Deep Inside PostgreSQL: Processes, Forking và Memory Trade-off
Hôm nay, chúng ta cùng khám phá kiến trúc bên trong của PostgreSQL qua nguyên lý "Process by Connection". Tìm hiểu tác động của Fork(), Context Switching và lý do tại sao Connection Pooling (PgBouncer) là chìa khóa để tối ưu hiệu năng Database.
Nếu thấy hay, kết nối với mình tại: LinkedIn
Đọc thêm về cơ chế MVCC - Multi Version Concurrency Control trong PostgreSQL
PostgreSQL hiện nay là một trong những loại database ralational được dùng phổ biến nhất. Mình cũng từng dùng và khá yêu thích nó. Đây là một nền tảng Open source và được cập nhật liên tục. Hiện tại đang là phiên bản 18 thì phải. Nó được sinh ra để giải quyết việc high concurency giữa nhiều tác vụ Read, Write, Update.
Bài viết này mình sẽ không trình bày về các tính năng cũ hay mới của PostgreSQL, vì những cái này anh em search một cái là ra ngay, mình cùng đi sâu tìm hiểu về các nguyên lý và kiến trúc bên dưới của PostgreSQL, những thứ ảnh hưởng đến hiệu năng cũng như các vấn đề mà Postgresql phải đối mặt và giải quyết.

Có 2 nguyên lý cơ bản trong PostgreSQL, đó là Process by connection và MVCC (Multi version concurency control). Về MVVC, chúng ta đã tìm hiểu ở bài trước, còn ở bài này, chúng ta sẽ tìm hiểu về nguyên lý Process by connection, một nguyên lý mà bất cứ ai tìm hiểu về PostgreSQL cũng đều nên nắm rõ. Bắt đầu thôi.
Process by connection
Đây là nguyên lý cốt lõi của PostgreSQL, mỗi connection tới database là một process mới, không giống với Mysql, mỗi connection là một thread. Các thành phần chính:
- Postmaster: ông này có nhiệm vụ lắng nghe các connection mới từ client
- Backend process: có nhiệm vụ fork ra một process mới cho mỗi connection
- Shared memory: ông này chứa buffer cache, lock cho toàn bộ các process
- Background process: một process chạy ngầm bên dưới cho các tác vụ tự động như: autovacuum, checkpointer, …
Vòng đời của của một request
Khi chúng ta query:
SELECT * FROM users WHERE id = 1;
Client sẽ gửi một yêu cầu TCP/IP đến server PostgreSQL của chúng ta để thực hiện câu lệnh này thông qua quy trình bắt tay 3 bước tiêu chuẩn:
-
SYN: Client gửi một gói tin: Hello Server
-
SYN-ACK: Server phản hồi xác nhận gói tin: Hello Client
-
ACK: Client xác nhận kết nối
Postmaster nhận được yêu cầu kết nối, fork ra một backend process riêng biệt, không liên quan gì tới các kết nối khác.
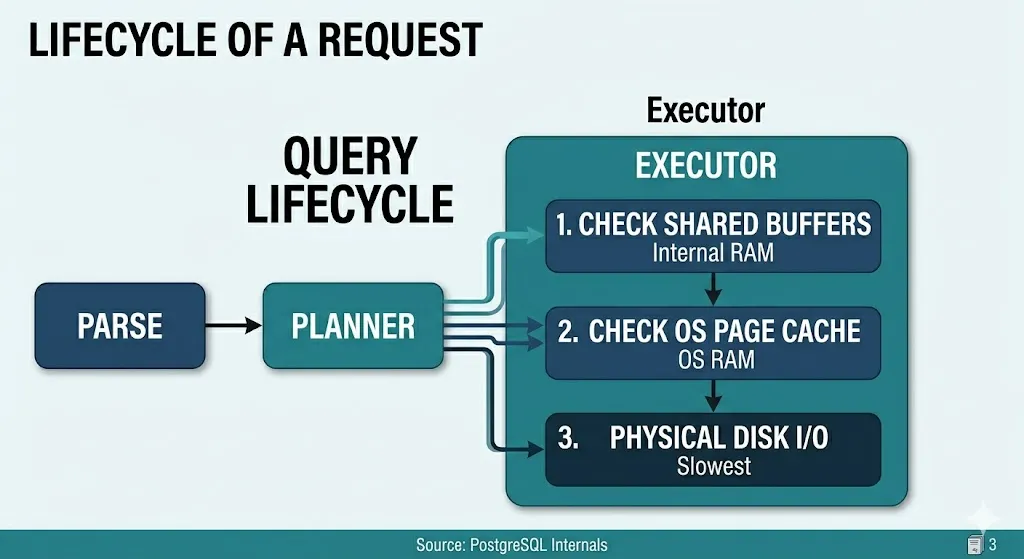
Backend process sẽ xử lý câu lệnh qua 3 bước:
-
Parse: Kiểm tra syntax của câu query rổi parse tree
-
Planner: Tạo ra execution plan, quyết định index scan, full table scan, các chiến lược join (join strategy)
-
Executor: Truy vấn được thực thi bằng cách sử dụng kế hoạch thực thi và truy cập dữ liệu thông qua trình quản lý bộ đệm của PostgreSQL. Nếu dữ liệu cần thiết không có trong bộ nhớ, nó có thể kích hoạt thao tác đọc/ghi dữ liệu từ đĩa. Trả kết quả cho client: Backend process trả kết quả thông qua socket
![image.png]()
Ưu điểm của Process by connection
Tính cô lập (Isolation)
Mỗi kết nối PostgreSQL được xử lý bởi một process riêng biệt, nên một kết nối chạy chậm hay dùng nhiều CPU sẽ không ảnh hưởng tới các kết nối khác. Nói đơn giản ví dụ như mỗi khách sẽ có một nhân viên chăm sóc khách hàng riêng, một ông mà “quậy” hoặc “đòi hỏi” tốn nhiều thời gian chỉ ảnh hưởng tới nhân viên chăm sóc khách hàng của ông này thôi, không ảnh hưởng tới khách hàng khác.
Mỗi một backend process có không gian làm việc riêng, bộ nhớ riêng và luồng xử lý riêng ở cấp độ điều hành. Vì vậy nếu một query rất nặng chiếm đến 80% CPU, thì nó chỉ làm chậm đến chính process của chính nó thay vì chen ngang các connection khác.
Đối với các hệ quản trị cơ sở dữ liệu dựa trên nguyên lý thread-base (như Mysql), nhiều kết nối sẽ phải chia sẻ chung một process lớn và các tài nguyên bên trong nó. Khi một thread bị quá tải (80% chẳng hạn), phần lập lịch CPU, tranh chấp lock hoặc nghẽn tài nguyên dùng chung làm cho các thread khác phải chờ lâu hơn. Vì thế độ trễ trung bình có thể sẽ tăng khi tải cao, nhất là khi có nhiều connection đồng thời.
Bảo mật (Security)
Với PostgreSQL, mỗi kết nối được xử lý riêng biệt. Nghĩa là khi người dùng đăng nhập, hệ thống sẽ kiểm tra xác thực, quyền truy cập và trạng thái phiên làm việc cho từng kết nối một, thay vì gom vào một chỗ chung.
Điều này giúp tăng tính bảo mật, bởi vì nếu một kết nối có vấn đề, nó chỉ ảnh hưởng đến chính phiên đó, không dễ lan sang các kết nối khác.
Nói đơn giản, nó giống như trong một căn hộ ở chung, nhưng mỗi người có một phòng riêng và một ổ khoá riêng, một phòng gặp sự cố thì các phòng khác không bị sao cả.
Với hệ thống sử dụng thread-based, nhiều kết nối có thể chia sẻ nhiều tài nguyên chung hơn, khi có quá nhiều request vào cùng một lúc, việc chia sẻ này sẽ biến thành việc tranh chấp tài nguyên, nếu có lỗi xảy ra ở phần dùng chung này thì sẽ ảnh hưởng tới nhiều connection hơn.
Khả năng mở rộng (Scalability)
PostgreSQL có thể mở rộng để phục vụ nhiều người dùng đồng thời mà vẫn giữ hiệu năng khá ổn định nếu chúng ta cấu hình hợp lý. Vì sử dụng process by connection mà:
- Mỗi connection có không gian xử lý riêng
- Một kết nối nặng không làm nghẽn toàn bộ hệ thống ngay lập tức
- Hệ thống dễ cô lập từng phiên làm việc hơn
Mỗi process đều tốn tài nguyên, như CPU và Memory. Khi số lượng connection tăng quá cao, chi phí tài nguyên cũng tăng theo. Vì vậy, dù PostgreSQL mở rộng tốt, nhưng không có nghĩa là cứ tăng nhiều connection thì hiệu năng cũng tăng.
Tính linh hoạt (Flexibility)
PostgreSQL hỗ trợ nhiều loại kết nối khác nhau:
- TCP/IP: thường dùng khi ứng dụng và database khác máy và khác mạng. Đây là kết nối phổ biến nhất vì nó linh hoạt và dễ dùng trong môi trường production, cloud, microservices. Nhược điểm là phải thêm chi phí truyền mạng, nên thường chậm hơn các kết nối nội bộ.
- Unix socket: thường dùng khi ứng dụng và database cùng nằm trên một server. Vì không phải đi qua stack TCP/IP (đóng gói gói tin, kiểm tra giao thức mạng, truyền qua stack mạng), nên độ trễ thấp hơn và ít tốn tài nguyên hơn.
- Shared Memory: Shared Memory là một cơ chế Internal IPC (Giao tiếp giữa các process) mà Postgres sử dụng để cho phép các tiến trình phụ trợ giao tiếp với nhau.. Kết nối này thì siêu nhanh vì dữ liệu được trao đổi trực tiếp qua bộ nhớ, không cần qua mạng.
Sự đánh đổi
Vì PostgreSQL sử dụng process per request, mỗi connection tới database sẽ được tạo một process riêng biệt, vì vậy mỗi connection không chỉ là “phiên làm việc”, mà còn cần thêm tài nguyên từ hệ điều hành để chạy riêng.
Điểm bất lợi là khi số lượng connection tăng cao, thì số lượng tài nguyên yêu cầu cũng tăng nhanh.
fork() là gì ?
fork() là một lệnh từ hệ điều hành, cho phép tạo một process con từ một process cha. Ban đầu, process con sẽ giống hệt process cha, sau đó PostgreSQL sẽ tách nó ra để phục vụ chạy một connection cụ thể.
Khi PostgreSQL tạo một tiến trình con (fork), hệ điều hành thực chất không sao chép toàn bộ bộ nhớ. Nó sử dụng cơ chế Copy-on-Write (CoW). Tiến trình mới “trỏ” đến vùng nhớ của tiến trình cha. Chỉ khi tiến trình mới cố gắng thay đổi điều gì đó thì hệ điều hành mới thực sự sao chép trang bộ nhớ cụ thể đó. Đây là lý do tại sao PostgreSQL có thể khởi chạy các tiến trình tương đối nhanh, mặc dù vẫn chậm hơn so với đa luồng.
Khi tạo một process mới, hệ điều hành phải chuẩn bị:
- bộ nhớ cho process
- file descriptors
- trạng thái hệ thống liên quan
- thông tin quản lý tiến trình
Dù PostgreSQL có cơ chế tối ưu kiểu “copy-on-write”, việc tạo ra một process riêng vẫn tốn nhiều chi phí hơn so với việc tạo ra một thread. Vì vậy mỗi connection trong PostgreSQL đều có overhead riêng.
Overhead là một loại chi phí phục vụ cho các hoạt động vận hành của process mà không liên quan đến các chi phí trực tiếp để xử lý yêu cầu từ client.
Kích thước tài nguyên của mỗi process được cấp phát phụ thuộc vào:
- phiên bản PostgreSQL
- cấu hình server
- workload
- extension
- hệ điều hành
CPU Context Switching
Khi CPU đang chạy một process hoặc một thread, rồi phải chuyển sang chạy process/thread khác, nó cần lưu trạng thái cũ, và nạp trạng thái mới. Trạng thái đó bao gồm các thanh ghi, con trỏ lệnh, và một phần thông tin thực thi hiện tại.

Việc chuyển đổi này gọi là Context Switching, ví dụ với 2 process A và process B, xảy ra khi process A bị Block, ví dụ như đang chờ I/O, hoặc khi nó hết time slice (hết lượt CPU được cấp). Có 3 tình huống phổ biến:
- Process A đang chạy nhưng phải chờ I/O, như phải đọc ổ đĩa, mạng, hoặc chờ dữ liệu. Khi đó Process A tự động chuyển sang trạng thái waiting/block.
- Process A chạy hết thời gian CPU được cấp, hệ điều hành dừng nó lại để nhường CPU cho process khác.
- Có process có mức độ ưu tiên cao hơn process hiện tại, nên scheduler quyết định đổi ngữ cảnh.
Nếu server PostgreSQL chỉ có 8 core CPU, mà có hàng nghìn kết nối database tới cùng một lúc, hệ điều hành không thể chạy hết tất cả ở cùng một thời điểm, nó phải chia thời gian CPU rất nhỏ cho từng kết nối. Nên sẽ xảy ra kiểu:
- chạy process A (connection) một lát
- dừng lại
- lưu trạng thái của A
- chuyển sang process B (connection)
- và cứ thế cho các connection khác
Mỗi lần chuyển như thế đều mất thời gian. CPU không những phải làm những việc “hữu ích”, mà còn phải đảm nhận thêm nhiệm vụ chuyển đổi giữa các task. Khi số lượng kết nối quá lớn, CPU mất rất nhiều thời gian chỉ để chuyển qua lại giữa các process/thread, thay vì làm nhiệm vụ chính xử lý query, làm cho hiệu năng giảm.
Hãy tưởng tượng một đầu bếp chỉ có 1 cái chảo, nhưng phải nấu cho 100 khách. Nếu cứ đảo qua đảo lại giữa các món ăn, thì sẽ mất rất nhiều thời gian chỉ cho việc đảo món, thay vì nấu xong từng món, CPU cũng như vậy.
Disk contention là gì?
Disk contention nghĩa là nhiều request cùng tranh nhau đọc ghi ổ đĩa. Database rất phụ thuộc vào tốc độ đọc ghi của disk vì không phải lúc nào dữ liệu cũng có ở trong RAM, khi cache không đủ hoặc dữ liệu chưa có trong bộ nhớ, hệ thống phải xuống disk để lấy.
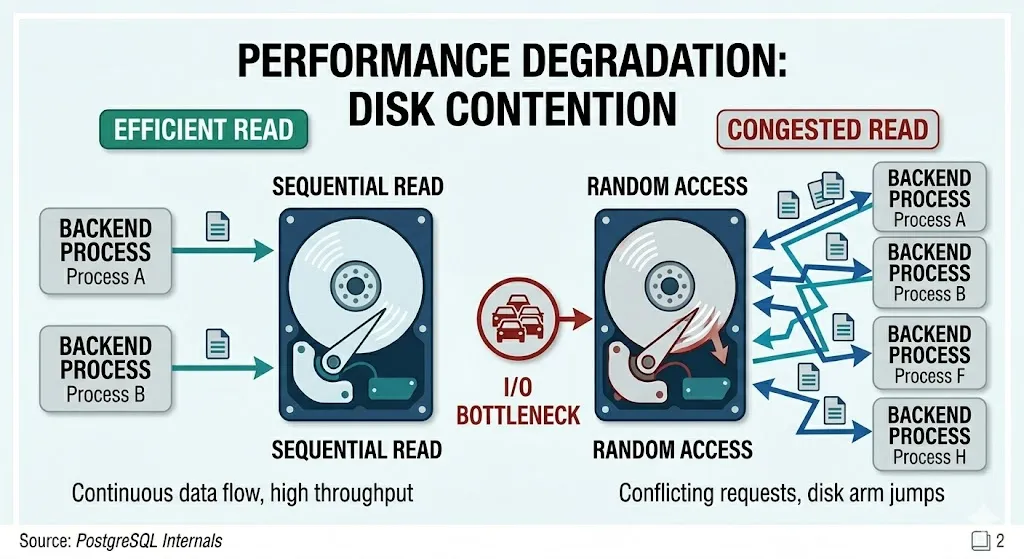
Khi quá nhiều request cùng tới một lúc, disk bị kẹt do phải phục vụ liên tục cho nhiều yêu cầu khác nhau (bị hành =))).
Nếu hệ thống chỉ xử lý một vài request, nó có thể đọc dữ liệu theo cách khá liên tục, gọi là sequential read (đọc tuần tự). Cách này nhanh vì ổ đĩa sẽ đọc các khối dữ liệu gần nhau trong một lượt.
Nhưng khi hàng trăm request tới cùng một lúc, mỗi request lại cần tới dữ liệu ở vị trí khác nhau, lúc này disk phải nhảy qua nhảy lại nhiều chỗ, gọi là random read (đọc ngẫu nhiên), bị chậm hơn vì ổ đĩa không còn đọc liền mạch nữa.
Hãy tưởng tượng cách làm việc của người quản lý thư viện, nếu chỉ có vài người hỏi sách ở gần nhau, người quản lý chỉ cần đi đến khu vực kệ sách đó là xong. Nhưng nếu mỗi người yêu cầu sách ở các kệ khác nhau, người quản lý phải đi khắp thư viện, mất rất nhiều thời gian.
Connection pooling
Với PostgreSQL, connection pooling gần như là bắt buộc khi hệ thống của chúng ta có nhiều request hoặc nhiều iíntance ứng dụng. Lý do cốt lõi là PostgreSQL sử dụng mô hình process per connection, nên nếu app của bạn mở/đóng connection liên tục, database sẽ tốn rất nhiều công sức chỉ để tạo, quản lý, và dọn connection thay vì làm việc hữu ích như query câu lệnh.
Vấn đề là, mỗi lần app mở connection mới, PostgreSQL phải thực hiện handshake, tạo backend process, cấp tài nguyên, khi câu lệnh kết thúc thì giải phóng nó. Việc này tạo ra connection churn: connection đến rồi đi liên tục, rất tốn CPU, RAM, và làm tăng độ trễ.
Nếu số lượng connection quá nhiều, bạn còn gặp vấn đề với context swtching, áp lực bộ nhớ và hàng đợi để xử lý dài hơn. Điều này đặc biệt tệ hơn khi hệ thống có traffic tăng đột ngột, hoặc có nhiều request ngắn, vì database phải phục vụ việc “kết nối” nhiều không kém việc “truy vấn”.
Vậy là PostgreSQL đã nghĩ ra một cách, tại sao cứ phải tạo mới, rồi xoá các kết nối tiêu tốn nhiều thời gian kia, thay vì có thể tạo trước một số lượng connection, và tái sử dụng nó. Bắt đầu ngon rồi.
Connection pooling (hồ chứa các kết nối) giữ sẵn một số connection “ấm” để có thể tái sử dụng. Khi request đến, app lấy sẵn một connection trong connection pooling, chạy query rồi trả lại pool thay vì tạo connection mới từ đầu. Cách này giảm đáng kể chi phí handshakes (TCP/IP) và chi phí tạo process mới.
Nói đúng hơn, connection pooling chuyển bài toán từ mỗi request tạo ra một connection riêng thành bài toán nhiều request dùng chung một nhóm connection. Điều này cải thiện đáng kể throughput và giảm latency cho hệ thống.
PostgreSQL không dùng thread per connection, điều này mang lại cho bạn nhiều lợi thế về cô lập và ổn định, nhưng cái giá phải trả là mỗi connection đều nặng hơn, có nhiều request cùng tới thì tài nguyên phải cấp phát sẽ phình to ra rất nhanh.
Vì vậy, với PostgreSQL, connection pooling không chỉ là tối ưu thêm, mà thường là cách để giữ hệ thống sống khoẻ khi có nhiều user sử dụng đồng thời hoặc nhiều instance ứng dụng.
Khi nào pooling thực sự quan trọng
Pooling rất hữu ích khi hệ thống có những đặc điểm sau:
- Nhiều request ngắn, ví dụ các API của web
- App được scale lên nhiều instance cùng kết nối tới chung một database
- Traffic tăng đột ngột theo burst
- Ứng dụng serverless hoặc microservices, nơi mà việc connect/disconnect xảy ra thường xuyên
Trong các trường hợp này, PostgreSQL dễ bị ngợp nếu không dùng pooling, mặc dù request không nặng.
Có một sự thật mà nhiều người bị nhầm: pooling không làm cho câu query của bạn nhanh hơn. Nếu query của bạn đang scan cả bảng, thiếu index, hoặc bị lock, pooling chỉ giúp bạn không mất chi phí kết nối, nó không thay thế cho tối ưu SQL.
Nói cách khác, pooling giải quyết chi phí kết nối, còn index, query plan, va schema design mới giải quyết chi phí truy vấn.
Công thức tính số lượng connection pooling
Với PostgreSQL, số lượng connection trong pool nên thoả mãn 3 điều kiện sau:
- Không vượt quá số worker/process mà DB và CPU chịu được
- Không làm RAM bị đầy do mỗi process/connection tốn bộ nhớ riêng
- không làm query xếp hàng quá lâu
Không có công thức nào là hoản hảo cả. Mình có thể đề nghị một công thức:
**pool_size** = min(**cores** * 2, floor((**RAM_for_pool_MB**) / **memory_per_connection_MB**), **max_db_connections** - reserve)
Trong đó:
- RAM_for_pool_MB : phần RAM dành riêng cho connection, không phải toàn bộ RAM của server
- memory_per_connection_MB: dung lượng một process để chạy connection, cái này nên đo thực tế thay vì đoán mò
- reserve: nên chứa 5 đến 20 connections cho admin, monitoring, maintenance
Ví dụ, database có:
- 4 cores
- 8GB RAM nhưng chỉ dành 1GB RAM cho connection
- Mỗi process chạy connection có size là 10MB
- reserve 10 connections cho admin
Khi đó, pool_size = min (4 *2, 1024/10, 100 -10) = 8
Đây mới chỉ là cấu hình khởi đầu, sau đó cần đo thực tế bằng chạy load test và monitoring, vì pool_size tốt nhất phụ thuộc vào workload của hệ thống.
Hai kiểu pooling
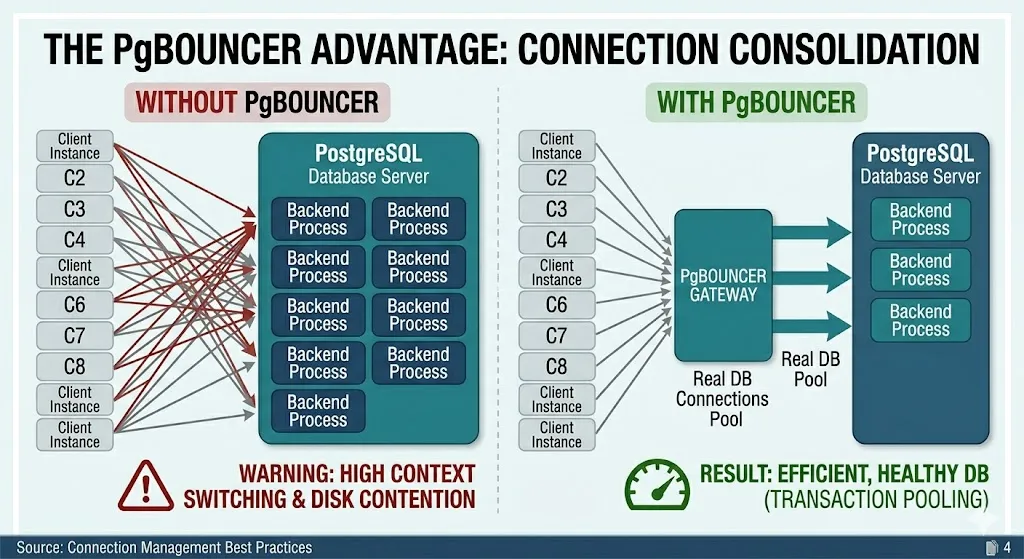
Có 2 kiểu pooling phổ biến: application-pool và PgBouncer. Application-pool giữ connection bên trong từng app instance, còn PgBouncer đứng giữa app và PostgreSQL để gom nhiều client lại và giới hạn số backend connection thật sự tới database.
Đơn giản hơn là :
- App pool giúp cho ứng dụng không phải reconnect liên tục
- PgBouncer giúp toàn bộ hệ thống không bơm quá nhiều connection vào database
Vì sao chỉ App pool thôi chưa đủ?
Nếu bạn có 1 ứng dụng duy nhất kết nối vào database, thì app pool đã là khá ổn. Nhưng khi bạn có nhiều app, mỗi app có nhiều instance (pod), autoscaling, microservices, thì mỗi instance lại mở một pool riêng. Tổng số connection thực tế đổ vào PostgreSQL có thể cộng dồn rất lớn và vượt nhanh giới hạn mà database chịu được.
Ví dụ:
- bạn có 20 instances
- mỗi instance tạo ra một pool riêng có 10 connections
- Tổng cộng có 200 connections thật vào database.
và PostgreSQL không biết gì về 20 apps, nó chỉ thấy có 200 backend connections.
Tại sao PgBouncer hữu ích hơn
Thì PgBouncer đóng vai trò như một cổng vào phía trước PostgreSQL. Nó giữ một số ít connection thật đến database và cho rất nhiều client dùng chung luồng đó, đặc biệt hiệu quả với kiểu transaction pooling. Điều này giúp giảm tải tạo process, giảm memory usage, và tránh connection storm khi traffic tăng đột biến.
Một lợi ích rất thực tế là nếu app có 1000 client logic nhưng chỉ cần 20-25 backend connections thật, PostgreSQL sẽ khoẻ hơn rất nhiều.
Các pooling mode của PgBouncer
PgBouncer có 3 mode chính:
-
Session pooling: gán kết nối với database cho toàn bộ vòng đời của client( cái nà đơn giản nhất nhưng kém hiệu quả nhất)
-
Transaction pooling: chỉ gán kết nối trong thời gian transaction
-
Statement pooling: mỗi query dùng một connection khác nhau.
Trong đó, transaction pooling thường là lựa chọn hợp lý nhất cho web workload vì connection chỉ bị giữ trong lúc transaction đang chạy, hết transaction thì sẽ trả lại cho pool.
Điểm cần nhớ là statement pooling rất mạnh nhưng không hợp với multi-statement transaction, còn session pooling sẽ an toàn hơn nhưng lại ít tiết kiệm connection hơn.
Kết luận
Nếu bạn đang chạy PostgreSQL cho production và có nhiều request, nhiều instance, hoặc autoscaling, thì dùng connection pooling gần như là lựa chọn bắt buộc.
Mặc dù PostgreSQL xử lý tốt các kết nối đồng thời cao, nhưng giới hạn của nó thường chỉ ở mức vài trăm kết nối hoạt động trước khi việc chuyển đổi ngữ cảnh làm giảm hiệu suất đáng kể.
Hiểu về PostgreSQL giúp bạn dễ dàng debug, thấu hiểu hệ thống, cài đặt chuẩn xác làm cho ứng dụng của bạn dễ dàng mở rộng mà không bị vấn đề nào liên quan đến cơ sở dữ liệu.
Bài viết này cũng được mình dịch sang tiếng Anh trên blog substack của mình.
Mình viết lại những điều này như một cách để ghi nhớ hành trình làm nghề của mình. Nếu bạn cũng đang làm backend, devops hoặc cloud, hy vọng những chia sẻ này có thể giúp bạn một chút gì đó. Còn nếu có chỗ nào mình hiểu chưa đúng, mình vẫn luôn sẵn sàng học thêm.
All rights reserved
