Giới thiệu về Connectionist Temporal Classification (CTC) (Phần 1)
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Trong nhận diện giọng nói hay nhận diện chữ viết tay, đầu ra sẽ là một câu, nhưng chưa hoàn chỉnh vì có các ký tự lặp lại như "heelllo", "toooo", ... hay các chữ có những khoảng trống (blank) như "he l l oo", "t o o", ... . Nguyên nhân dẫn tới những hiện tượng này là giọng nói dài (các đoạn ngân nga trong các bài hát, ...), giọng bị ngắt quãng, kích thước chữ viết tay lớn, nhỏ, ...
Do đó, để cho ra được một câu hoàn chỉnh thì ta cần phải căn chỉnh lại đầu ra ấy, loại bỏ các ký tự lặp lại và khoảng trống. Vấn đề này được gọi là alignment problem và nó được giải quyết bằng CTC.
Đầu tiên ta sẽ nói về temporal classification.
Temporal Classification là gì?
Gọi là tập huấn luyện gồm các mẫu từ một phân phối cố định , trong đó:
-
là một tập gồm tất cả các chuỗi (sequence) của các vectors số thực có độ dài là .
-
là một tập gồm tất cả các chuỗi chỉ có các ký tự alphabet có hạn của các labels. Các phần tử của còn được gọi là label sequences hay labellings.
Mỗi mẫu trong bao gồm một cặp chuỗi . Chuỗi mục tiêu (target sequence) có độ dài gần như chuỗi đầu vào (input sequence) , tức là .
Mục tiêu của ta là dùng để huấn luyện bộ temporal classifier để phân loại các chuỗi đầu vào chưa thấy trước đó (previously unseen input sequences) sao cho tối thiểu hóa một lượng mất mát (error measure) nào đó.
Một trong các error measure là label error rate (LER) được tính bằng trung bình của edit distance của đầu ra dự đoán và nhãn trong tập lấy từ :
Edit distance là số nhỏ nhất của số thêm vào (insertions), số thay thế (substitutions) và số xóa đi (deletions) để chuyển từ sang .
Vậy, temporal classifier là một mô hình phân loại nào đó mang tính thời gian (temporal). Và cũng vì thế, ở đây ta sẽ lấy RNN làm một temporal classifier cho gần gũi (thật ra ta có thể lấy bất kỳ model nào cho ra output theo thời gian).
Thế thì, connectionist ở đâu ra? Để trả lời cho điều đó, ta hãy qua cách thức hoạt động của CTC.
CTC hoạt động như thế nào?
Trước tiên, ta cần phải xác định đầu ra của RNN sao cho RNN là một temporal classifier.
Đầu ra của CTC Network: RNN
Như ta đã nói ở trên, bao gồm các ký tự trong bảng chữ cái của ngôn ngữ ta đang sử dụng, là tất cả các labellings có thể có.
Đầu ra của một CTC Network là kết quả của lớp softmax có số unit bằng số ký tự trong cộng thêm một ký tự trống (blank), nghĩa là xác suất phân loại của các ký tự trong tại một thời điểm nhất định.
Như vậy, tổ hợp của tất cả các đầu ra theo thời gian là . Dưới đây là hình minh họa.
Xác suất của một labelling
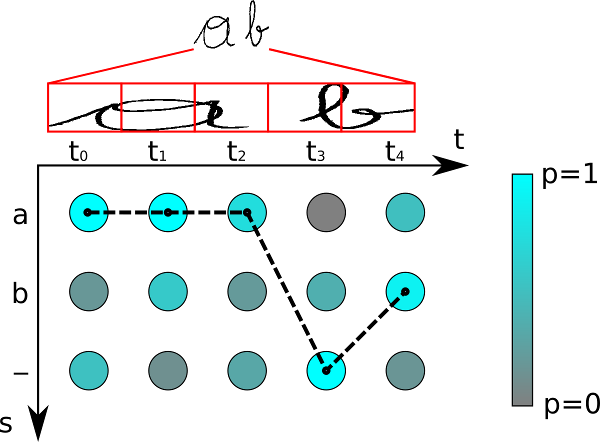
Xác suất của một labelling là tổng xác suất của tất cả các alignment cho ra labelling đó.
Gọi là một chuỗi của đầu ra của network, trong đó là kết quả của unit (ký tự - label) tại thời điểm . Khi đó thuộc phân phối trên tập của các chuỗi có độ dài trên tập chữ cái . Và xác suất của một alignment như sau:
Trong đó là path hay còn gọi là alignment. Và công thức ở trên giả định rằng đầu ra của network tại các thời điểm là độc lập với nhau.
Tiếp theo, ta định nghĩa một many-to-one map bằng cách loại bỏ các ký tự blank và ký tự lặp lại và dùng để tính xác suất của một labelling trong :
Xây dựng bộ phân loại
Từ công thức ở trên, đầu ra của bộ phân loại sẽ là labelling có vẻ đúng nhất.
Vậy làm sao để tìm ?
Trong bài báo này, họ đã đưa ra hai phương pháp:
- Best path decoding: trong đó là sự kết hợp của các unit có xác suất cao nhất của mỗi time-step, do đó không đảm bảo sẽ tìm thấy labelling đúng nhất.
- Prefix search decoding (PSD): phương pháp này dựa trên forward-backward algorithm, nếu có đủ thời gian, PSD sẽ luôn tìm thấy labelling phù hợp nhất, nhưng số lượng prefix tối đa sẽ tăng theo hàm mũ, phức tạp nên phải áp dụng heuristic.
Xây dựng hàm mất mát (CTC Loss function)
Ta sẽ xây dựng hàm mất mát để có thể train bằng gradient descent. Hàm mất mát được lấy theo maximum likelihood. Nghĩa là khi tối thiểu hóa nó thì sẽ cực đại hóa log likelihood.
Như vậy hàm mất mát (hàm mục tiêu) sẽ là negative log likelihood:
Tổng kết
Như vậy, một CTC Network chẳng qua là một network phân loại thông thường có output theo thời gian (temporal classifier), ta tính toán xác suất của các alignments bằng cách connect các xác suất của output của các thời điểm lại với nhau và chọn alignment phù hợp nhất, tính sai số của nó và cho network học lại. Vì thế họ gọi là Connectionist Temporal Classification.
Cách áp dụng các giải thuật decoding để tìm và tính hàm mất mát thì mình sẽ nói trong phần 2.
Tham khảo
All rights reserved
