Building a simple Recommendation system
Bài đăng này đã không được cập nhật trong 4 năm
Walking throgh every E-Comerce website, each time watching a item/product that you intertested in, you will see a section with label "Items you may like" or just simple "Related items" That's recommended items which has made from combining of your activities and current data set of system. There're some interesting researches have shown that effective recommendation can boost up 15-20% selling items in E-Commerce website Recommended items on an E-Commere site alwasy place on a limited area but building it is not an easy task In this post, I just want to mentiond about concept and making a simple recommendation system through some Ruby script and I hope that everyone can understand how recommendation system works
1. Context
Let image that you're going to build a streaming service like Netflix or Hulu and you need to show to users some related movies for them to chose. Each time people watch a movies and give feedback about it through rating system like (IMDB)[www.imdb.com], we have a dataset like this
RATINGS = {
'John': {
'Kong': 7.0,
'John Wick': 7.5,
'Logan': 6.0,
'Split': 5.5,
'Moana': 6.5,
'La La La Land': 8.0
},
'Lee': {
'Kong': 6.5,
'John Wick': 5.0,
'Logan': 4.5,
'Split': 4,
'La La La Land': 6.0,
'Moana': 7.0
},
'Jacob': {
'Kong': 6.0,
'John Wick': 5.0,
'Split': 7.0,
'La La La Land': 8.0
},
'Sarah': {
'John Wick': 7.0,
'Logan': 6.0,
'La La La Land': 9.5,
'Split': 8.0,
'Moana': 5.0
},
'Prince': {
'Kong': 6.0,
'John Wick': 8.0,
'Logan': 5.0,
'Split': 6.0,
'La La La Land': 7.0,
'Moana': 5.0
},
'Kevin': {
'Kong': 7.0,
'John Wick': 8.0,
'La La La Land': 7.0,
'Split': 10.0,
'Moana': 7.5
},
'Jack': {
'John Wick': 9.0,
'Moana': 4.0,
'Split':8.0
}
}
Now we got all the rating data from some users, let start to build recommendation system
2. Finding Similarities
In the real world, there're many way to chose key factors for recommendation from previous buy/view item to shopping trends of user ... However, in this article, I will try to produce recommended items based on similarities based on two main method: Euclidean distance and Pearson correlation
2.1 Euclidean distance
Let start by comparing two movies: 'John Wick' and 'Split'
This chart will show how people provide rating for two movies
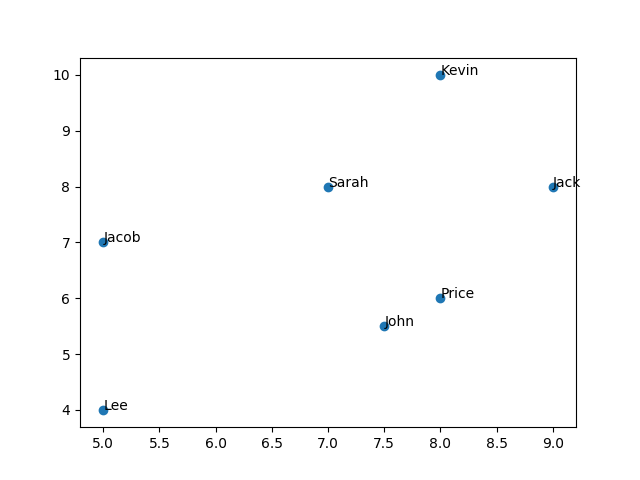 From above figure, we can see the distance among user rating which is called preference space. The closer people are in the preference space, the more similar their preference are.
To calculate Euclidean distance, we need to make a formular which can create a number that can represent for whole dataset
From above figure, we can see the distance among user rating which is called preference space. The closer people are in the preference space, the more similar their preference are.
To calculate Euclidean distance, we need to make a formular which can create a number that can represent for whole dataset

def euclidean_distance data, ref_1, ref_2
# return 0 if ref_1 or ref2_ not exist in data
return 0 unless data[ref_1] || data[ref_2]
#Get the common items
similar = []
data[ref_1].each do |item_key, item_val|
if data[ref_2][item_key]
similar.push item_key
end
end
# return 0 if there're no common
return 0 if similar.length == 0
# Sum all squares of dirrerences
sum_squares_diff = data[ref_1].map do |k, v|
next unless data[ref_2]
(data[ref_1][k] - data[ref_2][k])**2
end.compact.sum
1/(1 + sum_squares_diff)
end
In original formular, the value of preference space is unlimited, however, sometimes it too big so it's much better if we set a range from 0 to 1 for Euclidean Distance
If returned value is more close to 1, it means two sub sub data have identical preferences.
After trying to compare John and Lee ratings, here's what we have
2.4.0 :003 > euclidean_distance(RATINGS, :John, :Lee)
=> 0.06153846153846154
2.2 Pearson Correlation Score
A slightly more sophisticated way to determine the similarity between people interests is to use Pearson correlation coefficient. This method mearsures how well two sets of data fit on a straight line instead of comparing distance like Euclidean method.
So the formular is more complicated than above method but it tends to give better results in situations where the data isn't well normalized.
To visualize this method, let see the straight line in below chart with X and Y axis are rating valuesnfrom John and Lee
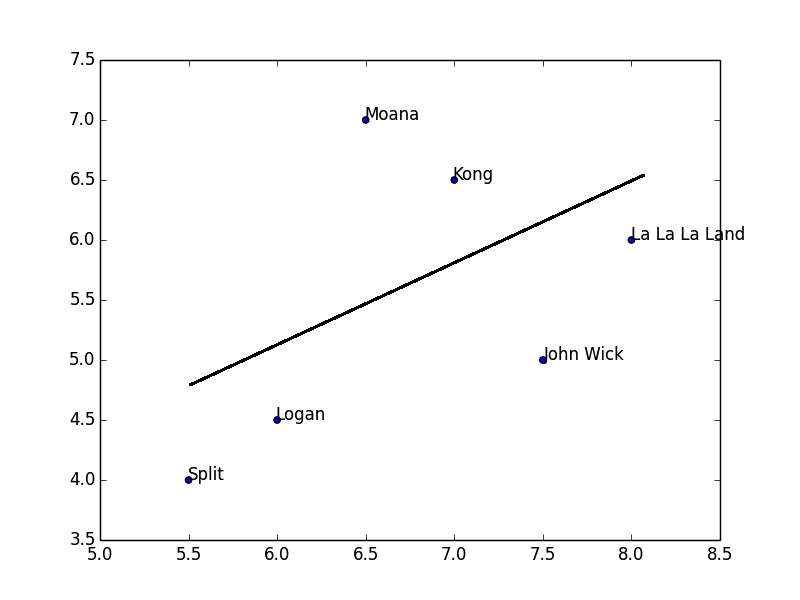 In this chart, instead of comparing between films., we change to compare among users and the straight line is called best-fit line because it comes as close to all the points on chart
If two users has the same ratings for every movies, this line would be diagonal and would touch every items in the chart, giving a perfect correlation score at 1.
One interesting aspect of using Pearson score is grade inflation. In this figure, John tends to give higher scores than Lee to the fit line trends to close to X-axis(John) more than Y-axis(Lee)
In this chart, instead of comparing between films., we change to compare among users and the straight line is called best-fit line because it comes as close to all the points on chart
If two users has the same ratings for every movies, this line would be diagonal and would touch every items in the chart, giving a perfect correlation score at 1.
One interesting aspect of using Pearson score is grade inflation. In this figure, John tends to give higher scores than Lee to the fit line trends to close to X-axis(John) more than Y-axis(Lee)
OK, it seems we the fundamentals of Pearson, now let move to headache part: Math and Programming
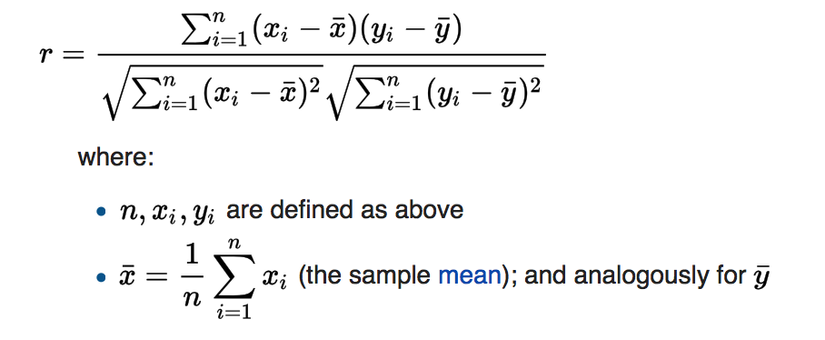
def pearson_correlation data, ref_1, ref_2
# return 0 if ref_1 or ref2_ not exist in data
return 0 unless data[ref_1] || data[ref_2]
#Get the common items
similar = []
data[ref_1].each do |item_key, item_val|
if data[ref_2][item_key]
similar.push item_key
end
end
#counting number of common items
item_num = similar.length
# return 0 if there're no common
return 0 if item_num == 0
#Add up all common item rating
sum_ref_1 = similar.map{|c_i| data[ref_1][c_i] }.sum
sum_ref_2 = similar.map{|c_i| data[ref_2][c_i] }.sum
#Add up all square of common item rating
sum_square_ref_1 = similar.map{|c_i| data[ref_1][c_i]**2 }.sum
sum_square_ref_2 = similar.map{|c_i| data[ref_2][c_i]**2 }.sum
#Sum all the products of common rating
products_sum = similar.map{|c_i| data[ref_1][c_i]*data[ref_2][c_i]}.sum
#Calculate Pearson Score
num = products_sum - sum_ref_1*sum_ref_2/item_num
den = Math.sqrt((sum_square_ref_1 - sum_ref_1**2/item_num)*
(sum_square_ref_2 - sum_ref_2**2/item_num))
return 0 if den == 0
num/den
end
This method will return a value between -1 and 1. If rerturned value is positive and more close to 1 it means that two user have common attitude when giving rating. And in reverse way, if value's below 0 and close to -1, two users have different trends in rating
2.4.0 :002 > pearson_correlation RATINGS, :John, :Lee
=> 0.4969293465978882
3. Ranking the user ratings
Now what we have is just method to comparing two people and we need to create another method that provides score of comparing between a giving person with all others. And from this comparision, we will know who's the guy has the most similar rating with us.
def top_matches data, user, n = 5
scores = data.map do |member, _|
next if user == member
#In this case, I use Pearson score
{}.tap do |member_rating|
member_rating[member] = pearson_correlation(data, user, member)
end
end.compact
#Sort the list to get the highest score
scores.sort_by{|user_rating| user_rating.values.first }.reverse.take(n)
end
And we will have output for the dataset that we mentioned in first part
2.4.0 :002 > top_matches RATINGS, :John
=> [{:Prince=>0.6858449352888184}, {:Lee=>0.4969293465978882}, {:Sarah=>0.43490701281761557}, {:Jack=>0.1889822365046136}, {:Jacob=>0.0}]
4. Giving User-based recommendations
From all above steps, we just try to find out who has similar taste with us but in the real world, each time we want to make a decision, we have to get all previous rating of that user is so complicated. Everything we need right now is just recommended item. Another issue is that, if the movie that we want to watch doesn't appear in the list of top matched user, what we gonna do? To solve these issues,we need to score the items by producing a weighted score that ranks the ratings. Take the votes of all other users and multiply how similar they are by the score gave each movie. The table bellow show how process work with film Kong
| User | Similarity score | Kong | S.xKong |
|---|---|---|---|
| Prince | 0.686 | 6.0 | 4.115 |
| Lee | 0.497 | 6.5 | 3.230 |
| Sarah | 0.435 | 0 | 0 |
| Jack | 0.189 | 0 | 0 |
| Total | 7.345 | ||
| Sim.Sum | 1.807 | ||
| Total/Sim.sum | 4.065 |
In the colum S.x, the results of mulply between rating and similarity score have shown. This meanting that the most similar people will contribue more to overall score than others. Total row shows the sum of all these number. Another factor is that a movie get more review by users would have a big advantage. To make it join to final number, we need to devide by the sum of all similarities from other users that used to review that movies. Now I will show how the code works for all other movies
def user_based_recommendation data, user
totals = {}
sim_sum = {}
data.each do |member, rating|
#Skip if member is user
next if member == user
sim_score = pearson_correlation(data, user, member)
next if sim_score <= 0
rating.each do |movie, rate|
#only score movies that user haven't seen yet
if data[user][movie].nil? || data[user][movie] == 0
#Similarity * score
totals[movie] = 0 if totals[movie].nil?
totals[movie] += (data[member][movie] * sim_score)
#Sum of similarities
sim_sum[movie] = 0 if sim_sum[movie].nil?
sim_sum[movie] += sim_score
end
end
end
rankings = totals.map do |re_movie, re_score|
{}.tap do |recommendation|
recommendation[re_movie] = totals[re_movie]/sim_sum[re_movie]
end
end
rankings.sort_by{|_, score| score }.reverse
end
Now, let try our simple system
2.4.0 :003 > user_based_recommendation RATINGS, :Jack
=> [{:"La La La Land"=>7.972331109535345}, {:Kong=>6.443073216268277}, {:Logan=>5.549187658975371}]
5.Bottom line
When go down to this line, I think all of you has gotten basic concept to give recommended based on user-rating. However, using user's data sometime is so sensitive due to privacy and in next post, I'll present another way to giving recommendation based on item
All rights reserved
