cost=24.43..24.43 rows=750 width=0) (actual time=0.075..0.075 rows=0 loops=1)
-> Bitmap Index Scan on index_customers_on_lower_first_name_varchar_pattern_ops (cost=0.00..6.79 rows=250 width=0) (actual time=0.037..0.037 rows=98 loops=1)
Index Cond: ((lower((first_name)::text) ~>=~ 'pat'::text) AND (lower((first_name)::text) ~<~ 'pau'::text))
-> Bitmap Index Scan on index_customers_on_lower_last_name_varchar_pattern_ops (cost=0.00..6.79 rows=250 width=0) (actual time=0.015..0.015 rows=0 loops=1)
Index Cond: ((lower((last_name)::text) ~>=~ 'pat'::text) AND (lower((last_name)::text) ~<~ 'pau'::text))
-> Bitmap Index Scan on index_customers_on_lower_email (cost=0.00..10.29 rows=250 width=0) (actual time=0.022..0.022 rows=0 loops=1)
Index Cond: (lower((email)::text) = 'pat@example.com'::text)
Planning time: 0.193 ms
(4) Execution time: 14.732 ms
Lần này, query plan có vẻ bự hơn cái trước nhỉ, hãy nhìn kỹ dòng (2) bây giờ k còn là "Seq scan" nữa, mà thay vào đó là "Bitmap Head Scan". Các dòng bắt đầu bằng Bitmap Index... cho chúng ta thấy rằng cơ sở dữ liệu đang quét dữ liệu theo index mà chúng ta đã cài đặt, do đó nó không kiểm tra từng hàng như là "Seq Scan", và đặc biệt là nó quét bằng 3 luồng riêng biệt cùng 1 lúc, mỗi luồng cho một điều kiện mà chúng ta đã truyền vào ở mệnh đề where và sau đó in kết qua ra cùng với nhau. Wow, thật ấn tượng, chú ý execition time khi không đánh index là 618.258 ms, trong khi sử dụng index chỉ là 14.732, nhanh gấp 40 lần. Ở đây mình không giải thích nhiều tại sao lại như vậy, vì mình nghĩ bạn nào chắc hản cũng đã biết về index và thuật toán tìm kiếm của nó, vì vậy ở đây mình chỉ ra một ví dụ đơn giản để áp dụng nó mà thôi. Đánh index cũng là một cách để chúng ta optimize hệ thống, giúp cho hệ thống của ta truy xuất dữ liệu nhanh hơn. Tuy nhiên, ở đây, chúng ta chỉ mới đánh index trên một bảng, trong thực tế, một database có rất nhiều bảng với rất nhiều liên kết giữa các bảng, mặc dù đã đánh index giữa các bảng với nhau, nhưng việc truy xuất dữ liệu sử dụng join giữa rất nhiều bảng làm ảnh hưởng đến tốc độ truy xuất dữ liệu. Vấn đề đặt ra là có cách nào để tăng tốc hay không, cùng tìm hiểu vấn đề này cùng mình ở bài sau nói về Materialized Views trong SQL nhé. Hẹn gặp các bạn ở bài sau
All rights reserved
