
Xây dựng hệ thống nhận dạng khuôn mặt real time - Phần 1: Làm quen bài toán nhận dạng khuôn mặt với Approximate Nearest Neighbors Oh Yeah(Annoy)
Bài đăng này đã không được cập nhật trong 4 năm
Lý Thuyết
ANNOY là gì ?
Các thuật toán Tree-based là một trong những thứ được dùng khá nhiều khi nhắc đến ANN(Mạng neural nhân tạo) . Chúng ta xây dựng các rừng cây từ dữ liệu bằng cách cấu trúc lại nó thành những tập con dữ liệu. Một trong những giải pháp nổi bật nhất là Annoy.
Annoy: Approximate Nearest Neighbors Oh Yeah là một thư viện C ++ với các ràng buộc Python để tìm kiếm các điểm trong không gian gần với một điểm truy vấn nhất định.
Nearest neighbors và mô hình vector

Hình vẽ ở trên biểu diễn một tập hợp điểm hai chiều, nhưng trên thực tế thì hầu hết các mô hình vector đều có nhiều hơn 2 chiều. Mục tiêu của ta ở đây là xây dựng cấu trúc dữ liệu cho phép ta tìm thấy các điểm gần nhất với bất kỳ điểm truy vấn nào trong thời gian tuyến tính. Chúng ta sẽ xây dựng một cây có thể queries với độ phức tạp là O(log n). Đó cũng chính là cách Annoy làm việc. Trên thực tế, đó là một cây nhị phân mà mỗi nút là một điểm phân tách ngẫu nhiên.

Đầu tiên ta sẽ chọn 2 điểm ngẫu nhiên trên mặt phẳng và sau đó chia mặt phẳng ra làm hai phần từ 2 điểm ngẫu nhiên đó ( Hình trên)

Và cứ tiếp tục từ 2 điểm ngẫu nhiên tiếp theo ta lại chia ra thành 2 mặt phẳng, và cứ tiếp tục như thế cho đến khi còn tối đa K items trong mỗi node với hình trên ta chọn K =10
 Với mặt phẳng trên ta có cây nhị phân tương ứng( hình trên ), ta kết thúc với một cây nhị phân với các phân vùng rõ ràng với các điểm là mỗi node. Ta có thể thấy các điểm gần nhau trong không gian ở mặt phẳng với k=10 thì rất gần nhau trong cây. vì thế ta có thể tìm ra phía nào của mặt phẳng mà chúng ta cần tiếp tục và điều đó xác định nếu chúng ta đi xuống node con bên trái hoặc bên phải. Sau đó ta sắp xếp tất cả các node theo khoảng cách và trả về K hàng xóm gần nhất. Và đó là cách thuật toán tìm kiếm hoạt động trong Annoy.
Với mặt phẳng trên ta có cây nhị phân tương ứng( hình trên ), ta kết thúc với một cây nhị phân với các phân vùng rõ ràng với các điểm là mỗi node. Ta có thể thấy các điểm gần nhau trong không gian ở mặt phẳng với k=10 thì rất gần nhau trong cây. vì thế ta có thể tìm ra phía nào của mặt phẳng mà chúng ta cần tiếp tục và điều đó xác định nếu chúng ta đi xuống node con bên trái hoặc bên phải. Sau đó ta sắp xếp tất cả các node theo khoảng cách và trả về K hàng xóm gần nhất. Và đó là cách thuật toán tìm kiếm hoạt động trong Annoy.
Annoy sẽ thực hiện tốt nếu có nhiều cây hơn, với cách cho thêm nhiều cây hơn thì ta sẽ có cơ hội để tìm ra chia tách thuận lợi nhất
Chữ "A" trong annoy viết tắt cho từ "approximate" có nghĩa là xấp xỉ cũng có nghĩa trong khi tìm kiếm sẽ thiếu một vài điểm có thể chấp nhận được. Toàn bộ ý tưởng đằng sau thuật toán approximate là hy sinh một chút độ chính xác đánh đổi lấy hiệu suất lớn hơn.
Thư viện Face Recognition
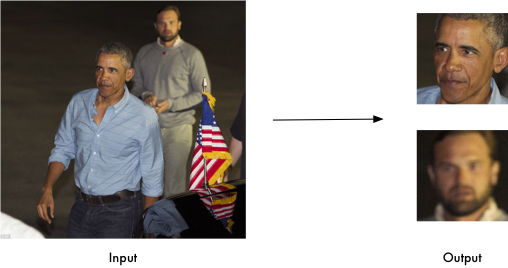
Một thư viện nhạn dạng khuôn mặt rất nổi tiếng và độ chính xác khá tốt xây dựng dựa trên dlib của python và được viết bằng C++. độ chính xác của mô hình trên tập Labeled Faces in the Wild là 99,38%.
Github: Tại đây
API: Tại Đây
Install: pip install face_recognition
Thực Hành
Bước 1: Chuẩn bị dữ liệu
Đầu tiên ta sẽ chuẩn bị bộ dữ liệu ảnh cới cấu trúc như thế này, trong mỗi thư mục có tên đều chưa ảnh của chính họ.

Bước 2: Save data vào annoy
chúng ta sẽ tạo ra một file annoy_save.py để save data là những hình ảnh trong những thư mục trên vào annoy:
NUMBER_OF_TREES = 100
f = 128
t = AnnoyIndex(f, 'angular')
imagePaths = list(paths.list_images('/home/nguyen.trung.son/Documents/3D_Sun/3d_project/images'))
def image_encoding(imagePath):
img = face_recognition.load_image_file(imagePath)
img_ = face_recognition.face_locations(img)
top, right, bottom, left = [ v for v in img_[0] ]
face = img[top:bottom, left:right]
img_emb = face_recognition.face_encodings(face)[0]
return img_emb
for i, imagePath in tqdm(enumerate(imagePaths)):
img_emb = image_encoding(imagePath)
t.add_item(i, img_emb)
t.build(NUMBER_OF_TREES) # 100trees
t.save('images.ann')
Expain code:
t = AnnoyIndex(f, 'angular'): hàm này trả về một index mới với f là số chiều của vector đó với metric là "angular"
img = face_recognition.load_image_file(imagePath): dung thư viện face_recognition để load images thay cho opencv
img_ = face_recognition.face_locations(img): Định vị và trả về các tọa độ của faces trong ảnh
img_emb = face_recognition.face_encodings(face)[0]: encode ảnh về vector 128 chiều
t.add_item(i, img_emb): thêm item i với vector v
t.build(NUMBER_OF_TREES): Xây dựng một rừng với 100 trees, càng nhiều cây thì cho cho độ chính xác khi truy vấn càng cao. Sau khi hàm build được gọi thì sẽ không thể add thêm item nào vào được nữa.
t.save('images.ann'): Lưu tất cả các index vào file images.ann
Bước 3: Load data từ annoy
Sau khi đã có file lưu index là images.ann ta sẽ bắt đầu load từ file đó:
f = 128
u = AnnoyIndex(f, 'angular')
u.load('images.ann')
Bước 4: Get name
Như Bước 1 ta đã có thư mục ảnh của mỗi người ứng với tên của họ với mỗi thư mục đó, bây giờ chúng ta sẽ lấy tên của mỗi người ứng với từng ảnh của họ trong thư mục và append vào một mảng, bạn có thể hỏi tại sao lại làm như thế, mình sẽ nói rõ hơn vào bước sau:
imagePaths = list(paths.list_images('path_of_you'))
for i, imagePath in tqdm(enumerate(imagePaths)):
name = imagePath.split(os.path.sep)[-2]
known_face_names.append(name)
Bước 5: Nhận dạng khuôn mặt
Yep, đến đoạn này là chúng ta xong khoảng 70% công việc rồi:
face_names = []
while True:
ret, frame = video_capture.read()
# resize hình ảnh xuống 1/4 để quá trình nhận dạng mặt nhanh hơn
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# Chuyển đổi từ BGR sang RGB (mặc định opencv dùng là BGR thay vì RGB)
rgb_small_frame = small_frame[:, :, ::-1]
face_names = []
face_locations = face_recognition.face_locations(rgb_small_frame)
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)
for face_encoding in face_encodings:
#Lấy index của vector trong annoy
matches_id = u.get_nns_by_vector(face_encoding, 1)[0]
#Lấy vector ra từ index tương ứng đã lấy ở trên
known_face_encoding = u.get_item_vector(matches_id)
#Hàm này trả về giá trị True or False, nếu giống là True không giống là False
compare_faces = face_recognition.compare_faces([known_face_encoding], face_encoding)
name = "unknown"
if compare_faces[0]:
#Lấy tên từ mảng đã tạo bước 3 dựa vào id tương ứng
name = known_face_names[matches_id]
face_names.append(name)
print(face_names)
Sau khi đã locate được khuôn mặt và tên của người có trong database rồi ta sẽ tiến hành show nó lên camera:
for (top, right, bottom, left), name in zip(face_locations, face_names):
# Lúc đầu ra scale nó xuống nhỏ gấu 4 lần để detect faces tốt hơn, bây giờ ta sẽ nhân trả lại tọa độ gốc cho nó
top *= 4
right *= 4
bottom *= 4
left *= 4
# draw line cho face
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# Draw label cho face
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)
output_names.append(name)
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
Kết quả
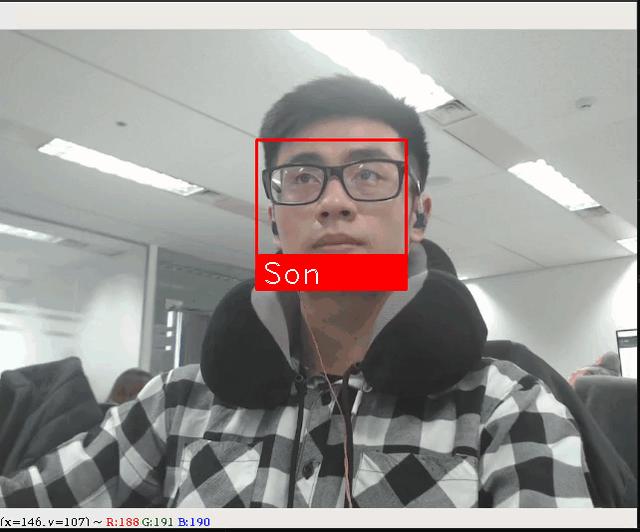
Trong lúc viết bài có chỗ nào không hiểu thì các bạn cmt bên dưới nhé, còm ko đúng thì mong các bạn góp ý, cảm ơn các bạn 
Reference
https://github.com/spotify/annoy
https://github.com/ageitgey/face_recognition
https://www.pyimagesearch.com/2018/09/24/opencv-face-recognition/
https://face-recognition.readthedocs.io/en/latest/readme.html#installation
All rights reserved
