Phá mã cổ điển
Bài đăng này đã không được cập nhật trong 2 năm
Dạo gần đây tôi có thử sức với Matasano's crypto challenges (cryptopals.com). Về cơ bản đây là tập hợp các thử thách về mã hóa, mật mã; trong đó người chơi sẽ cố gắng hoàn thành các bài tập thực hành về mã hóa (bao gồm cài đặt các thuật toán mã hóa thông dụng, phá mã) từ cổ điển cho đến hiện đại. Trong challenge 3 và 4, bạn được yêu cầu phá mã cổ điển, cụ thể là single-byte XOR. Thuật toán mã hóa thật đơn giản, bạn sẽ chọn một khóa K (độ dài 1 byte) và lần lượt XOR với các byte đầu vào của bản rõ. Dễ dàng thấy đây là phiên bản mởi rộng hiện đại của mật mã Caesar. Dưới đây là thuật toán mã hóa:
def single_byte_xor(msg: bytes, key: int) -> bytes:
cipher = bytes(b^key for b in msg)
return cipher
Với thử thách 3, bạn sẽ được cung cấp một bản mã ( được mã hóa sử dụng single-byte XOR) và công việc của bạn là tìm ra bản rõ. Với bài này, do không gian khóa nhỏ (256 giá trị), bạn có thể thử 256 giá trị có thể của khóa (0x00 -> 0xFF), decrypt bản mã với khóa đó và nhìn xem bản rõ nào gần giống với tiếng anh nhất.
Nhưng challenge 3 mong muốn bạn tạo một chương trình tự động giải mã. Để làm được việc này, ta cần phải có cách để "chấm điểm" bản rõ so với tiếng Anh. Nghĩa là ta cần biết đoạn text vừa gỉa mã được giống với tiếng Anh như thế nào. Và ta sẽ chọn bản rõ có điểm số cao nhất.
Các hệ mã cổ điển đều có thể bị phá bằng phân tích tần suất (Frequency analysis), do đó để xây dựng hàm "chấm điểm" ta có thể sử dụng kiến thức về phân bố xác suất của các chữ cái trong tiếng anh. Hình bên dưới là tần suất xuất hiện của các chữ cái trong tiếng Anh.
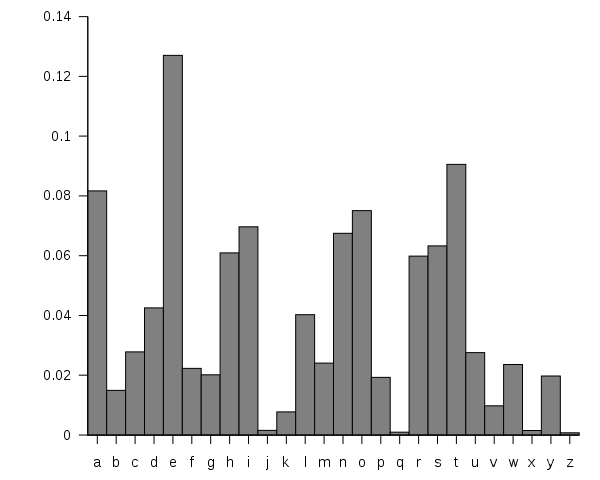
nguồn: https://en.wikipedia.org
Với challenge 3 này, tôi sử dụng thống kê Chi-squared để đánh trọng số (chấm điểm) cho bản rõ. Hiểu đơn giản, thống kê Chi-squared biểu diễn độ tương đồng giữa 2 phân bố xác suất, 2 phân bố càng giống nhau thì gía trị Chi-squared của chúng càng nhỏ và bằng 0 nếu 2 phân bố giống hệt nhau. Dưới đây là công thức tính Chi-squared:
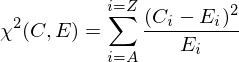
Trong đó, Ci là số lần xuất hiện của chữ cái i trong đoạn text, và Ei là số lần xuất hiện mong chờ (Expected) của chữ cái i trong đoạn text.
Bởi vì trong một câu tiếng Anh, ký tự khoảng trắng (space) cũng xuất hiện rất nhiều nên để có thể đánh gía tốt hơn, tôi đã sử dụng cả ký tự space lúc tính Chi-squared. Bạn có thể lấy dữ liệu xác suất của bảng chữ cái tiếng Anh bao gồm space tại http://www.data-compression.com/english.shtml.
Ta có thể hoàn thành challenge 3 bằng cách chọn ra bản rõ có Chi-squared bé nhất.
Nhưng để hoàn thành challenge 4 ta cần phải sử dụng đánh gía trọng số chính xác hơn, đó là sử dụng Chi-square cho cặp 2 chữ cái. Dữ liệu các bạn có thể lấy tại english_bigram.
Trong bài viết tới, tôi sẽ trình bày lời giải của mình cho challenges 5 và 6. Nếu bạn là người yêu thích tìm hiểu, nghiên cứu mật mã và các phương pháp phá mã hiện đại, bạn nên thử sức với Matasano's crypto challenges.
Đây là lời giải của tôi nếu bạn quan tâm: https://github.com/vuonghv/cryptopals
All rights reserved
