2025 Bảng Xếp Hạng LLM Không Giới Hạn Top10
"Prompt này bị ChatGPT từ chối rồi..."
Tháng trước, khi tôi đang tạo AI assistant cho dự án cá nhân, tôi đã gặp phải rào cản này nhiều lần. Không phải tôi muốn làm điều gì xấu, chỉ đơn giản là muốn tạo ra những câu thoại hơi mang tính tấn công cho nhân vật thôi.
"Có LLM nào tự do hơn để sử dụng không nhỉ?"
Với suy nghĩ đó, tôi bắt đầu tìm hiểu về thế giới LLM không giới hạn chạy trên local.
Ban đầu tôi nghĩ "LLM local chắc hiệu suất thấp lắm?" Nhưng khi thực sự sử dụng, tôi phát hiện LLM local năm 2025 đã phát triển vượt xa sự tưởng tượng. Hơn nữa, nó còn bảo vệ được privacy và chi phí bằng không.
Lần này tôi muốn chia sẻ Top 10 LLM không giới hạn mà tôi đã thực sự thử nghiệm và các kỹ thuật vận hành có thể áp dụng trong thực tế.
LLM Không Giới Hạn Là Gì? Tại Sao Lại Được Chú Ý Ngay Bây Giờ?
LLM không giới hạn (Unrestricted) là những LLM được thiết kế với bộ lọc an toàn tối thiểu, khác với các dịch vụ cloud thương mại.
Các mô hình của OpenAI hay Anthropic có nhiều ràng buộc vì lý do đạo đức. Điều đó không xấu, nhưng đôi khi gây bất tiện cho các nhà phát triển.
4 Ưu Điểm Của LLM Cục Bộ
Những ưu điểm tôi cảm nhận được khi thực sự sử dụng:
1. Privacy Được Bảo Vệ Hoàn Toàn
Ngay cả prompt chứa dữ liệu nội bộ công ty hay thông tin cá nhân cũng không được gửi ra ngoài. Đây là điều kiện bắt buộc khi xử lý thông tin mật của doanh nghiệp.
2. Chi Phí Bằng Không
Cần đầu tư phần cứng ban đầu, nhưng một khi đã xây dựng môi trường thì có thể sử dụng không giới hạn. Không cần lo lắng về phí API.
3. Độ Tự Do Cao
Có thể sử dụng tự do cho hoạt động sáng tạo, nghiên cứu, phát triển prototype mà không có ràng buộc.
4. Có Thể Tùy Chỉnh
Có thể tạo ra mô hình chuyên biệt cho mục đích sử dụng của mình thông qua fine-tuning hoặc LoRA.
Tại Sao Lại Được Chú Ý Trở Lại Vào Năm 2025?
Từ cuối năm 2024, thị trường LLM local đã trưởng thành nhanh chóng.
Sự Phổ Biến Của MoE (Mixture of Experts)
Với sự xuất hiện của Mixtral, Llama3 MoE, ngay cả GPU nhỏ cũng có thể đạt hiệu suất cao.
Chất Lượng Mô Hình Cộng Đồng Được Cải Thiện
Các mô hình được tuning độc đáo như Hermes, Dolphin, MythoMax đã đạt hiệu suất gần bằng các mô hình thương mại.
Thay Đổi Workflow Phát Triển
Nhu cầu API hóa LLM để tích hợp vào hệ thống công ty tăng mạnh. Tính thực tiễn của LLM local đã tăng vọt.
Rủi Ro và Lưu Ý Của LLM Cục Bộ
Không thể chỉ nói về ưu điểm. Cần hiểu rõ cả rủi ro.
An Toàn Đầu Ra Là Trách Nhiệm Của Bản Thân
Mô hình không giới hạn có thể tạo ra nội dung không phù hợp. Không có bộ lọc an toàn như dịch vụ thương mại.
Chất Lượng Mô Hình Có Sự Chênh Lệch
Mô hình cộng đồng có chất lượng khác nhau tùy theo nguồn phân phối. Quan trọng là phải lấy từ nguồn đáng tin cậy.
Có Thể Không Có Cập Nhật Bảo Mật
Mô hình mã nguồn mở có thể không được sửa ngay lập tức ngay cả khi phát hiện lỗ hổng.
Yêu Cầu Phần Cứng Cao
Để chạy mượt mà cần GPU khá mạnh. Đặc biệt mô hình 13B trở lên khuyến nghị VRAM 16GB trở lên.
Phiên Bản 2025: Bảng Xếp Hạng LLM Không Giới Hạn Top 10
Tôi sẽ giới thiệu các mô hình được khuyến nghị theo từng mục đích sử dụng từ những gì đã thực sự thử nghiệm.
Tiêu chí đánh giá gồm 4 điểm sau:
- Độ tự do (Tính Unrestricted)
- Khả năng suy luận (Reasoning / QA / Long Context)
- Khả năng sáng tạo (Câu chuyện・Roleplay)
- Tính vận hành local (API hóa・Sự phong phú của quantization)
Hạng 1: Dolphin 3.0 (Base Llama 3.1・8B)
Đánh giá: Mạnh nhất cho mục đích coding・agent
Dolphin 3.0 mặc dù chỉ có 8B nhưng lại chuyên biệt về coding và function calling.
Khi thực sự sử dụng, tôi ngạc nhiên về độ chính xác cao của function calling. Nếu tạo API agent thì đây là lựa chọn đầu tiên.
- Lĩnh vực mạnh: Coding / Agent / Function Calling
- Tính vận hành local: Rất cao (chạy được với 8GB VRAM)
- Tham khảo: Hugging Face / Dolphin 3.0
Hạng 2: Nous Hermes 3 (Base Llama 3.2・8B)
Đánh giá: Tối ưu cho đối thoại dài và roleplay
Hermes 3 có tính nhất quán xuất sắc trong đối thoại multi-turn.
Nếu dùng cho chatbot hay roleplay thì đây là ổn định nhất. Có thể duy trì tính cách nhân vật trong suốt cuộc trò chuyện dài.
- Lĩnh vực mạnh: Dialogue / Roleplay / Agent
- Tính vận hành local: Cao
- Tham khảo: Hugging Face Hermes 3
Hạng 3: Chronos-Hermes 13B v2
Đánh giá: Bậc thầy văn phong chuyên biệt cho hoạt động sáng tạo
Dòng Chronos mạnh về tạo văn phong, dòng Hermes có tính nhất quán chỉ dẫn cao. Mô hình hybrid này phát huy sức mạnh trong tạo tiểu thuyết và kịch bản.
Khi thực sự cho viết truyện ngắn, dòng văn tự nhiên và dễ đọc.
- Lĩnh vực mạnh: Sáng tạo・Câu chuyện・Tạo văn bản dài
- Tính vận hành local: Cao (13B dễ xử lý)
- Tham khảo: Hugging Face Chronos-Hermes
Hạng 4: MythoMax-L2 13B
Đánh giá: Đồng hành của nhà sản xuất RPG・Novel game
Mô hình chuyên biệt sáng tạo có độ phổ biến sâu rộng trong cộng đồng.
Khi sử dụng cho cảnh đối thoại RPG hay tạo text novel game, cá tính nhân vật được thể hiện rõ ràng. Phiên bản quantization cũng phong phú nên dễ triển khai.
- Lĩnh vực mạnh: Novel / RPG / Creative Writing
- Tính vận hành local: Cao (Hỗ trợ GGUF / GPTQ)
- Tham khảo: Hugging Face MythoMax L2 13B
Hạng 5: LLaMA 3 Dark Series (MoE 18.4B)
Đánh giá: Nếu coi trọng khả năng suy luận thì chọn cái này
Mô hình MoE phái sinh không chính thức của dòng Llama3. Khả năng suy luận cao và mạnh về giữ context dài.
Tuy nhiên yêu cầu phần cứng hơi cao. Khuyến nghị VRAM 24GB trở lên.
- Lĩnh vực mạnh: Long context / Reasoning
- Tính vận hành local: Trung bình~Cao
- Tham khảo: Hugging Face Dark LLaMA
Hạng 6: Llama 2 Uncensored (7B~13B)
Đánh giá: Cứu tinh của môi trường cấu hình thấp
Mô hình định hình vẫn được sử dụng bền bỉ từ 2024~2025.
Chạy được trên GPU cũ hay môi trường ít VRAM. Tối ưu cho prototype và mục đích giáo dục.
- Lĩnh vực mạnh: General / Prototyping
- Tính vận hành local: Rất cao
- Tham khảo: Hugging Face Llama2 Uncensored
Hạng 7: WizardLM Uncensored (Llama2 13B)
Đánh giá: Đa năng mạnh về tạo code
Phiên bản không giới hạn của dòng Wizard. Mạnh về tạo code và ổn định trong chat đa dụng.
Tiện lợi khi dùng để tạo Python script hay code review.
- Lĩnh vực mạnh: Coding / General Chat
- Tính vận hành local: Cao
- Tham khảo: Hugging Face WizardLM
Hạng 8: Dolphin 2.7 Mixtral 8×7B
Đánh giá: Nếu muốn hiệu suất cao thì chọn cái này
Sự kết hợp giữa dòng Dolphin và Mixtral MoE. Mạnh mẽ ở cả hai mặt suy luận và sáng tạo.
Tuy nhiên cần xác nhận yêu cầu GPU và tính tương thích mô hình. Khuyến nghị VRAM 32GB trở lên.
- Lĩnh vực mạnh: Coding / Tạo tài liệu
- Tính vận hành local: Trung bình
- Tham khảo: ollama Dolphin Mixtral
Hạng 9: GPT-4All (Framework + Nhóm mô hình)
Đánh giá: Môi trường all-in-one tối ưu cho người mới
Framework phổ biến nhất như môi trường LLM offline.
GUI dễ sử dụng, người mới cũng có thể bắt đầu ngay. Bản thân mô hình nhẹ và dễ xử lý.
- Lĩnh vực mạnh: Chat tổng quát / Dành cho người mới
- Tính vận hành local: Rất cao
- Tham khảo: GPT4All chính thức
Hạng 10: Falcon LLM (TII)
Đánh giá: Mô hình ổn định cho nghiên cứu
Mô hình dành cho nghiên cứu do TII Trung Đông phát triển. Suy luận local tương đối ổn định.
Hiệu suất cao với chỉ dẫn tiếng Anh, phù hợp cho nghiên cứu học thuật và phân tích dữ liệu.
- Lĩnh vực mạnh: QA / Analysis / Research
- Tính vận hành local: Trung bình
- Tham khảo: Falcon LLM chính thức
Bảng So Sánh Mô Hình: Tổng Hợp Đặc Điểm Một Cách Trực Quan
| Mô hình | Quy mô tham số | Đặc điểm | Lĩnh vực mạnh | Tính vận hành local |
|---|---|---|---|---|
| Dolphin 3.0 | 8B | Nhanh・Nhẹ・Nhất quán chỉ dẫn | Coding / Agent | Rất cao |
| Nous Hermes 3 | 8B | Nhất quán văn bản dài・Roleplay | Dialogue / RP | Cao |
| Chronos-Hermes v2 | 13B | Văn phong + Chỉ dẫn | Sáng tạo・Câu chuyện | Cao |
| MythoMax-L2 | 13B | Sáng tạo văn bản dài | Novel / RPG | Cao |
| LLaMA 3 Dark | 18.4B MoE | Suy luận mạnh | Long context | Trung bình~Cao |
| Llama2 Uncensored | 7–13B | Nhẹ | General | Rất cao |
| WizardLM Uncensored | 13B | Code mạnh | Coding | Cao |
| Dolphin Mixtral | 8×7B MoE | Hiệu suất cao | Coding / Tạo tài liệu | Trung bình |
| GPT-4All | 3B–7B | Chuyên biệt offline | Chat tổng quát | Rất cao |
| Falcon LLM | 7B–40B | Dành cho nghiên cứu | QA / Analysis | Trung bình |
Cách API Hóa LLM Cục Bộ Để Sử dụng Trong Thực Tế
Để sử dụng LLM local một cách nghiêm túc thì không thể tránh khỏi API hóa.
Workflow Cơ Bản
- Host LLM server bằng Ollama / Llama.cpp
- Công khai như REST API (ví dụ:
/api/generate) - Kết nối với app công ty hoặc workflow
Thực Tế Đã Làm: Ví Dụ Xây Dựng Với Ollama
# Cài đặt Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Download mô hình
ollama pull dolphin3.0
# Khởi động server (mặc định localhost:11434)
ollama serve
Chỉ với thế này là LLM API local đã hoạt động.
Tầm Quan Trọng Của API Testing
Điều quan trọng nhất khi vận hành LLM API local là đảm bảo test hoạt động API và khả năng chịu lỗi.
Khi thực tế vận hành, tôi đã gặp phải những vấn đề sau nhiều lần:
- Độ trễ suy luận dài hơn dự kiến
- Lỗi timeout xảy ra thường xuyên
- Định dạng response thay đổi khi chuyển đổi mô hình
Nếu không xác minh trước những điều này thì sẽ gặp khó khăn lớn trong vận hành.
Quản Lý LLM API Local Bằng Apidog
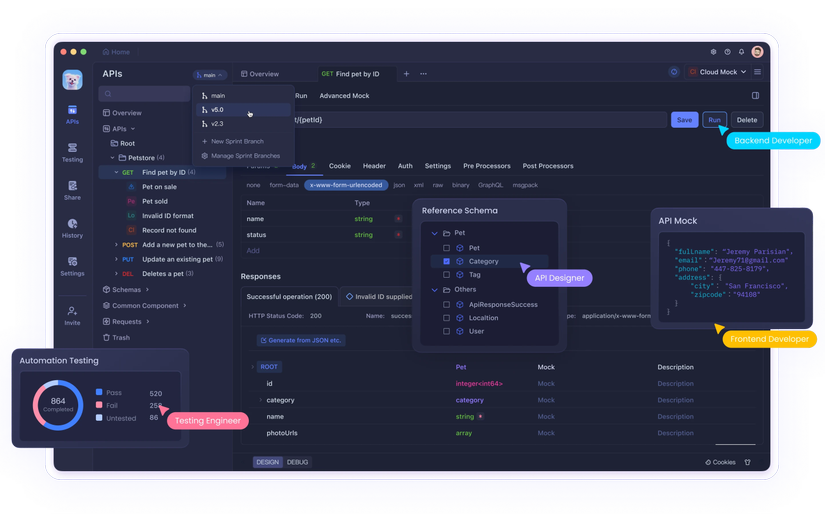
Việc test bằng cách chạy curl thủ công là không hiệu quả.
Sử dụng Apidog sẽ làm cho việc test và quản lý LLM API local trở nên cực kỳ dễ dàng.
Cách sử dụng thực tế:
- Xác minh endpoint: Đăng ký API của Ollama / LM Studio / Text Generation WebUI
- Test tự động: Tự động check độ trễ suy luận, phản hồi lỗi, timeout
- Xác nhận sự khác biệt khi chuyển đổi mô hình: Phát hiện thay đổi đặc tả request
- Quản lý tích hợp với API bên ngoài: Quản lý tập trung với OpenAI / Claude / Gemini API
Đặc biệt tiện lợi là có thể quản lý LLM API local, LLM API bên ngoài, backend API công ty trong một workspace.
Đây không phải quảng cáo mà là lựa chọn tự nhiên như một workflow thực tế.
Best Practice Vận Hành Có Thể Sử Dụng Trong Thực Tế
1. Đo Lường và Tối Ưu Độ Trễ Suy Luận
LLM local thường chậm hơn cloud API.
Đối s책:
- Sử dụng mô hình quantization (GGUF Q4_K_M v.v.)
- Tăng throughput bằng batch processing
- Tận dụng tối đa GPU memory
2. Kiểm Soát Retry Phản Hồi Lỗi
Timeout và lỗi thiếu memory không thể tránh khỏi.
Đối sách:
- Implement retry logic
- Chuẩn bị fallback (API bên ngoài)
- Ghi log lỗi chi tiết
3. Quản Lý Sự Khác Biệt Hành Vi Khi Chuyển Đổi Mô Hình
Khi thay đổi mô hình có thể định dạng response sẽ thay đổi.
Đối sách:
- Định nghĩa rõ ràng API schema
- Tự động thực thi test case
- Quản lý version triệt để
4. Tích Hợp Với Frontend・Backend
Khi tích hợp LLM API local vào hệ thống hiện có, việc sắp xếp schema là quan trọng.
Đối sách:
- Tạo OpenAPI specification
- Phát triển tiên phong bằng mock server
- Tự động hóa integration test
Xu Hướng Tương Lai Của LLM Không Giới Hạn
1. Tối Ưu Hóa MoE Nhỏ Gọn
Dưới ảnh hưởng của Mixtral, Llama3 MoE, mini MoE có thể đạt hiệu suất cao ngay cả với GPU nhỏ sẽ trở thành xu hướng chính.
2. Chuẩn Hóa Agentic / Function Calling
Khi dòng Hermes v.v. mạnh về liên kết API, LLM local cũng sẽ phổ biến "vận hành agent".
3. Tăng Tầm Quan Trọng Của LLM Local × API Test
Trong vận hành cấp doanh nghiệp, việc tạo ra tính ổn định của API (đặc biệt là API suy luận nội bộ công ty) sẽ trở nên quan trọng.
4. Phổ Biến Private Fine-tuning
Do yêu cầu không gửi dữ liệu lên cloud, việc fine-tuning nội bộ sử dụng LoRA / QLoRA sẽ trở thành điều bình thường.
Tổng Kết: LLM Cục Bộ Đã Đạt Đến Mức Thực Dụng
Năm 2025 là năm "độ hoàn thiện của LLM local đã sánh ngang với cloud".
Lựa chọn mô hình không giới hạn mở rộng hơn bao giờ hết, và tồn tại giải pháp tối ưu cho từng mục đích sử dụng.
Mô hình khuyến nghị theo mục đích:
- Coding: WizardLM / Dolphin 3.0
- Sáng tạo: MythoMax / Chronos-Hermes
- Đối thoại tổng quát・Roleplay: Nous Hermes 3
- Cấu hình thấp: Llama2 Uncensored / GPT-4All
Và đối với người thực hành, việc xử lý LLM như API, test và đảm bảo tính vận hành trở nên quan trọng hơn bao giờ hết.
Như một phương pháp để làm điều đó, việc tận dụng nhóm công cụ API bao gồm Apidog là lựa chọn tự nhiên và thực dụng cho các nhà phát triển.
Thế giới LLM local thú vị hơn tưởng tượng. Hãy thực sự thử nghiệm xem.
All rights reserved
