Hướng dẫn xử lý dữ liệu phi cấu trúc: Trích xuất & Làm sạch văn bản
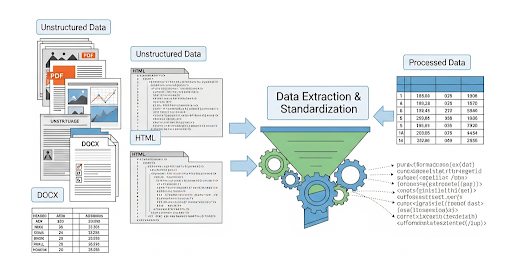
Trong hệ thống dữ liệu hiện đại, phần lớn thông tin mà doanh nghiệp lưu trữ không nằm trong cơ sở dữ liệu dạng bảng, mà ở các tài liệu PDF, DOCX, HTML hoặc nội dung sinh ra từ người dùng. Với Developer, đây là “vùng dữ liệu khó nhằn”, vì không có schema rõ ràng, chứa nhiều nhiễu và đòi hỏi quy trình xử lý tinh gọn để đưa vào AI pipeline hay phân tích sau này.
Bài viết này chia sẻ cách trích xuất và làm sạch văn bản từ dữ liệu phi cấu trúc, giúp bạn xây dựng pipeline chuẩn hóa dữ liệu hiệu quả cho mọi use case.
Dữ liệu phi cấu trúc là gì?
Nếu structured data giống như bảng SQL với các cột và kiểu dữ liệu xác định, thì unstructured data là phần “ngoài lề”, nơi mọi thứ đều có thể tồn tại: text, hình, video, audio, JSON không định dạng. Dưới góc nhìn kỹ thuật, có 3 loại phổ biến mà Dev thường gặp:
- PDF: hợp đồng, báo cáo tài chính, whitepaper… chứa xen kẽ chữ, bảng, hình ảnh. Việc extract text thường khó do format phức tạp hoặc file scan.
- DOCX: tài liệu Word có heading, paragraph, bảng, image, comment, thích hợp để đọc nội dung hoặc cấu trúc văn bản.
- HTML: mã nguồn web chứa text chính lẫn hàng tấn thẻ
<div>,<script>, quảng cáo, menu... cần lọc bỏ.
Điểm chung: không thể phân tích trực tiếp. Muốn đưa vào AI Agent hoặc analytics, bạn phải trích xuất, làm sạch và chuẩn hóa văn bản, đây chính là bước “data cleaning” căn bản của mọi data pipeline.
Tại sao cần xử lý dữ liệu phi cấu trúc?
Một file PDF hoặc HTML “thô” không giúp ích gì nếu không chuyển thành text sạch. Xử lý đúng cách mang lại lợi ích lớn:
- Tăng độ chính xác mô hình AI/ML: dữ liệu sạch = embedding chất lượng hơn.
- Tự động hóa phân tích: đọc và tách insight từ hợp đồng, phản hồi khách hàng, báo cáo.
- Giảm thao tác thủ công: không cần nhân viên copy-paste dữ liệu.
- Đảm bảo chất lượng data warehouse: loại bỏ “rác” trước khi nạp dữ liệu vào hệ thống.
Hướng dẫn trích xuất dữ liệu từ các định dạng phổ biến
1. Trích xuất từ PDF
Công cụ gợi ý:
import pdfplumber
with pdfplumber.open("sample.pdf") as pdf:
text = "\n".join(page.extract_text() for page in pdf.pages)
print(text)
- pdfplumber hoặc PyPDF2: đọc text theo từng trang.
- Nếu file là ảnh scan → dùng OCR (Tesseract):
tesseract input.pdf output.txt -l vie
Lưu ý: Một số PDF có layer bảo mật hoặc text bị vector hóa → cần giải mã hoặc OCR nhận dạng.
Trích xuất từ DOCX (Word)
from docx import Document
doc = Document("sample.docx")
text = "\n".join(p.text for p in doc.paragraphs)
print(text)
Ứng dụng thực tế:
- Lấy nội dung báo cáo, biên bản họp, hoặc bảng thống kê.
- Tiền xử lý trước khi chạy NLP (tokenization, sentiment analysis...).
Trích xuất từ HTML (Website)
Python – BeautifulSoup:
from bs4 import BeautifulSoup
import requests
html = requests.get("https://example.com").text
soup = BeautifulSoup(html, "html.parser")
text = " ".join(p.get_text() for p in soup.find_all("p"))
print(text)
Node.js – Cheerio:
const cheerio = require('cheerio');
const axios = require('axios');
const { data } = await axios.get("https://example.com");
const $ = cheerio.load(data);
const text = $("p").map((i, el) => $(el).text()).get().join(" ");
console.log(text);
Tips: loại bỏ các thẻ <script>, <style>, giữ lại phần nội dung chính (<p>, <h1-h6>, <div>).
Ứng dụng: crawl blog, mô tả sản phẩm TMĐT, nội dung tin tức để phân tích chủ đề hoặc tần suất từ khóa.
Pipeline làm sạch dữ liệu (Data Cleaning Flow)
Sau khi extract, dữ liệu thường bị lẫn ký tự rác, khoảng trắng, metadata. Một pipeline cơ bản nên gồm các bước:
🔹 Bước 1 – Remove Noise (ký tự rác)
import re
clean_text = re.sub(r"[^a-zA-Z0-9À-ỹ\s.,]", "", raw_text)
🔹 Bước 2 – Normalize (chuẩn hóa văn bản)
- Chuyển về chữ thường (lowercase)
- Chuẩn hóa Unicode UTF-8 để tránh lỗi font tiếng Việt. → “Khách HÀNG” → “khách hàng”.
🔹 Bước 3 – NLP Preprocessing
Áp dụng tokenization, stopword removal, lemmatization/stemming.
from underthesea import word_tokenize
tokens = word_tokenize(clean_text)
Mục tiêu: giúp mô hình hiểu ngữ nghĩa tốt hơn.
Ví dụ: “chạy”, “chạy bộ”, “chạy nhanh” → “chạy”.
🔹 Bước 4 – Loại bỏ HTML tag / metadata
from bs4 import BeautifulSoup
text_only = BeautifulSoup(html, "lxml").get_text()
Giữ lại text thuần, loại bỏ toàn bộ markup không cần thiết.
🔹 Bước 5 – Lưu trữ kết quả
Xuất file CSV/JSON để nạp vào hệ thống phân tích hoặc AI model.
Nếu cần tìm kiếm nhanh → index bằng Elasticsearch hoặc MongoDB full-text.
Ví dụ: thay vì mở từng file PDF, bạn có thể query “doanh thu quý 3” trong vài giây.
Kết luận
Xử lý dữ liệu phi cấu trúc không chỉ là “đọc text”, mà là cả quy trình Extract → Clean → Normalize → Export.
Với Dev, việc hiểu đúng pipeline và chọn đúng thư viện (pdfplumber, python-docx, BeautifulSoup, Regex, underthesea…) sẽ giúp tiết kiệm hàng giờ manual và mở đường cho việc tích hợp AI/ML, Search, Automation sau này.
Nếu bạn đang xây dựng hệ thống phân tích hoặc trợ lý AI nội bộ, đây chính là bước nền tảng mà không thể bỏ qua.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-xu-ly-du-lieu-phi-cau-truc-trich-xuat-va-lam-sach-van-ban.html
All rights reserved
