Tìm hiểu thuật toán đồng thuận Raft. Phần 1. Giới thiệu qua về Raft
Bài đăng này đã không được cập nhật trong 3 năm
1. Giới thiệu
Các thuật toán đồng thuận là một cơ chế cho phép một cụm nhiều máy tính (server) hoạt động mạch lạc, suôn sẻ, dù cho trong đó có một vài server đang bị ngắt kết nối với cụm. Do đó, các thuật toán đồng thuận luôn đóng một vai trò quan trọng trong việc xây dựng các hệ thống tính toán quy mô lớn đáng tin cậy.
Trong đó Raft là một thuật toán đồng thuận hoạt động tương đối hiệu quả, có những ưu điểm đáng kể so với các thuật toán đồng thuận khác, nó có 3 đặc tính quan trọng sau:
-
Stronger Leader (vai trò của Leader mạnh hơn): Raft cho phép Leader có vai trò mạnh mẽ hơn các thuật toán đồng thuận khác. Ví dụ, các log entries chỉ được broadcast từ Leader đến các server khác. Điều này giúp đơn giản hóa quản lý việc replicate các log entries giữa các server với nhau và giúp Raft dễ hiểu hơn (so với thuật toán Paxos của Leslie Lamport).
-
Leader Election ( việc bầu cử Leader): Raft sử dụng một bộ đếm giờ ngẫu nhiên để bầu leader, đó đơn giản là thêm một thay đổi nhỏ vào heartbeats so với các thuật toán đồng thuận khác, nhưng nó lại giúp giải quyết conflict giữa các server trong cụm một cách đơn giản và nhanh chóng.
-
Membership changes (thay đổi vai trò của server trong cụm): nghĩa là thay đổi vai trò của một server nào đó từ follower thành leader và ngược lại, cơ chế mà Raft sử cho việc thay đổi này là sử dụng một phương pháp đồng thuận chung mới (joint consensus), trong quá trình thay đổi này vai trò của một server sẽ là sự overlap giữa leader và follower . Điều này cho phép tổng thể cụm vẫn tiếp tục hoạt động bình thường trong khi các server trong cụm đang trong quá trình thay đổi vai trò.
2. Replicated state machines
Mỗi server trong cụm sẽ có một state machine.
Thuật toán đồng thuận phải đảm bảo làm sao cho các state machines trên các server trong cụm phải có cùng một state (replicated) và có thể tiếp tục hoạt động ngay cả khi có một số server trong cụm bị mất kết nối. Replicated state machines thường được sử dụng để giải quyết một loạt các vấn đề về khả năng chịu lỗi trong hệ thống phân tán.
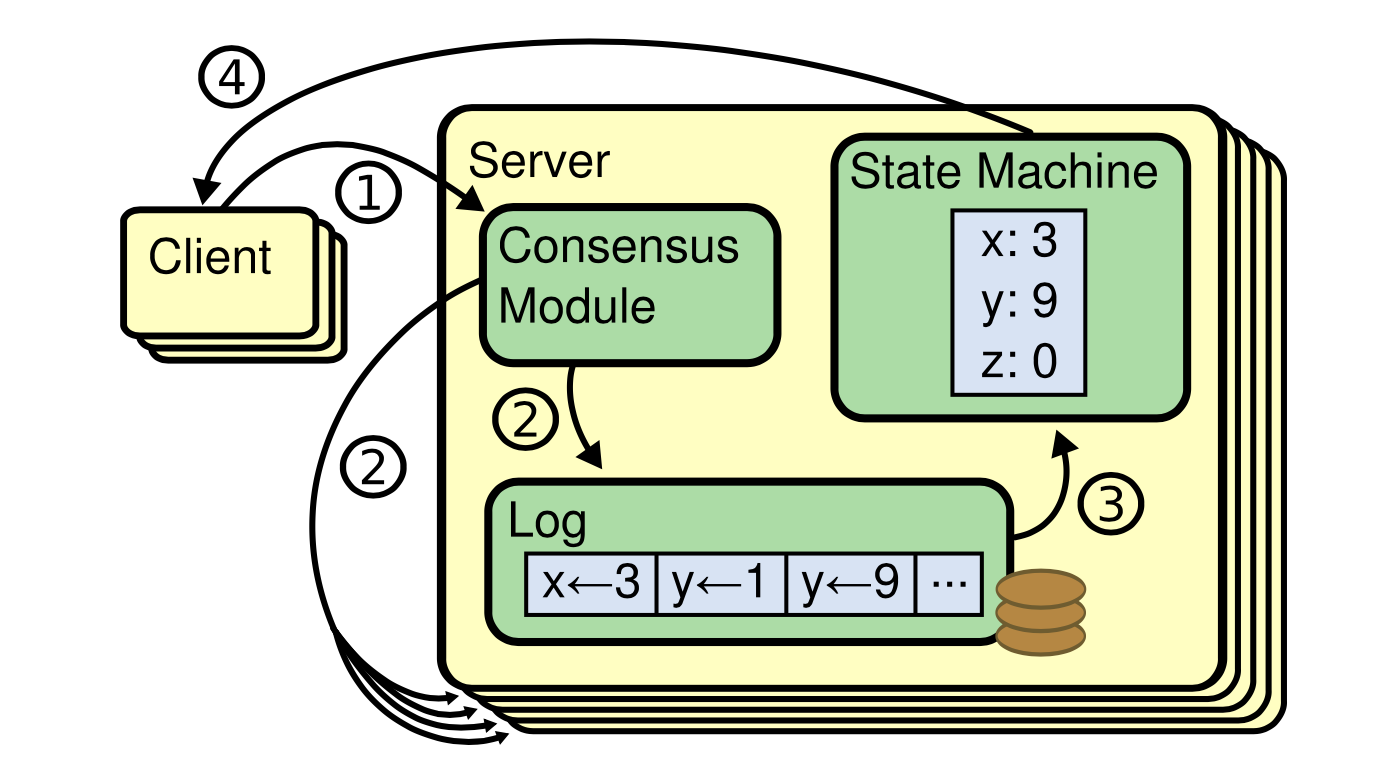
Hinh 1: Kiến trúc của Replicated state machine.
Client gửi đến một log gồm các command cập nhật state cho cụm, thuật toán đồng thuận sẽ quản lý việc sao chép (replicate) log này đến từng server trong cụm. Do đó, các state machines trên các servers sẽ xử lý cùng một log, và chúng tạo ra các đầu ra giống nhau.
Các replicated state machines thường được triển khai bằng cách sử dụng một replicate log, như trong Hình 1.
Mỗi server lưu trữ một log chứa một chuỗi các lệnh mà state machine của nó sẽ thực hiện theo thứ tự. Vì log mà các servers nhận được là giống nhau, nên các state machines sẽ xử lý cùng một chuỗi lệnh, và tạo ra cùng một state.
Giữ replicated log sao cho chúng được nhất quán là công việc của thuật toán đồng thuận. Consensus module trên một server sẽ nhận command từ và thêm chúng vào log của nó. Sau đó nó giao tiếp với các server khác cũng thông qua consensus module để đảm bảo rằng các log của chúng đều chứa các command giống nhau theo cùng một thứ tự, ngay cả khi trong cụm có một số server bị lỗi. Tiếp theo, các replicated state machine trên các server sẽ xử lý log và trả về kết quả cho client. và các dường như các kết quả này là giống nhau, có độ tin cậy cao.
Các thuật toán đồng thuận cho một hệ thống thực tế thường có các thuộc tính sau:
-
Chúng phải đảm bảo an toàn (không bao giờ trả lại kết quả không chính xác) trong mọi điều kiện non-Byzantine, bao gồm các trường hợp như độ trễ mạng, mất gói tin, sao chép gói và sắp xếp lại các lệnh trong gói.
-
Chúng phải có sẵn đầy đủ chức năng sao cho các server đang hoạt động có thể giao tiếp với nhau và với client. Do đó, một cụm 5 server vẫn có thể hoạt động nếu bất ngờ 2 server nào đó bị tắt, sau đó 2 server đó được bật lại, phục hồi từ trạng thái đã được lưu trước đó và tham gia lại cụm.
-
Chúng phải không phụ thuộc vào thời gian để đảm bảo tính nhất quán của log.
-
Thông thường, một lệnh có thể được hoàn thành ngay khi phần lớn các server đã hoàn thành lệnh đó ; một số ít server chậm sẽ không ảnh hưởng đến hiệu năng của toàn hệ cụm.
3. Thuật toán đồng thuận Raft
Raft là một thuật toán để quản lý một replicated log được mô tả trong Phần 2.
Raft thực hiện sự đồng thuận bằng cách trước tiên bầu một leader, sau đó giao cho leader hoàn toàn chịu trách nhiệm quản lý replicated log.
Leader sẽ nhận các log entry từ client, replicate chúng cho các server khác và thông báo cho các server đó khi nào an toàn để apply chúng vào state machine của mỗi server. Việc có một leader sẽ đơn giản hóa quản lý replicated log.
Leader có thể quyết định nơi đặt các entries mới trong log mà không cần tham khảo các server khác và luồng dữ liệu cũng được gửi theo cách đơn giản từ leader đến các server khác. Một leader có thể fail hoặc bị ngắt kết nối, trong trường hợp đó, một leader mới sẽ được bầu.
Theo cách tiếp cận bằng khía cạnh leader, Raft phân tách vấn đề đồng thuận thành ba bài toán con tương đối độc lập:
- Leader election (bầu chọn leader): một leader mới phải được bầu khi leader hiện tại bị fail
- Log replication (sao chép log): leader phải nhận các log entries từ client và replicate chúng trên toàn cụm, buộc các server khác phải chấp nhận các entries đó vào log riêng của chúng.
- Safety: tính an toàn của Raft chính là tính an toàn của state machine, nếu bất kỳ server nào đã apply một log entry nào đó cho state machine của nó, thì sẽ không có server nào khác có thể apply một lệnh khác cho cùng log entry đó.
3.1 Tóm tắt các khái niệm trong Raft
State

Nhìn vào hình thì ta có thể tháy có 2 loại state trong Raft đó là :
- Persistent state: State này sẽ được update trên stable storage trước khi server đó phản hồi cho RPCs
- Volatile state: Trong đó, có những thuộc tính chung cho tất cả máy tính, có những thuộc tính riêng mà chỉ leader mới có.
Tóm tắt lại thì server không phải leader và server là leader sẽ có những thuộc tính sau:
non-leader:
- currentTerm
- votedFor
- log[]
- commitIndex
- lastApplied
leader:
- currentTerm
- votedFor
- log[]
- commitIndex
- lastApplied
- nextIndex[]: # sẽ được khỏi tạo lại sau mỗi phiên bầu cử
- matchIndex[] # sẽ được khởi tạo lại sau mỗi phiên bầu cử
Trong đó :
- currentTerm: nhiệm kỳ mới nhất, khi bắt đầu hệ thống Raft sẽ được khởi tạo là 0, bước tăng là 1
- votedFor: Id của server mà đã được server này vote cho ở nhiệm kỳ hiện tại (currentTerm)
- log[]: log entries; mỗi entry chứa lệnh cho state machine và term mà leader nhận được entry đó (đầu tiên là 1). Vậy log[] là một mảng các item, mỗi item sẽ có 2 thuộc tính là entry và term mà leader nhận được entry đó.
- commitIndex: index của log entry cao nhất đã được committed (khởi tạo từ 0, bước tăng 1)
- lastApplied: index của log entry cao nhất đã được apply vào state machine (khởi tạo từ 0, bước tăng 1)
- nextIndex[]:(thuộc tính riêng của leader) đối với mỗi server, index của log entry tiếp theo sẽ được leader gửi đến server đó (khởi tạo bằng log index của leader + 1 )
- matchIndex[]: đối với mỗi server, index của log entry cao nhất đã được replicated trên server đó (được khởi là 0, bước tăng 1)
AppendEntries RPC

Được leader invoke để replatecate các log entries. Trong đó có các tham số :
- term: term của leader
- leaderId: để các máy tính khác có thể chuyển cho client
- prevLogIndex: chỉ mục của log entry liền trước
- prevLogTerm: term của entry của prevLogIndex
- entries: các log entries cần được các server lưu vào, (là rỗng nếu đó là heartbeat; hoặc có thể nhiều hơn 1 entry để tăng hiệu suất)
Sau khi leader gửi các tham số đấy đi đến các server trong cụm, kết quả trả về sẽ có 2 thuộc tính :
- term: currentTerm, để leader update currentTerm của chính nó
- success: true nếu server đó có chứa entry mà matching (khớp) với prevLogIndex và prevLogTerm
Phía các server nhận được sẽ thực hiện :
-
- Trả về false nếu term nhận được < currentTerm của nó
-
- Trả về false nếu log của nó không chưa entry tại index = prevLogIndex mà nó nhận được có term match với prevLogTerm
- Nếu nó có một entry conflict với một entry mới (cùng index nhưng khác term), nó sẽ xóa entry đó có và tất cả các các entry theo sau.
- Append bất kỳ entry nào mà chưa có trong log của nó
- Nếu leaderCommit mà nó nhận được > commitIndex của nó, nó sẽ đặt commitIndex = min (leaderCommit, index của entry mới nhất)
RequestVote RPC

Được gọi bởi các server đang muốn làm leader (candidates - ứng cử viên) để thu thập phiếu bầu. Gồm các tham số :
- term: term của candidate
- candidateId: Id của candidate
- lastLogIndex: index của log entry mới nhất của candidate
- lastLogTerm: term của log entry mới nhất của candidate
Kết quả trả về sẽ có 2 thuộc tính :
- term: currentTerm của server nhận request, để candidate update cho chính nó
- voteGranted: true nếu candidate nhận được 1 vote từ server nhận
Phía các server nhận được request sẽ thực hiện:
-
- Trả về false nếu term nhận được < currentTerm của nó
-
- Nếu votedFor của server đó đang là null hoặc bằng với candidateId, và log của candidate ít nhất là up-to-date với log của server đó, tiến hành vote.
Rules for servers

Tất cả server đều có:
- Nếu commitIndex > lastApplied: tăng lastApplied, apply log[lastApplied] vào state machine của server đó
- Nếu RPC request hoặc response có chứa term T > currentTerm của server đó: server đó sẽ đặt currentTerm = T, trở thành follower.
Ở các server đang là follower:
- Phản hồi cho các RPC đến từ các candidates và leaders
- Nếu election timeout elapses mà không nhận được AppendEntries
RPC từ leader hiện tại hoặc đang vote cho candidate: chuyển thành candidate
Ở các server là candidate:
- Khi chuyển thành candidate, bắt đầu election:
- Tăng currentTerm
- Vote cho chính nó
- Reset election timer
- Gửi RequestVote RPC cho tất các server khác
- Nếu nhận được votes từ đa số các server, trở thành leader
- Nếu nhận AppendEntries RPC từ leader mới, chuyển thành follower
- Nếu election timout elapses: bắt đầu election mới
Ở leaders:
- Trong thời gian đương nhiệm: liên tục gửi các RPC AppendEntries empty (heartbeat) đến mỗi server để ngăn election timeout.
- Nếu nhận được lệnh từ client, append entry vào log của nó, phản hồi sau khi entry đã được applied vào state machine.
- Nếu index của log mới nhất >= nextIndex của một follower nào đó, gửi AppendEntries RPC với log entries bắt đầu đầu tại nextIndex:
- Nếu thành công: cập nhật nextIndex và matchIndex tương ứng với follower đó
- Nếu AppendEntries do log không nhất quán, giảm nextIndex và thực hiện lại
- Nếu tồn tại một N mà N > commitIndex, đa số matchIndex[i] >= N và log[N].term == currentTerm: đặt commitIndex = N.
3.2 Các đảm bảo trong Raft

- Election Safety: Nhiều nhất một leadet được bầu trong một term nhất định
- Leader Append-Only: leader không bao giờ ghi đè hoặc xóa entries trong log của nó, nó chỉ append các entries mới.
- Log Matching: nếu hai log chứa một entry có cùng index và term, thì các log đó có các entries từ đầu đến index giống hệt nhau
- Leader Completeness: nếu một log entry được commit trong một term nhất định thì entry đó sẽ có trong tất cả các logs của các leaders trong các term về sau.
- State Machine Safety: nếu một máy tính đã applied một log entry tại một index nhất định vào state machine của nó, sẽ không có máy tính khác apply một entry khác cho cùng index đó.
Tài liệu tham khảo
All rights reserved
