Regular Expression
Bài đăng này đã không được cập nhật trong 6 năm

1. Regular expression là gì
1.1 Lịch sử
Regular expression hay được gọi với tên đơn giản là biểu thức chính quy hay regex. Nó lần đầu được giới thiệu vào năm 1950s bởi một nhà toán học người Mỹ - Stephen Kleene

Biểu thức * được mang tên của ông đó là Kleene star vì những đóng góp tuyệt vời của ông với regex
Qua nhiều lần chỉnh sửa và được sự kết hợp nhiều nhà nghiên cứu và tin học khác nhau nguồn tham khảo, thì regex đã hoàn thiện và phát triển được như bây giờ
1.2 Định nghĩa
Regex là tập hợp một bộ cú pháp (pattern) giúp ích trong việc xử lí chuỗi, có thể là tìm kiếm, tìm kiếm rồi thay thế, hoặc dùng validate format trong các model nữa
Ví dụ:
/\A(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[`~!@#$%^&*()\-_+=\[\]{}])[0-9a-zA-Z`~!@#$%^&*()\-_+=\[\]{}]{10,}\z/
Bên trên là validate password với điều kiện là ít nhất một kí tự số, một kí tự in hoa, một kí tự in thường, một kí tự đặc biệt trong bộ `[~!@#$%^&*()-_+=]{} và phải nhiều hơn 10 kí tự
Nhìn khá đơn giản phải không =))
Ngoài ra, mình còn tìm được một bộ validate cho tiếng Nhật nếu có bạn nào cần nguồn tham khảo
Regex được hầu hết các ngôn ngữ lập trình hỗ trợ (.NET, Ruby, Python, Javascript, ....)
Với tùy từng loại ngôn ngữ thì regex lại có những tùy chỉnh khác nhau, vậy nên mọi người cần phải thử nghiệm test kĩ lại trên từng loại ngôn ngữ lựa chọn
Trong bài viết này, mình chỉ xoay quanh làm việc regex với Ruby thôi, dùng irb của ruby để chạy demo regex trên ruby
2. Regex in Ruby
2.1 Khai báo
Ruby có 3 cách chính khai báo:
Regexp.new('pattern', flag)
Với flag là biến cờ, tí nữa mình sẽ giới thiệu chi tiết về các biến cờ này
Ví dụ: Regexp.new('\w', Regexp::IGNORECASE)
Ngoài ra, ta có hàm Regex.complile là aslias với Regex.new, nên ta dùng các nào cũng được
%r{pattern}flag
Ví dụ: %r{\w}i
Ngoài ra, có thể khai báo dưới dạng %r!\w!, %r#\w#, ... miễn là kí tự bao quanh pattern là kí tự đặc biệt (mình đã thấy nhiều project khai báo kiểu này)
/pattern/flag
Ví dụ: /\w/i
Cách này là đơn giản và dễ nhìn nhất =))
2.2 Ứng dụng
-
Kiểm tra format hay là validate một chuỗi xem có đúng định dạng yêu cầu hay không
-
Thay thế chuỗi:
gsub,gsub!,sub,sub!
Với sub thì ta sẽ thay thế một kí tự đầu tiên và dừng lại, không làm ảnh hưởng đến chuỗi ban đầu
sub! giống như sub là thay thế kí tự đầu tiên, khác ở chỗ nó áp dụng sự thay đổi vào trong chuỗi ban đầu
gsub thay thế tất cả các kí tự thỏa mãn với pattern, g trong gsub đại diện cho biến cờ global trong regex, nó cũng không làm ảnh hường đến chuỗi ban đầu
gsub! giống với gsub nhưng sẽ thay thế trực tiếp trên chuỗi ban đầu
- Kiểm tra format
=~,match?,===
Thường thì mình hay dùng match? hơn vì nó đơn giản, nếu kết quả trả ra true thì chuỗi đó đúng chuẩn, còn false thì chuỗi đó không đúng format
Ví dụ
"024.33511603".match? /\d/ => true
"024.33511603".match? /\A\d+\z/ => false
3. Các biểu thức regex
3.1 Các biểu thức cơ bản
| Kí hiệu | Giải thích |
|---|---|
| [abc] | So sánh bất kì kí tự nào trong dấu ngoặc vuông |
| [^abc] | So sánh không trùng với các kí tự trong ngoặc vuông |
| [a-z] | So sánh kí tự trong khoảng chỉ định từ a-z |
| [a-zA-Z] | So sánh kí tự trong khoảng từ a-z và A-Z |
| \s | So sánh kí tự khoảng trắng (space hoặc tab) |
| \S | So sánh kí tự không phải khoảng trắng |
| \d | So sánh kí tự là số |
| \D | So sánh không phải là số |
| \w | So sánh kí tự là word (chữ latin, _, chữ số) |
| \W | So sánh kí tự không phải là word |
| (...) | Gom nhóm |
| (a | b) |
| a? | So sánh 0 hoặc 1 kí tự của a |
| . | So sánh 1 kí tự đơn bất kì ngoài unicode |
| a* | So sánh 0 hoặc nhiều hơn kí tự của a |
| a+ | So sánh 1 hoặc nhiều hơn kí tự của a |
| a{3} | So sánh với đúng 3 lần của của a |
| a{3,6} | So sánh với đúng 3 đến 6 lần của của a |
| a{3,} | So sánh với đúng từ 3 lần trở lên của a |
| \b | Khớp với kí tự đằng trước nó (giới hạn) |
| \B | Không khớp với kí tự đằng trước nó (giới hạn) |
Ngoài ra, mình còn tổng hợp một số phần mở rộng ở link
3.2 Lưu ý
-
Khi muốn tìm lấy giá trị hoặc thay thế, bạn nên nhóm phần tử đó lại trong group (nằm trong giữa 2 ngoặc đơn ())
-
Khi muốn kiểm tra format đúng hay sai, nên thêm những cú pháp neo (anchor) hoặc giới hạn (\b\b) để có thể kiểm tra được chính xác nhất
-
Các kí tự đặc biệt cần thêm \ đằng trước: , ^, $, ., |, ?, *, +, (, ), [, {
4. Bài tập
Mình có chuẩn bị một số bài tập để mọi người vừa làm vừa hiểu hơn về regex
1. Ứng dụng format số điện thoại trong danh bạ, nếu có số 0 đằng trước sẽ format thành +84
0978135000 -> +84978135000
- Bài giải:
Đây là dạng bài thay thế kí tự đầu tiên, vậy nên mình sẽ sử dụng hàm sub hoặc sub! là đủ
Regex mình viết là: \A0
Đáp án đầy đủ là: "0978135000".sub /\A0/, "+84"
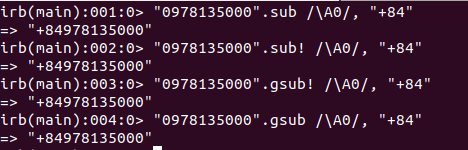
- Giải thích:
Bài toán này đơn giản chỉ là thay thế một kí tự nên cũng khá đơn giản, nhưng vẫn còn một chỗ cần lưu ý
Nó phải là kí tự đầu tiên, vậy nên mình có bổ sung thêm \A ở đầu regex (Mình có note trong lưu ý ở bên trên rồi), nó sẽ không thay thế nếu số 0 đó không nằm ở đầu chuỗi
Done, dễ phải không nào, tiếp tục bài 2 nhá
2. Cho Data sau:
thịt bò: 100.000
thịt lợn: 120.000
thịt gà: 80.000
Thay đổi data trên, vì cửa hàng muốn thể hiện là thịt của mình là hàng xịn, nên muốn thêm chữ (chính hãng) vào sau tên thịt, bổ sung đơn vị tiền tệ đằng sau giá tiền VND/kg
thịt bò: 100,000 -> thịt bò (chính hãng): 100.000 VND/kg
- Bài giải:
Bài này kết hợp cả tìm kiếm và thay thế chuỗi
Đầu tiên, ta phải tìm được format chung của chuỗi trên, sau đó thay thế thành thế thành chuỗi mình muốn
Mình sẽ sử dụng lazy matching để lấy tên thịt và số tiền tương ứng: (.*):(.*) (bạn nên test trên rubular trước)
Sau đó sẽ thay thế bằng chuỗi /(.*):(.*)/, '\1 (chính hãng): \2 VND/kg'

- Giải thích:
Mình sử dụng gom lazy matching .* và gom nhóm kết hợp () (có trong note rồi đó)
Khi mình gom nhóm rồi thì sẽ gọi được \1 tương ứng với tên thịt và \2 tương ứng với giá thịt
Cuối cùng thì mình chỉ cần thêm thắt dữ liệu cần thay đổi thôi, đơn giản phải không nào =))
3. Kiểm tra format email sun-asterisk
nguyen.quang.vinhb @sun-asterisk.com
nguyen.quang.vinhb.@sun-asterisk.com
nguyen.quang.vinhb@sun-asterisk.com111
nguyen.quang.vinhb@sun-asterisk.com
nguyen.quang..vinhb@sun-asterisk.com
.nguyen.quang.vinhb@sun-asterisk.com
nguyen@quang.vinhb@sun-asterisk.com
-> format đúng là: nguyen.quang.vinhb@sun-asterisk.com
- Bài giải:
https://regex101.com/r/b2LgHj/2
^\w+(?:\.\w+){0,}@sun-asterisk\.com$

- Giải thích
Đầu tiên thì mình sẽ tìm email có định dạng phần đuôi đúng với sun-asterisk đó là @sun-asterisk\.com$
Tiếp đó, email phải được bắt đầu bằng kí tự chữ ^\w+
Cuối cùng là format một dấu chấm và một cụm từ (?:\.\w+){0,}, cái này bắt được luôn điều kiện là trước kí tự @ phải là một kí tự
5. Tổng kết
Trên đây là những tìm hiểu của mình về regular expression, hi vọng giúp ích được cho mọi người
Cảm ơn mọi người đã theo dõi.
6. Tài liêu tham khảo
https://viblo.asia/p/hoc-regular-expression-va-cuoc-doi-ban-se-bot-kho-updated-v22-Az45bnoO5xY
https://gist.github.com/terrancesnyder/1345094
https://www.rexegg.com/regex-quantifiers.html
7. Bài tập bonus
Hãy tìm chữ có nghĩ thỏa mãn regex bên dưới, bạn nào làm xong hãy comment bên dưới nha
(?(?=F)Fl|Th)e?y?\sb(?:o\w|\w{3})l$
Đáp án test trên regex101.com là chuẩn nhất vì khi test trên rubular, họ nói mình làm rubular buồn 
Thankss all !!!!
All rights reserved
