
Image Retrieval với thư viện FAISS
Bài đăng này đã không được cập nhật trong 3 năm
I. Introduction
Faiss
Facebook AI Similarity Search (Faiss) là một thư viện sử dụng similiarity search cùng với clustering các vector. Faiss được nghiên cứu và phát triển bởi đội ngũ Facebook AI Research; được viết trong C++ và đóng gói trên môi trường Python. Bộ thư viện bao gồm các thuật toán tìm kiếm vector đa chiều trong similarity search
Similarity search
Hiện nay, phương pháp phổ biến nhất trong Image Retrieval là dùng Similarity Search. Bắt đầu với một tập các vector có d chiều, Faiss sẽ tự tạo một cấu trúc dữ liệu từ RAM. Sau đó, vector mới sẽ được tính toán :
Trong Faiss, đây được gọi là tạo ra index, một object có khả năng add các vector
Phần tính toán được gọi là search trong index Faiss cho phép:
- Trả về nhiều kết quả có độ tương tự giống nhau
- Tìm kiếm nhiều vector cùng một lúc (còn gọi là batch processing)
- Lựa chọn giữa độ chính xác (precision) và tốc độ (accuracy). Ví dụ có thể giảm accuracy 10% để tăng gấp 10 tốc độ hoặc giảm 10 lần bộ nhớ
- ...
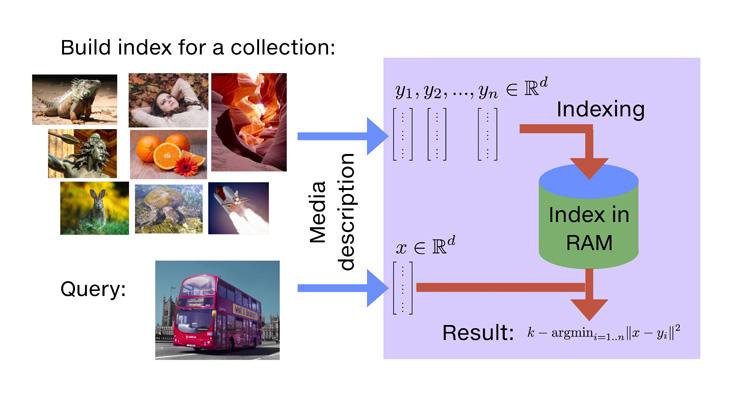
Similarity Search hiểu 1 cách đơn giản là đi tìm độ giống nhau giữa bức ảnh query và các bức ảnh khác trong dataset, sau đó trả về kết quả dựa trên sự giống nhau từ cao đến thấp. Khác với Image Classification, mỗi bức ảnh sẽ được phân loại vào 1 hoặc một vài class; với Image Retrieval, khi query là 1 bức ảnh thì kết quả trả về có thể là các bức ảnh thuộc class khác. Tham khảo https://www.facebook.com/machinelearningbasicvn/posts/436628436696993/
Các công cụ AI như mạng CNN được huấn luyện với mô hình deep learning, các ảnh sẽ được trích xuất thành các vector đa chiều với các feature đặc trưng, hay còn gọi là các feature vector. Độ tương đồng của 2 bức ảnh sẽ được so sánh bằng khoảng cách (ex: L2 distance) của 2 feature vector trích xuất từ 2 bức ảnh đó. Những ảnh có distance càng nhỏ thì càng giống nhau nhau; những distance nhỏ nhất sẽ được search bởi thuật toán k-selection.
II. Datasets
Mình sẽ sử dụng tập dữ liệu ảnh 102 loại hoa tại UK với 8189 bức ảnh. Mỗi loài có khoảng 40 đến 258 bức ảnh.
Các bạn có thể lấy data theo links sau
https://www.robots.ox.ac.uk/~vgg/data/flowers/102/index.html
Mình sẽ chia tập dataset thành tập train, test và valid với mỗi subfolder là 1 loại hoa, vậy tổng cộng có 102 subfolder

Okay, let's get started
Xây dựng Model
Bức ảnh của chúng ta sẽ được xử lý qua mạng CNN để thu được feature vector. Ta có thể sử dụng các mạng pretrain có sẵn như là ResNet hay VGG-16. Ví dụ, mạng ResNet50 sẽ có input (224, 224, 3) output (7, 7, 2048) với 23,587,712 tham số

Con số tương đối lớn với yêu cầu của bài toán, vì vậy mình đã rebuild lại mạng nhỏ hơn với resnet backbone
def resnet_backbone(input_layer, conv_size_muls=[1, 2, 4, 4], start_neurons=16, dropout_rate=None):
inner = None
for index, i in enumerate(conv_size_muls):
if index == 0:
inner = input_layer
inner = layers.Conv2D(start_neurons * i, (3, 3), activation=None, padding="same")(inner)
inner = residual_block(inner, start_neurons * i)
inner = residual_block(inner, start_neurons * i, True)
inner = layers.MaxPooling2D((2, 2))(inner)
if dropout_rate is not None:
inner = layers.Dropout(dropout_rate)(inner)
net = models.Model(inputs=[input_layer], outputs=inner)
return net
input_layer = layers.Input(name='the_input', shape=(384, 384, 3), dtype='float32')
base_net = resnet_backbone(
input_layer, conv_size_muls=[1, 1, 2, 2, 4, 4],
start_neurons=32, dropout_rate=None
)
print(base_net.output)
inner = layers.GlobalAveragePooling2D()(base_net.output)
inner = layers.Dropout(rate=0.25)(inner)
inner = layers.Dense(emb_size, name='embedding')(inner)
inner = layers.BatchNormalization()(inner)
inner = layers.Dropout(0.25)(inner)
output = ArcMarginProduct(102, s=s_value, m=m_value)(inner)
model = models.Model(inputs=base_net.input, outputs=output)
#cut 3 last layers
pred_model = models.Model(inputs=[model.input], outputs=model.layers[-3].output)

Model thu được có output lúc này là embedding vector 128 chiều với chưa đến 2 triệu tham số có kích thước đầu vào là ảnh kích cỡ (384, 384, 3)
III. Image Processing
Bài toán đặt ra là từ một ảnh hoa ban đầu chúng ta có thể tìm được các ảnh tương tự cũng như tên của loài hoa. Xử lý bức ảnh là bước tiền đề quan trọng để có thể trích xuất thông tin một cách chính xác.
Một bức ảnh tốt sẽ bao gồm chủ thể lớn, với đủ các chi tiết để có thể cho kết quả tốt nhất. Tuy nhiên, không phải bức ảnh nào trong thực tế đạt đủ tiêu chí đặt ra, chính vì vậy đòi hỏi việc tiền xử lý cũng phải được chú trọng hơn. Để có thể lấy ảnh về hoa chính xác hơn, ta cần phải khoanh vùng được bông hoa trong bức ảnh.
Ở đây, mình sẽ sử dụng thư viện Saliency Detection, giúp chúng ta có thể xác định được khu vực có chủ thể của bức ảnh.
Các bạn có thể tham khảo ở link này

Với Saliency prediction, chúng ta có thể khoanh vùng được chủ thể của bức ảnh, từ đó tạo được Bounding box cho hoa
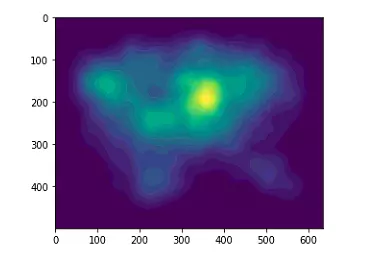

Với bức ảnh map trên, chúng ta có thể tạo được heat map cho bằng 1 phương pháp đơn giản đó là normalize ảnh predict, với các pixel trên mức threshold nhất định thì bằng 1, các pixel còn lại bằng 0
thres = 0.10
map_img = map_img / 255
map_img = map_img.astype(np.float32)
map_img[map_img >= thres] = 1
map_img[map_img < thres] = 0
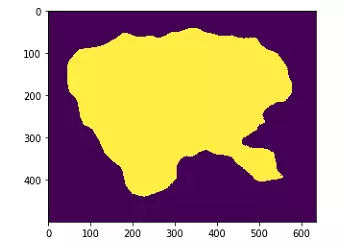
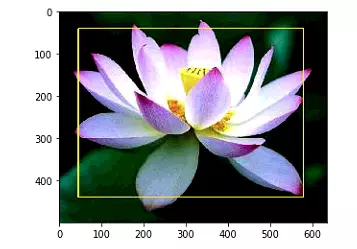
Lưu ý: Kết quả prediction sẽ lưu trong folder result của saliency, các bạn có thể chỉnh sửa hàm test_model để trả về ảnh prediction luôn nhé
Faiss tạo Index
Tạo index cho dữ liệu. Có nhiều loại index trong faiss, và mình chọn loại đơn giản nhất cho sử dụng L2 Euclide Distance là IndexFlatL2. Lựa chọn Index phù hợp sẽ phụ thuộc vào yêu cầu của bài toán, có thể tham khảo ở đây
https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
#Create Index
flower_index = faiss.IndexFlatL2(128)
fea_indexes = []
error_indexes = []
for img_index, img_fp in tqdm_notebook(id2img_fps.items()):
try:
img = image_preprocess(img_fp, expand=True)
embedded = pred_model.predict(img)
flower_index.add(embedded)
fea_indexes.append(img_index)
except Exception:
error_indexes.append(img_index)
continue

Quá trình index khoảng gần 2 phút với 6552 ảnh train, tương đối nhanh phải không ^_^
Các bạn có thể lưu lại file idex dưới dạng .bin để dùng lại sau 
Tìm kiếm
Chúng ta sẽ tiến hành search với ảnh đã crop theo bounding box đã được đánh dấu ở trên nhé

- Bước đầu tiên là xử lý ảnh:
- Đọc ảnh
- Resize về kích thước đầu vào của mạng (384, 384)
- Normalize ảnh
-
Trích xuất ra feature vector 128 chiều qua mạng CNN
-
Search và đưa ra top k ảnh có distance nhỏ nhất
img_prep = img_preprocess(img, expand=True)
test_fea = model.predict(img_prep)
f_dists, f_ids = flower_index.search(test_fea, k=7)
result_ids = f_ids[0][1:]
Kết quả thu được (distance và các index của ảnh)

 Cả 6 ảnh thu được đều có nhãn 78 - tức hoa sen
Cả 6 ảnh thu được đều có nhãn 78 - tức hoa sen
IV. Evaluating
Xây dựng hàm đánh giá kết quả
def total_metrics(train_embs, train_labels, test_embs, test_labels, top_k=5):
topk_correct = 0
mapk = []
for emb, label in zip(test_embs, test_labels):
dists = cdist(np.expand_dims(emb, axis=0), train_embs, metric='euclidean')[0]
min_dist_indexes = dists.argsort()[:top_k]
pred_labels = train_labels[min_dist_indexes]
mapk.append(map_per_image(str(label), list(map(str, pred_labels))))
if label in pred_labels:
topk_correct += 1
topk_value = topk_correct / test_embs.shape[0]
mapk = np.mean(mapk)
print(">>> Top{} acc: {:.4f}".format(top_k, topk_value))
print(">>> Map@{}: {:.4f}".format(top_k, mapk))
return topk_value, mapk
Kết quả top 1 và top 5:
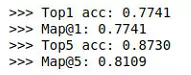
Kết quả top 5 là 0.87 và map là 0.81, không quá tệ với Image Retrieval phải không nào
Nhận xét
Model hoạt động tốt nhưng vẫn còn có thể cải tiến. Ví dụ
- Saliency sẽ detect chủ thể của bức ảnh. Chính vì vậy, nếu bức ảnh chụp hoa có ong hoặc động vật khác, rất có thể chúng ta sẽ không thu được ảnh crop chuẩn => Thực hiện flower classify trước khi đưa vào saliency
- Độ chính xác được cải thiện thêm khi áp dụng kỹ thuật dropout
- Có thể cải thiện tốc độ xử lý khi chuyển sang index bằng Hierarchical Navigable Small World. Kết quả tương đương với visual search https://github.com/ThomasDelteil/VisualSearch_MXNet
Source code
Các bạn có thể tham khảo source code tại đây
Xin được cám ơn mentor đã giúp đỡ hoàn thành bài viết này.
Cảm ơn các bạn đã đọc bài viết, nếu có bất kì sai sót hoặc thắc mắc nào, các bạn vui lòng comment bên dưới. Hẹn gặp lại trong các bài blog sắp tới!
Nguồn tham khảo
- Paper https://arxiv.org/abs/1702.08734
- https://engineering.fb.com/data-infrastructure/faiss-a-library-for-efficient-similarity-search/
- https://github.com/facebookresearch/faiss/wiki
- https://machinelearningcoban.com/2017/06/22/qns1/
- https://www.facebook.com/machinelearningbasicvn/posts/436628436696993/
- https://vladfeinberg.com/2019/07/18/faiss.html
- https://www.benfrederickson.com/approximate-nearest-neighbours-for-recommender-systems/
- https://towardsdatascience.com/understanding-faiss-619bb6db2d1a
All rights reserved
