Tìm hiểu về Simple HTML Dom
Bài đăng này đã không được cập nhật trong 2 năm
Simple Html Dom là thư viện của Php giúp cho việc chúng ta có thể lấy các thuộc tính của các thẻ HTML trong 1 website. Chúng ta có thể lấy trực tiếp thông tin từ link web hoặc là từ 1 chuỗi, đồng thời ta có thể lấy về, và sửa đổi nội dung. Nghe có vẻ như kiểu dễ dàng lấy thông tin từ 1 trang web nào đó về cho web của mình vậy  . Chúng ta sẽ thử dùng bộ thư viện này để lấy thông tin từ trang Viblo nhé. Nào bắt đầu thôi.
. Chúng ta sẽ thử dùng bộ thư viện này để lấy thông tin từ trang Viblo nhé. Nào bắt đầu thôi.
Cài đặt
Cài đặt có thể có nhiều cách đơn cử là các bạn down file zip tại đây hoặc có thể dùng qua thư viện của composer. Ở đây chúng ta sẽ dùng bằng cách thứ 2.
{
"name": "huynguyen/learn_simple_html_dom",
"require-dev": {
"sunra/php-simple-html-dom-parser": "v1.5.2"
},
"authors": [
{
"name": "Huy Nguyen",
"email": "nguyen.quang.huy@framgia.com"
}
],
"require": {
"sunra/php-simple-html-dom-parser": "v1.5.2"
}
}
Để sử dụng được thì ta cần import thư viện cũng như dùng nó. Để dùng thì ta cần khai báo như sau
<?php
require __DIR__ . '/vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;
Đọc và lấy thông tin từ website
Để đọc thông tin chuyển sang định dạng single_html_dom thì có 2 cách. 1 là đọc trực tiếp từ link, 2 là lấy từ chuỗi string có định dạng HTML. Cách đọc trực tiếp từ link web
$dom = HtmlDomParser::file_get_html($link);
Cách đọc từ chuỗi string
$dom = HtmlDomParser::str_get_html($content);
Ở đây ta sẽ dung cách thứ 2, và để lấy chuỗi từ 1 link web ta sử dụng curl Ta sẽ viết 1 hàm để đọc từ 1 link web sau đó chuyển sang single_html_dom
function getDom($link)
{
$ch = curl_init($link);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);// Khi thực thi lệnh sẽ k view ra trình duyệt mà lưu lại vào 1 biến kiểu string
$content = curl_exec($ch);
curl_close($ch);
$dom = HtmlDomParser::str_get_html($content);
return $dom;
}
Ở đây tại sao chúng ta dùng curl, theo ý kiến cá nhân của người viết thì dùng curl hỗ trợ nhiều cái, như kiểu mình có thể giả lập được là đang đăng nhập dùng bằng trình duyệt nào, truyền session hay cookie các kiểu nên vượt được qua vài web chặn bot
Thử lấy thông tin các bài viết và link từ trang Viblo
Nào chúng ta bắt tay vào để thử lấy danh sách các bài viết và chi tiết các bài viết nhé.
Đầu tiên chúng ta ngắm qua trang web viblo. Vì khi chuyển sang dạng single_html_dom ta có thể dễ dàng chọn đến từng đối tượng bằng cách xác định các thể class giống như dùng trong jquery vậy. Đầu tiên ta ngắm qua web site viblo nào.
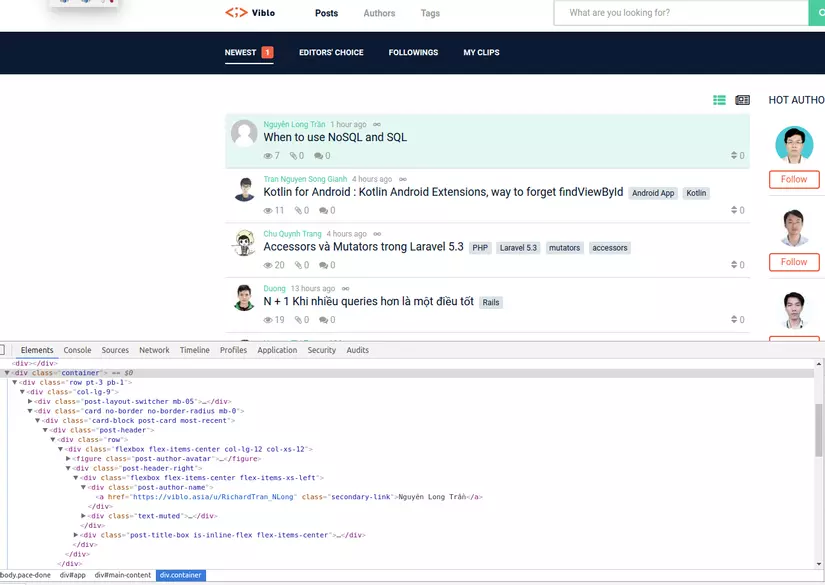 Vậy để lấy list các link ta phải đi từ class container rồi đến các thẻ a có trong class là card-block. Như ở jquery, nếu đường dẫn càng chi tiết thì càng chính xác. Vậy để lấy các link ta dùng như sau:
Vậy để lấy list các link ta phải đi từ class container rồi đến các thẻ a có trong class là card-block. Như ở jquery, nếu đường dẫn càng chi tiết thì càng chính xác. Vậy để lấy các link ta dùng như sau:
function getList()
{
$dom = getDom(https://viblo.asia/);
foreach ($dom->find('.container .col-lg-9 .post-title-box a.link') as $link) {
echo $link->href . '<br>';
}
}
Và kết quả chúng ta có là:
https://viblo.asia/RichardTran_NLong/posts/gEmROxlLKpv
https://viblo.asia/gianhTNS/posts/eXoKWkpyKLO
https://viblo.asia/chu.quynh.trang/posts/rNkKxxjBKlm
https://viblo.asia/Ngo_Duong/posts/gkyzEoDZRnv
https://viblo.asia/tieumanthau/posts/VXozZdreRqj
https://viblo.asia/dang.quyet.tien/posts/JlkRymMVRZW
https://viblo.asia/vigov5/posts/mDYGDPLVGpx
https://viblo.asia/nguyen.phuong.lan/posts/jvlKaqeaKVr
https://viblo.asia/pham.viet.anh/posts/lPXzgajYRAg
https://viblo.asia/Chym/posts/jOxGdqrXRdm
https://viblo.asia/hoangmirs/posts/BMvRpNmrzwY
https://viblo.asia/tran.xuan.thien/posts/aWeGmgjkKBD
https://viblo.asia/nguyen.van.long/posts/EyORkbEEGqB
https://viblo.asia/manhnv118/posts/jvlKaqMNKVr
https://viblo.asia/ho.quoc.hai/posts/pxvGokpyGLd
https://viblo.asia/luc/posts/ZalGrNXvGqX
https://viblo.asia/tuanva83/posts/WkXzMpnmKba
https://viblo.asia/pham.xuan.lu/posts/oaOzbxrmREx
https://viblo.asia/jimmytr.156/posts/XWkKAvxpzjy
https://viblo.asia/datnq/posts/PqORvNpvRAB
Đấy là ta lấy link, còn lấy tiêu đề thì sao? Ta có thể thay **$link->href **bằng **$link-innertext ** Vậy từ việc lấy từng link ta có thể dễ dàng lấy các bài chi tiết khác rồi phải không? Vậy toàn bộ source chúng ta cần là như sau:
<?php
require __DIR__ . '/vendor/autoload.php';
use Sunra\PhpSimple\HtmlDomParser;
class ViobloTraining {
private $url;
public function __construct($link)
{
$this->url = $link;
}
private function getDom($link)
{
$ch = curl_init($link);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);// Khi thực thi lệnh sẽ k view ra trình duyệt mà lưu lại vào 1 biến kiểu string
$content = curl_exec($ch);
curl_close($ch);
$dom = HtmlDomParser::str_get_html($content);
return $dom;
}
public function getList()
{
$dom = $this->getDom($this->url);
foreach ($dom->find('.container .post-title-box a.link') as $link) {
echo $link->innertext . '<br>';
}
}
}
$a = new ViobloTraining('https://viblo.asia');
$a->getList();
Tổng kết
Bài viết này mình giới thiệu qua các bạn về cách convert html string sang dom từ đó có thể dễ dàng lấy thông tin hay các thuộc tính của nó. Tuy nhiên cách này không sử dụng được cho những trang phải đăng nhập hay sử dụng captcha. Chỉ là lấy thông tin các báo mạng thì có lẽ ổn. Bài viết thuộc bản quyền Viblo
All rights reserved
