FullText Search - Đơn giản mà hữu ích!!
Bài đăng này đã không được cập nhật trong 4 năm

LỜI NÓI ĐẦU
Là một lập trình viên mà đã từng phải thao tác với cơ sở dữ liệu, hay đơn thuần là đã từng là một trang web bán hàng ,chắc hẳn các bạn đã từng nghe qua về khái niệm “Full text search”.
Khái niệm này đã được định nghĩa khá cụ thể và đầy đủ trên wikipedia. Nói một cách đơn giản, “Full text search” là kĩ thuật tìm kiếm trên “Full text database”, ở đây “Full text database” là cơ sở dữ liệu chứa “toàn bộ” các kí tự (text) của một hoặc một số các tài liệu, bài báo.. (document), hoặc là của websites.
Trong bài viết này, mình sẽ giới thiệu về Full Text Search, từ khái niệm đến ứng dụng thực tiễn của kĩ thuật này.
Introduction
Chắc hẳn các bạn đã từng dùng qua một kĩ thuật tìm kiếm rất cơ bản, đó là thông qua câu lệnh LIKE của SQL.
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern;
==> Sử dụng LIKE, các bạn sẽ chỉ phải tìm kiếm ở column đã định trước, do đó lượng thông tin phải tìm giới hạn lại chỉ trong các column đó.
Câu lệnh LIKE cũng tương đương với việc bạn matching pattern cho “từng” chuỗi của từng dòng (rows) của field tương ứng, do đó về độ phức tạp sẽ là tuyến tính với số dòng, và số kí tự của từng dòng, hay chính là “toàn bộ kí tự chứa trong field cần tìm kiếm”. Do đó sử dụng LIKE query sẽ gặp các vấn đề:
- Không chính xác
- Độ nhiễu cao
- Từ đồng nghĩa (synonyms)
- Từ cấu tạo bằng chữ đầu của cụm từ (acronym)
-
Performance không tốt (Tốc độ truy vấn chậm, ‘%keyword%’ không dùng index)
-
Vấn đề với tìm kiếm tiếng Việt có dấu và không dấu
Như vậy chúng ta cần một kĩ thuật tìm kiếm khác, tốt hơn LIKE query, mềm dẻo hơn, tốt về performance hơn, đó chính là Full text search.
*, Cơ bản về kĩ thuật Full text search Về mặt cơ bản, điều làm nên sự khác biệt giữa Full text search và các kĩ thuật search thông thường khác chính là “Inverted Index”. Vậy đầu tiên chúng ta sẽ tìm hiểu về Inverted Index.
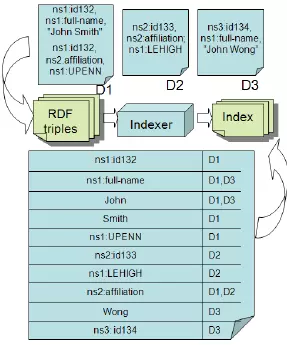
Inverted Index là gì
==> Inverted Index là kĩ thuật thay vì index theo đơn vị row(document) giống như mysql thì chúng ta sẽ tiến hành index theo đơn vị term. Cụ thể hơn, Inverted Index là một cấu trúc dữ liệu, nhằm mục đích map giữa term, và các document chứa term đó Hãy xem ví dụ cụ thể dưới đây, chúng ta có 3 documents D1, D2, D3
D1 = "This is first document"
D2 = "This is second one"
D3 = "one two"
Inverted Index của 3 documents đó sẽ được lưu dưới dạng như sau:
"this" => {D1, D2}
"is" => {D1, D2}
"first" => {D1}
"document" => {D1}
"second" => {D2}
"one" => {D2, D3}
"two" => {D3}
Từ ví dụ trên các bạn có thể hình dung được về thế nào là Inverted Index. Vậy việc tạo index theo term như trên có lợi thế nào? Việc đầu tiên là inverted index giúp cho việc tìm kiếm trên full text database trở nên nhanh hơn bao giờ hết.
Hãy giả sử bạn muốn query cụm từ “This is first”, thì thay vì việc phải scan từng document một, bài toán tìm kiếm document chứa 3 term trên sẽ trở thành phép toán union của 3 tập hợp (document sets) của 3 term đó trong inverted index.
{D1, D2} union {D1, D2} union {D1} = {D1}
Một điểm lợi nữa chính là việc inverted index cực kì flexible trong việc tìm kiếm. Query đầu vào của bạn có thể là “This is first”, “first This is” hay “This first is” thì độ phức tạp tính toán của phép union kia vẫn là không đổi.
Như vậy chúng ta đã hiểu phần nào về khái niệm “Thế nào là Inverted Index”.
Trong phần tiếp theo chúng ta sẽ tìm hiểu về cụ thể về cách implement của inverted index, và ứng dụng của inverted index vào việc tìm kiếm thông tin thông qua các kĩ thuật chính như:
+, Tokenization technique (thông qua N-Gram hoặc Morphological Analysis)
+, Query technique
+, Scoring technique.
==> Qua bài viết đầu tiên, các bạn đã nắm được tại sao Inverted Index lại được sử dụng để tăng tốc độ tìm kiếm trong một “Full Text Database”. Đồng thời ở ví dụ của phần một, các bạn cũng đã thấy, để tạo ra Inverted Index thì các bạn phải tách được một string ra thành các term, sau đó sẽ index string đó theo term đã tách được.
Chính vì thế việc tách string, hay còn gọi là Tokenize là một bài toán con quan trọng nằm trong bài toán lớn của Full Text Search. Ở bài này, chúng ta sẽ tìm hiểu về 2 kĩ thuật Tokenize cơ bản là:
- N-gram
N-gram là kĩ thuật tokenize một chuỗi thành các chuỗi con, thông qua việc chia đều chuỗi đã có thành các chuỗi con đều nhau, có độ dài là N.
Về cơ bản thì N thường nằm từ 1~3, với các tên gọi tương ứng là unigram(N==1), bigram(N==2), trigram(N==3). Ví dụ đơn giản là chúng ta có chuỗi “good morning”, được phân tích thành bigram:
"dinh ngoc nam" => {"di","in","nh","h ", " n","ng","go","oc", "c ", "na", "am"}
Từ ví dụ trên các bạn có thể dễ dàng hình dung về cách thức hoạt động của N-gram. Để implement N-gram, chỉ cần một vài dòng code, như ví dụ viết bằng js =)) như sau:
var Ngram = function (src, ngram)
{
var _ngram = [];
if (src.length >= ngram)
{
for (var index = 0;index <= src.length - ngram + 1;index ++)
{
_ngram.push(src.split(index,index + ngram))
}
}
return _ngram;
}
- Morphological Analysis
Định nghĩa của MA khá dài nên mình sẽ không nói chi tiết ở bài viết,các bạn có thể tham khảo tại
-> https://en.wikipedia.org/wiki/Morphological_analysis_(problem-solving)
Về cơ bản thì MA là một kĩ thuật phổ biến trong xử lý ngôn ngữ tự nhiên (Natural Language Processing). Morphological chính là “cấu trúc” của từ, như vậy MA sẽ là “phân tích cấu trúc của từ”, hay nói một cách rõ ràng hơn, MA sẽ là kĩ thuật tokenize mà để tách một chuỗi ra thành các từ có ý nghĩa. Ví dụ như cũng cụm từ “dinh ngoc nam” ở trên, chúng ta sẽ phân tích thành:
"dinh ngoc nam" => {"dinh", "ngoc", "nam"}
==> Để có được kết quả phân tích như trên, ngoài việc phải sở hữu một bộ từ điển tốt (để phân biệt được từ nào là có ý nghĩa, và thứ tự các từ thế nào thì có ý nghĩa), MA phải sử dụng các nghiên cứu sâu về xử lý ngôn ngữ tự nhiên, mà mình sẽ không đi sâu ở đây (yaoming).
Trên đây là những lý thuyết căn bản về FTS mà mình muốn giới thiệu tới các bạn,hy vọng nó sẽ giúp ích 1 phần nào đó những thấc mắc của các bạn ^^!.
Tài liệu tham khảo :
http://dev.mysql.com/doc/refman/5.7/en/fulltext-natural-language.html
All rights reserved
