Thu thập dữ liệu tự động cùng với Scrapy, Mongodb và Crontab
Bài đăng này đã không được cập nhật trong 5 năm
Các lĩnh vực công nghệ cao như học máy, trí tuệ nhân tạo đang ngày một phát triển và đã cho ta thấy khá nhiều ứng dụng thiết thực. Góp phần vào những thành tựu đó việc tạo ra một bộ dữ liệu huấn luyện là vô cùng quan trọng, và đôi khi dữ liệu tốt sẽ tốt hơn mô hình. Trong bài lần này mình sẽ hướng dẫn các bạn một cách đơn giản để xây dựng một ứng dụng có thể khai phá được những dữ liệu trên mạng Internet một cách tự động chỉ với một chút hiểu biết về python, webase và linux. Các bạn có thể tìm đọc một bài mình đã từng viết cũng về việc thu thập dữ liệu nhưng được lưu trữ với csdl MySQL, lần này mình sẽ sử dụng một csdl NoSQL là MongoDB và ứng dụng cũng sẽ tự động thu thập làm mới dữ liệu hàng ngày

Cài đặt môi trường
Mình hiện tại đang sử dụng Ubuntu OS nên đối với các hệ điều hành khác sẽ có đôi chút khác Đầu tiên các bạn cần phải cài đặt Mongodb trước , các bạn có thể cài đặt theo hướng dẫn khá chi tiết tại đây
Tiếp tục là cài đặt scrapy :
pip3 install scrapy
Cài đặt pymongo để có thể dễ dàng thao tác với mongo thông qua python
pip3 install pymongo
Oke vậy là công đoạn chuẩn bị tương đối đã xong
Crawl dữ liệu
Lần này con mồi sẽ là trang web tin tức CNET và cụ thể là mục Tech industry :

Trong lần này mục đích cá nhân của mình là tìm các bài báo công nghệ để xây dựng dữ liệu cho mô hình học máy phân loại báo của mình. Có vẻ lấy text thì sẽ khá đơn giản nếu các bạn đã từng đọc qua bài viết lần trước của mình, tuy nhiên ở trang web này có một số chỗ hơi khác đó chính là những bài này không đơn thuần bài nào cũng là text mà rất nhiều bài là một Video do đó chúng ta cũng cần một số trick để lách qua khe cửa này
Trước hết nhìn qua cái url có dạng: https://www.cnet.com/topics/tech-industry/2/ , nhìn vào cách sắp xếp này khá đơn giản , muốn next tiếp page sau chỉ cần tịnh tiến chữ số cuối cùng lên là được (Cài này có thể xử lý dễ dàng)
Tiếp tục , mục đích của mình là chỉ crawl những bài có nội dung là text còn bọn video, mp3 thì quẳng hết chúng đi, cái này thì cũng cần suy nghĩ một chút.
Trước tiên chúng ta cứ xem thử cây DOM của bọn này xem có gì đặc sắc:
 Các bạn có thể thấy trang web này xây dựng khá đẹp, tất cả các link bài chi tiết mình cần lấy nó sẽ nằm dưới dạng:
Các bạn có thể thấy trang web này xây dựng khá đẹp, tất cả các link bài chi tiết mình cần lấy nó sẽ nằm dưới dạng:
[Section] **[div]** [div] **Links cần lấy** [/div] **[/div]** [/Section]
Tiếp theo các bạn mở terminal lên và gõ (Nhớ rằng phải install scrapy trước đó ):
scrapy shell https://www.cnet.com/topics/tech-industry/
và past đoạn script này vào :
response.xpath('//section[@id="topicListing"]/div[@class = "row asset"]/div[@class="col-2 assetThumb"]/a/@href').extract()
(Các bạn có thể xem lại bài trước của mình để hiểu rõ tại sao mình lại viết đoạn script như này nhé)
Oke, đây là kết quả :
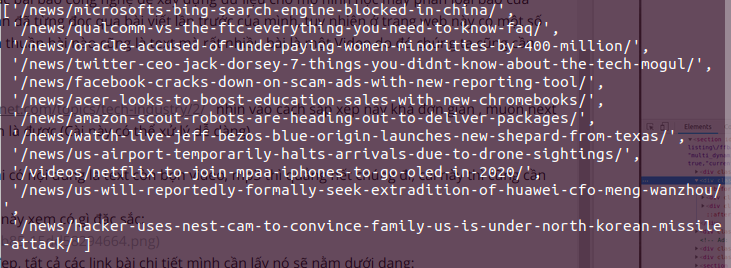
Có vẻ kết quả này cũng đã tự trả lời cho câu hỏi chỉ lấy text của mình, chỉ cần thêm câu regex nữa là ta có thể lọc được những link chỉ chứa text:
r"\/news\/.*"
Vậy xong một bước tìm link chi tiết, tiếp theo mình cần lấy được đoạn text cần thiết. Vào thử một trang chi tiết nào
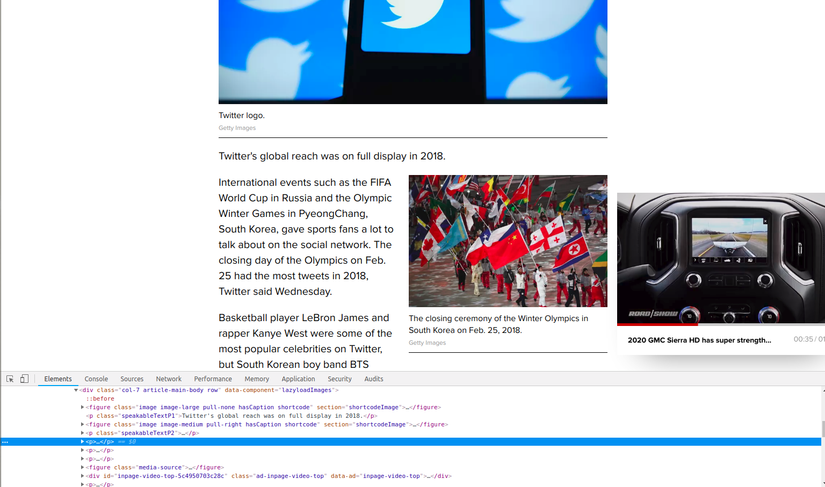
Nhìn qua thì những đoạn của bài báo này được chi dưới dạng mỗi đoạn trong một thẻ
Vẫn tiếp tục cách cũ với scrapy shell :
scrapy shell https://www.cnet.com/news/twitters-top-tweets-of-2018-k-pop-and-international-events-shine/
Sau đó copy đoạn script này vào :
response.xpath('//article[@id="article-body"]/div[@class="col-7 article-main-body row"]/p/text()').extract()
Kết quả đưa về sẽ ra là một mảng các đoạn văn bản :
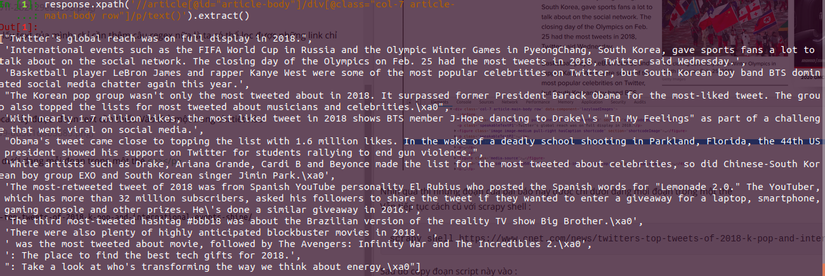
Bây giờ chỉ việc join lại là có đoạn văn bản mình cần tìm.
Thao tác với Mongodb
Với những bước thiết lập ban đầu chúng ta đã có thể thao tác trực tiếp với mongodb Trước hết mở mongodb lên bằng câu lệnh :
sudo service mongod start
Các bạn nếu muốn tìm hiểu thêm về mongo có thể đọc qua đây
Trong bài lần này mình sử dụng pymongo nên thao tác sẽ khá đơn giản cho các bạn mới tiếp cận, các bạn cũng có thể đọc chi tiết hơn tại đây
Kết nối giữa scrapy và pymongo
Trước hết tạo project bằng câu lệnh đơn giản
scrapy startproject CNET
Trong folder spiders tạo một file cnet_spyder.py
Toàn bộ đoạn code của ứng dụng chỉ đơn giản trong chưa đầy 50 dòng code :
from pymongo import MongoClient
import scrapy
import pdb
import re
client = MongoClient('localhost', 27017)
db = client.CNET
col = db['articles']
class NewsSpider(scrapy.Spider):
name = "tech-industry"
start_urls = [ "https://www.cnet.com/topics/tech-industry/"]
def parse(self, response):
source = "https://www.cnet.com"
list_topic = response.xpath('//section[@id="topicListing"]/div')
links = list_topic[1].xpath('//div[@class = "row asset"]/div[@class="col-2 assetThumb"]/a/@href').extract()
regex = r"\/news\/.*"
list_news = [x for x in links if re.match(regex,x)]
exist = False
for i in list_news:
if(col.find({"link": source + i}).count() > 0):
exist = True
break
yield scrapy.Request(source + i, callback= self.importMongo)
if(exist == False):
next_url = ""
if((source + "/topics/" + self.name + "/") == response.url):
next_url = response.url + "2/"
else:
next_url_arr = response.url.split("/")
next_url_arr[-2] = str(int(next_url_arr[-2]) + 1)
next_url = "/".join(next_url_arr)
yield scrapy.Request(next_url, callback= self.parse)
def importMongo(self, response):
list_sentences = response.xpath('//article[@id="article-body"]/div[@class="col-7 article-main-body row"]/p/text()').extract()
content = "".join(list_sentences)
link = response.url
col.insert_one({"link": link,"content": content})
Mình sẽ giải thích từng đoạn :
from pymongo import MongoClient
from CNET.article2json import article_json
import scrapy
import pdb
import re
client = MongoClient('localhost', 27017)
db = client.CNET
col = db['articles']
Đoạn này để :
- Import các thư viện
- Tạo liên kết với Mongo thông qua port 27017 (port của mongo)
- Khởi tạo một collection cho Mongodb, các bạn có thể hiểu collection tương tự như table trong SQL.
Tiếp theo mình sẽ giải thích từng Function:
- parse : Tư tưởng của function này là tìm tất cả các link từ trang chứa list các bài, nếu gặp phải một bài đã có trong csdl thì sẽ dừng lại , nếu không tịnh tiến tiếp các trang chứa list bài. Biến exist sinh ra để đánh checkpoint khi tìm thấy một văn bản đã có trong csdl (Mình sẽ sử dụng đường link để so sánh). Có thêm một logic phải xử lý đó là với trang list ban đầu sẽ có dạng khác với các trang từ trang số 2 trở đi, do đó mình có xử lý một chút nhưng cũng khá đơn giản
- importMongo : Function này giống như tên gọi của nó , tìm đoạn text và lưu vào cơ sở dữ liệu thôi
Lập lịch với crontab
Lập lịch khá đơn giản với crontab, với ứng dụng này mình muốn nó tự động cập nhật vào khoảng 24h mỗi ngày, do đó mình sử dụng những dong lệnh đơn giản sau:
crontab -e
Sẽ xuất hiện màn hình để định nghĩa các job cần chạy, mình muốn tự động cập nhật vào 24h nên câu lệnh cần điền vào sẽ có dạng :
* 24 * * * cd ~/workspaces/Python/CNET/ && ~/.local/bin/scrapy crawl tech-industry
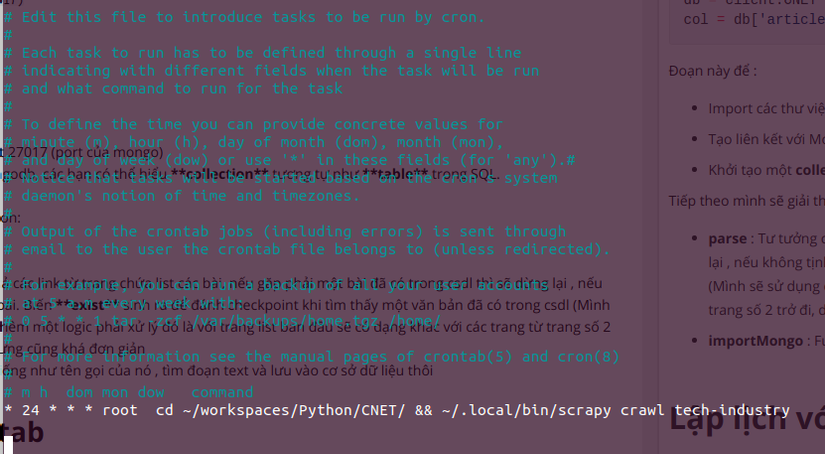
Vậy là mỗi 24h hàng ngày ứng dụng sẽ tự động crawl dữ liệu mới nhất về cơ sở dữ liệu
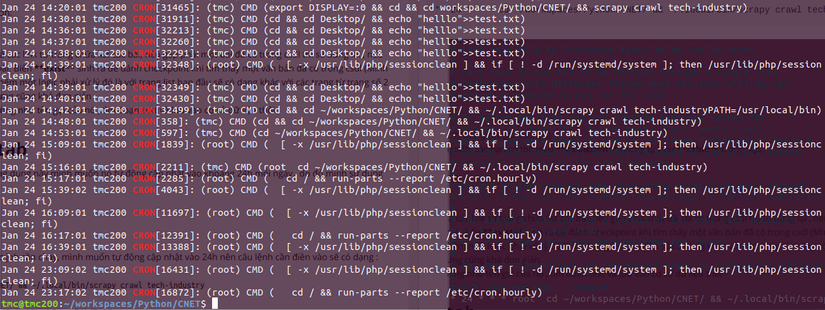
Các bạn có thể xem lại các logs của crontab với câu lệnh :
grep CRON /var/log/syslog
Kết luận
Vậy đã hoàn thành bài hướng dẫn tạo ứng dụng tự động thu thập dữ liệu và lưu trữ với cơ sở dữ liệu NoSQL. Có các bạn sẽ thấy với việc chỉ trên local thì việc tạo crontab không thực sự mang tính thực tế nhưng nếu tạo ứng dụng độc lập trên EC2 hay một máy chủ thì sẽ cho thấy một dấu hiệu rất tích cực cho việc tự động hóa.
Những bài tiếp theo mình sẽ cố gắng giới thiệu thêm những bài viết mới về xử lý scrapy với những cây DOM ảo hay triển khai trên nền tảng cloud EC2.
Mong rằng bài viết lần này có hữu ích đối với các bạn.
Tham khảo
https://viblo.asia/p/lap-lich-tasks-tren-linux-su-dung-crontab-6J3Zg28MKmB https://api.mongodb.com/python/current/
Còn đây là link git nếu các bạn muốn test thử nhé https://github.com/tranchien2002/crawl_cnet
All rights reserved
