#6 Học database qua tip & trick – và cái giá mình phải trả
Đây là một phần trong series mình chia sẻ về những gì mình đã làm khi xây dựng và vận hành hạ tầng backend trên AWS cho công ty. Không phải là best practice hoàn hảo, cũng không phải kiến thức quá cao siêu. Chỉ đơn giản là những gì mình đã học được, thử nghiệm và áp dụng trong quá trình làm việc hằng ngày. Nếu thấy hay, kết nối với mình tại: LinkedIn
Mình là một developer đã gần 10 năm kinh nghiệm, cũng từng đó năm làm việc với cơ sở dữ liệu. Mình đa số làm việc với các cơ sở dữ liệu dạng quan hệ (RDBMS) từ Postgresql, Oracle đến SQL Server, Mysql. Nói là vậy, trong phần lớn thời gian đó, mối quan hệ của mình và database, cũng chỉ dừng lại ở mức “xã giao”, vài câu select cơ bản, rồi insert, update, delete, không hiểu quá sâu về bản chất cũng như thành phần bên dưới của nó.

Những lời khuyên quen thuộc
Nếu các bạn tìm trên internet, cách để tối ưu một câu lệnh SQL, không khó để tìm ra các bí quyết “kinh điển” như bên dưới:
Đừng nên select tất cả các cột , select ít cột thôi thì câu lệnh query sẽ nhanh hơn nhiều
Table ít bản ghi thì câu lệnh sẽ nhanh
Nếu câu query mà có sort by trên cột nào thì đánh index trên cột đấy
Câu lệnh mà chậm thì có thể nghĩ ngay tới partitioning hoặc sharding cho cơ sở dữ liệu
Thay đổi thứ tự câu lệnh sẽ tăng tốc hiệu năng của câu SQL
Table bị phân mảnh luôn không tốt, ảnh hưởng tới hiệu năng, phải chống phân mảnh
Thực sự ở đây, mình không đánh giá sự đúng sai của những lời khuyên này, nhưng chúng chỉ là phần “ngọn”, thường mình áp dụng như mội cái máy: làm xong rồi quên luôn, chả nhớ những cái tip trick này nữa rồi sau đó 1 vài tháng lại phải tìm lại.
Các bạn không nhầm đâu, đó là cách làm việc của mình trong nhiều năm liền và mình tin cũng có nhiều người tìm thấy mình trong đó. Kiểu như đó là cách làm việc dựa trên “Tip &Trick” thay vì tư duy hệ thống.
Tới một ngày
Rồi một ngày, mình xem các video trên YouTube hướng dẫn về tối ưu cơ sở dữ liệu của anh Trần Quốc Huy (mình thề không phải PR cho ông anh này đâu nhé, nhưng thực sự có những video đáng xem =)))), mình ấn tượng nhất câu nói của anh:
Trong cơ sở dữ liệu, khi bạn biết về chiến lược thực thi, thì mấy cái tip trick trên mạng đều là vớ vẩn hết
Thế rồi mình mới hiểu ra tại sao trước đây, mình luôn có một nỗi sợ khi làm việc hoặc phỏng vấn xin việc hay xử lý sự cố liên quan tới database, đến từ việc mình chỉ biết Syntax (cú pháp) mà không biết Mechanism (Cơ chế). Lúc nào mình cũng cảm thấy có một cái gì đó như kiểu “điểm mù”, kiểu như đừng nhắc tới nó, tôi chỉ biết vài câu select thôi, please.
Khi mình chạy một câu query, điều gì diễn ra bên dưới? Cái gì tốn thời gian? Vì sao lại tốn thời gian?
Tại sao dùng Oracle bạn phải trả phí khá cao, trong khi các open source như Postgresql hay Mysql đều ngon? tự nhiên bỏ cả đống tiền ra mua license có bị điên không ?
Tại sao Postgresql của bạn lại bị phân mảnh và có nên dùng VACUUM không?
Tại sao khi mình DELETE bản ghi mà dung lượng bảng không đổi?
Khi bạn hiểu được cái gì thực sự diễn ra bên dưới, mọi câu hỏi trên đều trở nên sáng tỏ.
Một chút cơ bản
Cái này các bạn có thể search được dễ dàng nhưng mình sẽ nhắc lại vì nó rất quan trọng. Trong nhiều hệ cơ sở dữ liệu, đơn vị lưu trữ và xử lý vật lý thường không phải từng bản ghi riêng lẻ, mà là page hoặc block. Mỗi page/block là một khối dữ liệu có kích thước cố định hoặc gần cố định, thường cỡ vài KB đến vài chục KB tuỳ hệ thống. Có thể hình dung nó như một trang giấy và mình viết từng dòng trên đó.
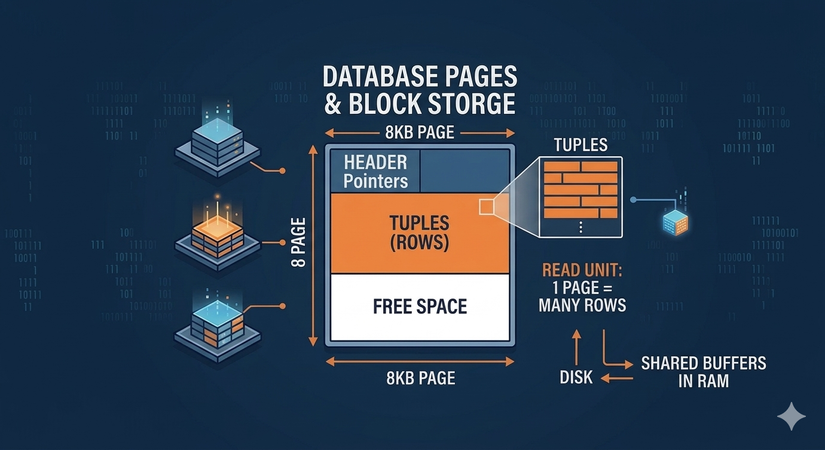
Khi mình muốn database đọc một bản ghi, nó thường làm việc với cả page/block chứa bản ghi đó, chứ không chỉ đọc đúng một dòng duy nhất từ ổ đĩa. Vì vậy, hiệu năng truy vấn không chỉ phụ thuộc vào số dòng, mà còn phụ thuộc vào số lượng page/block phải đọc(scan), cách dữ liệu được sắp xếp, và việc có dùng cache hay không, hay phải trực tiếp truy cập ổ đĩa (disk) để load toàn bộ page lên RAM (Shared Buffers), rồi mới lấy được bản ghi đó ra.
Một truy vấn nhanh hay chậm thường phụ thuộc rất lớn vào chiến lược thực thi (execution plan) — tức là cách mà cơ sở dữ liệu chọn để thực hiện câu lệnh, mỗi loại cơ sở dữ liệu có một thuật toán khác nhau để tạo ra chiến lược thực thi. Cùng một câu SQL, nhưng nếu hệ thống chọn cách quét toàn bảng thì có thể chậm, còn nếu dùng index hợp lý thì có thể nhanh hơn rất nhiều.
Index thường là một cấu trúc dữ liệu (thường là B-tree) riêng giúp truy cập nhanh hơn bằng cách lưu thông tin tra cứu (thông tin cột đánh index) đã được sắp xếp kèm theo vị trí của con trỏ (Pointer), trỏ tới vị trí của page/block chứa dữ liệu đó. Nói đơn giản, index giống như mục lục của cuốn sách: nó không chưa toàn bộ nội dung chính, nhưng giúp tìm đến đúng page/block nhanh hơn.
Index không hoản hảo mà có mặt trái của nó: Bạn càng đánh nhiều index, thao tác WRITE (insert, delete, update) càng chậm, vì lúc đó nó database phải cập nhật thêm các cây Index tương ứng.
Trong Postgresql, khi bạn gõ lệnh bên dưới, sẽ hiện ra vị trí vật lý của row trong bảng:
select ctid, * from my_table;
Execution plan
Trong thực tế, database thường có cơ chế cache để tránh phân tích lại mọi thứ từ đầu nếu một truy vấn hoặc kế hoạch thực thi đã từng được dùng trước đó. Tuy nhiên, không phải lúc nào plan cũ cũng là tốt nhất cho mọi lần chạy, vì dữ liệu và điều kiện truy vấn có thể thay đổi. Một câu lệnh query nhanh hay chậm thì phụ thuộc vào chiến lược thực thi (execution plan). Mỗi loại cơ sở dữ liệu có các thuật toán khác nhau.
Lưu ý rằng không phải tất cả execution plan đều là tối ưu nhất (chỉ gần như thôi).
Các bước thực hiện một query là:
-
Kiểm tra syntax của câu SQL (thiếu FROM là trả lỗi luôn)
-
Kiểm tra tính đúng đắn (tên table, tên cột có đúng không)
-
Kiểm tra execution plan có trong cache chưa
-
Nếu có thì dùng luôn
-
Nếu chưa thì phân tích các chiến lược có thể xảy ra
-
Tạo ra chi tiết các bước thực hiện
-
-
Thực thi câu lệnh SQL
-
Trả về kết quả
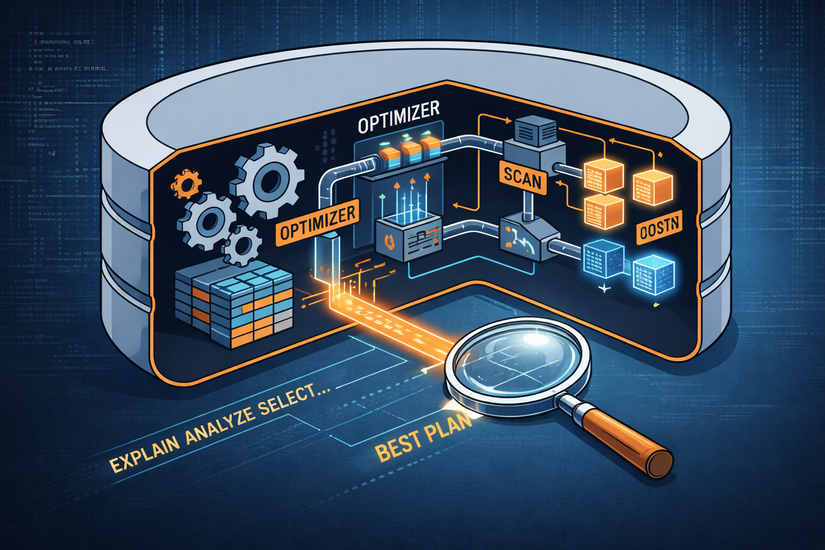
Trong các bước này, thường bước 3 và 4 là tốn nhiều thời gian nhất.
Trong Postgresql, bạn có thể dùng câu lệnh để xem chiến lược thực thi:
EXPLAIN (ANALYZE, BUFFERS) <your_query>;
Câu lệnh này sẽ cho bạn thấy:
- Cost: chi phí ước lượng của planner
- Actual time: thời gian thực thi thực tế
- Buffers / Shared hit / Shared read: số page được đọc từ cache và số page phải lấy từ đĩa.
Nếu muốn tối ưu truy vấn, bạn nên áp dụng các bước sau:
- xem execution plan
- kiểm tra số page/block bị đọc (scan)
- xem đã đánh index hợp lý hay chưa
- chạy câu lệnh thực tế thay vì đoán mò xem là chậm hay nhanh
Tìm hiểu sâu hơn một chút về phân mảnh trong Postgresql
Cơ chế MVCC
Postgresql dùng cơ chế MVCC (Multiple version concurency control) khi thực hiện UPDATE hoặc DELETE - xử lý đồng thời nhiều transaction mà không cần ép reader và writer phải chờ nhau trong phần lớn trường hợp. Thay vì sửa row ngay tại chỗ, khi có UPDATE, Postgresql thường tạo ra một version mới của row và giữ version cũ lại cho những transaction đang còn nhìn thấy nó.
Nhờ vậy, mỗi transaction sẽ thấy một snapshot nhất quán của dữ liệu tại thời điểm phù hợp, nên việc đọc dữ liệu thường không bị chặn bởi việc ghi, và việc ghi cũng thường không bị chặn bởi việc đọc. Đây là lý do Postgresql xử lý concurent workload khá tốt.
Tuy nhiên, nói “reader không bao giờ block writer” và “writer không bao giờ block reader” là quá tuyệt đối. Trong thực tế, Postgresql vẫn có locking cho một số trường hợp như tranh chấp cập nhật một row, khoá schema khi VACUUM FULL chẳng hạn, hoặc các thao tác đặc biệt khác.
Khi bạn UPDATE một dòng, ví dụ /users/123:
- Nó sẽ copy dòng cũ (123) tạo ra một dòng mới ở một page khác (vị trí khác) với dữ liệu được update
- Dòng cũ sẽ được đánh dấu là “expired”, các transaction mới sẽ không nhìn thấy dòng cũ này nữa một khi quá trình update đã commit xong, mà database cũng không xoá đi luôn.
- Kết quả là, trong ổ đĩa, vẫn tồn tại 2 dòng dữ liệu của cùng một ID (123), chỉ là một dòng được đánh dấu là expired mà thôi
- Khi SELECT, chiến lược thực thi (execution plan), vẫn phải quét qua toàn bộ pages(chứa các dead rows), làm chậm gấp đôi so với mức cần thiết
Tại sao khi DELETE mà ổ đĩa không được giải phóng
Khi DELETE thì cũng được thực hiện theo nguyên lý tương tự, dòng đó không hề được xoá mà chỉ được đánh dấu là “dead” mà thôi. Giống như khi một ngôi nhà được dán một biển báo là “cấm ở”, nhưng mà vị trí của ngôi nhà vẫn nằm đó, không được giải phóng để đặt một ngôi nhà khác.
Điều này làm cho bảng của chúng ta ngày càng phình to ra, dung lượng của bảng là 10GB, nhưng thực tế số lượng bản ghi mà ta thực sự làm việc có 2GB mà thôi, còn 8GB còn lại đều là được đánh dấu là “expired” hoặc “dead”, không để làm gì cả.
Vậy VACUMM trong Postgresql là gì
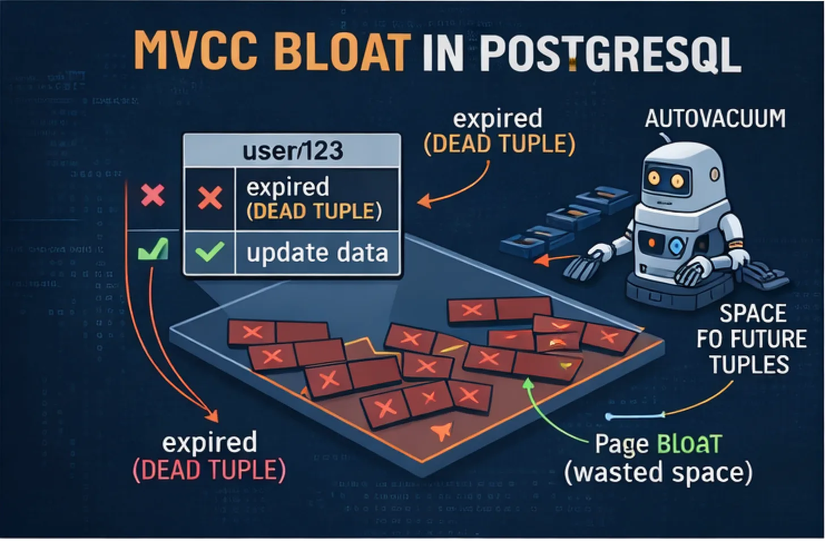
VACUMM là một câu lệnh dùng để giải quyết việc dữ liệu bị phân mảnh trong Postgresql. Có 2 cách tiếp cận với VACUMM:
- Standard VACUUM: PostgreSQL thường tự động xử lý việc này thông qua Autovacuum, tuy nhiên chúng ta có thể điều chỉnh cài đặt hoặc chạy thủ công nếu cần, nhiệm vụ chủa nó chính là scan tất cả những dòng expired hoặc dead, để đánh dấu rằng vị trí này đã khả dụng cho việc ghi thêm dữ liệu vào. Ngoài ra, nó còn dọn dẹp tham chiếu dead tuples trong index và các cập nhật map liên quan. Lần tới khi chúng ta dùng tới INSERT, thì dữ liệu sẽ được ghi vào đây thay vì ghi vào những vị trí mới hoặc thêm page mới, làm phình to bảng ra. Lưu ý là cái Standard VACUUM này không trả lại dung lượng ổ đĩa cho hệ điều hảnh nhé, nó chỉ đánh dấu vị trí đó cho Postgresql sử dụng trong tương lai.
- VACUUM FULL: Với lệnh này, thì Postgresql tạo ra một phiên bản mới, nhỏ gọn, đỡ cồng kềnh hơn cho bảng, nó giúp giải phóng luôn dung lượng của hệ điều hành, nhưng nó sẽ lock cái bảng(Exclusive Lock) đó lại trong một khoảng thời gian, bảng sẽ tạm thời không thể đọc và ghi trong lúc VACUUM FULL đang thực thi.
Vậy khi nào thì dùng VACUUM FULL?
Vì lệnh này sẽ khoá bảng lại, nên việc sử dụng VACUUM FULL trong thực tế chỉ trong một vài trường hợp cấp thiết, kiểu như:
- Khi bạn DELETE khoảng 60 đến 90% dữ liệu của bảng, bạn nên chạy câu lệnh này để giải phóng ổ đĩa cho hệ điều hành, cũng như làm size của bảng nhỏ lại.
- Bảng đang phình quá to: Ví dụ bảng đang có dung lượng 100 GB, mà dữ liệu thực tế có 10GB, thì nên dùng lệnh này sẽ clear đi 90GB dung lượng chết
- Bảng phục vụ cho việc đọc (heavy, reporting) mà lâu dữ liệu không được cập nhật lại, loại bỏ việc phân mảnh sẽ giúp query nhanh hơn.
Không nên sử dụng cho bảng mà được read/write/update nhiều, vì nó sẽ block bảng trong một khoảng thời gian (ngắn dài thì tuỳ bảng nhé), làm cho ứng dụng bị treo, gây ảnh hường đến performance của ứng dụng.
Nếu có 100 transactions cùng update một dòng tại một thời điểm thì sao ?
Tất nhiên là không thể có chuyện 100 transactions cùng “thành công” update một row theo kiểu chồng lên nhau một cách tự do. Thường sẽ xảy ra write-write conflict: một transaction update trước sẽ tạo ra version mới, và các transaction khác phải chờ, rồi khi tới lượt thì hoặc là đọc lại row mới để re-check điều kiện, hoặc bị abort/fail tuỳ isolation lever và cách database triển khai.
Giả sử có 100 transactions cùng muốn “update” một row, PostgreSQL đảm bảo tính toàn vẹn dữ liệu thông qua cơ chế Khóa cấp hàng (Row-Level Locking) và MVCC:
- Transaction đầu tiên lấy được quyền update sẽ tạo ra version mới của row
- Các transaction khác không “ghi đè trực tiếp” lên cùng một version đó, chúng sẽ bị serialize theo thứ tự thực thi, hoặc phải đợi version hiện tại xong rồi mới xử lý tiếp
- Nếu hai transaction cùng sửa đúng một row tại cùng một thời điểm, transaction đến sau thường phải re-read row mới và chạy lại điều kiện update, nếu không còn phù hợp thì nó có thể không update được nữa hoặc bị lỗi serialization tuỳ chế độ isolation
Version nào được giữ lại:
- Version mới nhất đã commit là version đang có hiệu lực cho các transaction mới
- Các version cũ hơn chỉ còn tồn tại để phục vụ transaction đang chạy hoặc snapshot cũ
- sau đó chúng sẽ được dọn bởi cơ chế garbage collection/vacuum/purge tuỳ hệ thống
Cơ chế của các loại cơ sở dữ liệu khác thì sao ?
Tổng quát thì nhiều database không dùng cơ chế MVCC như Postgresql thì sẽ thường xử lý UPDATE và DELETE theo hướng sửa dữ liệu tại chỗ hoặc khoá hàng/trang/bảng trong lúc sửa.
Cơ chế phổ biến
Update tại chỗ
Đơn giản hơn, UPDATE sẽ ghi đè trực tiếp lên row hiện có, thay vì tạo thêm một version mới như MVCC. Cách này tiết kiệm không gian hơn, nhưng thường cần lock để tránh nhiều transaction sửa cùng một lúc làm hỏng dữ liệu. Khi một transaction muốn UPDATE một row, database sẽ:
- lấy lock trên row, page, hoặc đôi khi cả table tuỳ engine và isolation level
- đảm bảo các transaction khác không đọc/ghi vào phần dữ liệu đang sửa theo cách gây mất tính nhất quán
- sau đó ghi giá trị mới vào vị trí dữ liệu hiện có, hoặc cập nhất cấu trúc lưu trữ nội bộ tương ứng.
Delete thực sự
Với DELETE, hệ thống có thể xoá row khỏi cấu trúc lưu trữ ngay, hoặc đánh dầu rồi dọn dẹp sau tuỳ engine. Điểm chung là cơ chế này thường phụ thuộc nhiều hơn vào lock và dọn dẹp vật lý của storage engine.
Locking-centric concurency
Ở các hệ thống thiên về locking, reader hoặc writer có thể phải chờ nhau nhiều hơn, tuỳ isolation level và loại lock. Điều này giúp mô hình dễ hiểu hơn, nhưng đồng thời làm concurency kém “mượt” hơn khi workload có nhiều đọc/ghi xen kẽ.
Ưu điểm
- Dễ hiểu và dễ triển khai hơn MVCC trong nhiều trường hợp
- Ít phải giữ nhiều version của cùng một row nên giảm overhead lưu trữ
- UPDATE và DELETE có thể gọn hơn về mặt vật lý nếu hệ thống hỗ trợ ghi đè trực tiếp tốt
Nhược điểm
- Concurrency thường kèm hơn MVCC, vì reader và writer dễ block nhau hơn
- Dễ gặp bottleneck khi nhiều transaction cùng chạm vào cùng một vùng dữ liệu
- Nếu hệ thống phải khoá quá nhiều, latency có thể tăng khi tải cao
Nếu một transaction đã lock row/page mà quên commit hoặc rollback ?
Thì lock đó thường sẽ được giữ cho tới khi session kết thúc hoặc connection bị đóng/killed. Trong thời gian đó, các transaction khác muốn đụng vào cùng tài nguyên có thể phải chờ, và nếu chờ lâu thì ứng dụng nhìn như bị “đứng”.
Hậu quả là:
- Transaction chưa kết thúc sẽ giữ quyền trên tài nguyên mà nó đang sửa, nên các transaction khác có thể bị block
- Có thể gây deadlock hoặc timeout: nếu nhiều transaction chờ lẫn nhau, hệ quản trị có thể phải chọn một transaction để huỷ
- Có thể làm bẩn trạng thái ứng dụng: phía app tưởng là “lỗi dữ liệu”, nhưng thực ra do lock chưa được giải phóng.
Nếu transaction bị bỏ quên quá lâu, khi connection bị đóng, process bị kill, hoặc DBMS phát hiện session chết, transaction sẽ bị rollback và lock được giải phóng.
Mình đã ổn hơn
Những thứ gì đi từ cơ bản đều rất tuyệt vời. Nó giúp mình hiểu rõ mình đang muốn gì, làm gì và những câu hỏi tại sao. 10 năm kinh nghiệm không có nghĩa là bạn biết tất cả. Đôi khi, lùi lại một bước để học về những thứ căn bản nhất (Fundamentals) lại là cách nhanh nhất để tiến xa hơn. Database rất thú vị, đừng để nó là một “điểm mù” trong sự nghiệp của bạn 🙃🙃🙃
Bài viết này cũng được mình dịch sang tiếng Anh trên blog substack của mình.
Mình viết lại những điều này như một cách để ghi nhớ hành trình làm nghề của mình. Nếu bạn cũng đang làm backend, devops hoặc cloud, hy vọng những chia sẻ này có thể giúp bạn một chút gì đó. Còn nếu có chỗ nào mình hiểu chưa đúng, mình vẫn luôn sẵn sàng học thêm.
All rights reserved
