
Trải lòng sau khi đọc GPT-4 Technical Report của OpenAI - các bác nên đổi tên công ty đi
Sự háo hức chờ đón GPT-4
Có lẽ chưa một năm nào mà chứng kiến sự vươn lên ngoạn mục của AI trong lòng công chúng như năm nay. Không thể phủ nhận rằng OpenAI đã làm quá tốt trong việc đưa AI đến với mọi người, mọi nhà. Đâu đâu cũng nghe về ChatGPT, về Midjourney, blah blah... Và cũng không để cho dân tình phải chờ đợi lâu thì ngày 14/3/2023, phiên bản nâng cấp thực sự của GPT-3 đã được công bố với cái tên GPT-4. Tất nhiên là một người làm trong lĩnh vực công nghệ, đặc biệt là làm trực tiếp trong mảng AI thì mình cũng vô cùng tò mò và háo hức đón chờ sự kiện công nghệ tầm cỡ thế giới này. Và cuối cùng mình cũng đợi được nó, ngay trên trang chủ của GPT-4 tại đây các bạn có thể thấy đi kèm với thông báo release GPT-4 thì họ đính kèm thêm rất nhiều các tài liệu hay ho và thực sự kích thích trí tò mò của một người làm công nghệ như mình. Và thứ mình quan tâm đầu tiên, dĩ nhiên rồi đó chính là Paper của GPT-4 vì đây chắc chắn là nơi mình có thể hiểu được tường tận GPT-4 nó là cái gì. Nếu bạn này lười vào trang chủ thì có thể xem trực tiếp paper này tại đây. Và nào, mở paper đó lên và chúng ta bắt đầu hành trình khám phá GPT-4 thôi.
Một paper "khủng"
Quào, nếu lần đầu bạn click vào paper này thì chắc chắn cũng thấy một chút choáng ngợp như mình bởi số trang của paper này lên đến CHÍN MƯƠI CHÍN TRANG , vâng các bạn không nghe nhầm đâu, 99 trang là gần tương đương với một thesis trong trường đại học thưa các bạn. Và ngay khi nhìn vào con số đó mình đã nghĩ sẽ phải thức trọn đêm nay để cày nát em nó. Và bản thân mình nghĩ rằng sẽ có rất rất nhiều thông tin mình có thể học được từ chiếc paper "khủng" này. Tuy nhiên lướt qua một chút về cấu trúc của paper này trước khi đọc kĩ vào chi tiết của từng phần thì mình mới thấy rằng nó thực ra cũng chẹp...chẹp.... thôi để lát nữa tiết lộ sau vậy, nói trước mất vui.

Nào, cũng dạo qua một lượt xem paper này nói những gì nhé. Nếu các bạn lướt qua một vòng của paper này thì sẽ thấy phần nội dung chính của paper chỉ nằm ở 19 trang đầu tiên, còn lại 80 trang tiếp theo là các phụ lục liên quan. Như vậy thì cũng đỡ choáng hơn rất nhiều rồi phải không nào. Bây giờ chúng ta sẽ cùng đi vào tìm hiểu các nội dung chính của paper và mình sẽ tóm tắt lại các nội dung chính cho các bạn nào lười đọc
Tóm tắt nội dung cho những ai lười đọc
Abstract
Mình tóm lược lại một số ý chính như sau:
- Đây là bản technical report nói về quá trình phát triển của GPT-4, một mô hình ngôn ngữ lớn, multimodal - gọi là multi cho sang chứ thực ra chỉ có two modal- model này có thể nhận input dầu vào bao gồm cả ảnh và text và đầu ra sẽ trả ra kết quả là text.
- Mô hình GPT-4 có hiệu suât tương đương con người trong một số tiêu chuẩn chuyên môn và học thuật khác nhau. Đặc biệt, nó vượt qua bài kiểm tra mô phỏng kì thi luật sư với số điểm nằm trong top 10% những người có điểm cao nhất.
- GPT-4 vẫn là một mô hình ngôn ngữ based trên Transformer và được huấn luyện để dự đoán, sinh ra các từ tiếp theo trong document.
- GPT-4 có thực hiện quá trình postraining alignment process, hiểu đơn giản giống như quá trình fine-tuning lại mô hình để có thể tăng thêm mức độ thực tế của câu trả lời cũng như tuân thủ cách hành vi được xác định trước
- Một phần quan trọng của dự án này là phát triển nền tảng infrastructure và các phương pháp tối ưu để có thể dự đoán được hiệu suất của mô hình (hay cụ thể là giá trị của hàm loss) với các scales khác nhau. Điều này giúp cho họ có thể dự đoán được chính xác một vài khía cạnh về hiệu suất của GPT-4 dựa trên các mô hình nhỏ hơn, sử dụng lượng tài nguyên tính toán nhỏ hơn cỡ 1000 lần lượng tài nguyên sử dụng để huấn luyện GPT-4. Đây là một trong những phần mình thấy khá hay ho. Nó được gọi là scaling laws tức là mối liên hệ giữa các đại lượng đầu vào như kích thước của mô hình, kích thước của dataset, thời gian tính toán đến độ chính xác hay giá trị loss của mô hình. Dựa trên scaling laws này thì có thể nội suy ra được các thông số cần thiết của lượng dữ liệu kích thước mô hình hay tài nguyên tính toán cần thiết để đạt được kết quả mong muốn.
Đó về nội dung của phần abstract là như vậy. Các bạn đọc xong cáci abstract này chắc hẳn sẽ rất tò mò nhiều câu hỏi giống như mình đúng không. Mình đã rất hứng thú và tự hỏi:
- Cụ thể kiến trúc mô hình của GPT-4 là gì?
- Cách mà họ thực hiện post-training alignment như thế nào?
- Cách mà họ mô phỏng bài kiểm tra luật sư và đo lường chất lượng như thế nào?
- Và phần họ nhấn mạnh nhất, họ đã xây dựng kiến trúc để huấn luyện GPT-4 như thế nào? Các phương pháp tối ưu mô hình đặc biệt mà họ nói đến là gì?
Tất cả những điều đó thực sự làm mình cảm thấy tò mò, và chắc hẳn các bạn cũng vậy. Và câu trả lời sẽ được giải đáp trong những phần tiếp theo. Bạn hãy cố gắng đọc tiếp nhé. Chúng ta sắp biết câu trả lời rồi đấy.
1. Introduction
Nhìn chung phần này cũng nêu lại một số điểm nổi bật hơn của GPT-4 so với các mô hình trước đó chứ không có gì đặc biệt cả. Túm gọn lại một số ý chính như sau:
- Multimodal model: như đã nói ở trước, mô hình này có thể nhận đầu vào cả image và text, đầu ra là text
- Improved natural language understanding and generation: Một trong những mục tiêu của việc phát triển các mô hình ngôn ngữ lớn như GPT-4 là để tăng cường khả năng hiểu và sinh ra các đoạn ngôn ngữ tự nhiên đặc biệt là trong các ngữ cảnh phức tạp, đa sắc thái.
- High performance on traditional NLP benchmarks: GPT-4 vượt trội hơn so với các mô hình ngôn ngữ được phát triển trước đó trên các tác vụ NLP
- Strong performance in multiple languages: GPT-4 không chỉ vượt trội trên tiếng anh mà nó còn thể hiện hiệu quả mạnh mẽ trên các ngôn ngữ khác. Nó vượt qua SOTA đo trên tiếng Anh ở 24/26 ngôn ngữ được kiểm tra
Tuy nhiên ngoài các ưu điểm trên thì GPT-4 còn có một số nhược điểm cố hữu của LLM như:
- Có thể sinh ra các kết quả không có thật và gây ra ảo giác - hallucinations. Các bạn nào muốn biết rõ hơn thì tham khảo bài viết mình đã viết trước đó ChatGPT hay là "Chết GPT"?
- Mô hình GPT-4 vẫn bị giới hạn context window
- GPT-4 không tự được học từ kinh nghiệm trong quá khứ
- Cần thận trọng khi sử dụng kết quả đầu ra của GPT-4, đặc biệt là trong các ngữ cảnh mà độ tin cậy là quan trọng.
- Các khả năng và hạn chế của GPT-4 tạo ra những thách thức an toàn mới và đáng kể, đòi hỏi phải nghiên cứu và giảm thiểu cẩn thận.
Nhìn chung là cũng vấn khá chung chung. Giờ chúng ta sẽ đi vào phần tiếp theo để xem họ giải thích như thế nào nhé. Tiếp tục nào
2. Scope and Limitations of this Technical Report - sự thất vọng bắt đầu
Phần này mới là phần đáng nói nhất trong cái Technical Report này. Sau bao nhiêu sự háo hức từ lúc đầu đến bây giờ của mình gần như bị dập tắt khi đọc đến phần này. Các bạn có thể xem hình dưới

Đại ý của đoạn bôi vàng như sau:
Xét trong bối cảnh cạnh tranh và để đảm bảo sự an toàn của các mô hình ngôn ngữ như GPT-4, báo cáo này KHÔNG CHỨA THÊM THÔNG TIN CHI TIẾT NÀO về kiến trúc (bao gồm cả kích thước mô hình), phần cứng, tài nguyên tính toán sử dụng để huấn luyện, cách xây dựng tập dữ liệu, phương pháp huấn luyện, v.v.
Tức là họ KHÔNG CHIA SẺ bất cứ thông tin gì về GPT-4 mà mình và các bạn đang muốn biết. U là trời, vậy các bác viết đến tận 98 trang giấy chỉ để khoe thôi à trời. Điều này thực sự không giúp cho mình cảm thấy thoả mãn, và chính cái cách mà OpenAI viết một paper 99 trang khiến cho đại đa số nhiều người lầm tưởng rằng nó là open source hoặc ít nhất là có thể biết được một chút gì đó về nó nhưng câu trả lời là KHÔNG CÓ GÌ CẢ - NOTHING AT ALL
3. Predictable Scaling
Nhìn phần trên đã thấy hơi nản một chút rồi nhưng chẳng lẽ viết đến đây rồi lại không viết nốt thì phụ lòng các bạn quá. Dù cho OpenAI không có nói rõ chi tiết cách học thực hiện như thế nào trong phần này nhưng chúng ta vẫn có thể tóm gọn lại một vài điểm chính như sau:
- Scaling laws giúp chúng ta xác định được mối tương quan giữa giá trị của loss hoặc độ chính xác với các yếu tố đầu vào như kích thước tập dữ liệu, kích thước mô hình, số lượng tài nguyên tính toán ... Điều này đặc biệt có ý nghĩa khi huấn luyện các mô hình có kích thước lớn như mô hình ngôn ngữ
- Trong đoạn này, OpenAI có nói rằng họ đã thiết kế kiến trúc phần cứng và tài nguyên tính toán một cách rất hợp lý để có thể dự đoán được chính xác xem giá trị loss của mô hình GPT-4 sẽ đạt được là bao nhiêu (hay nói các khác là nó chính xác đến như thế nào) khi bổ sung thêm tài nguyên tính toán để huấn luyện. Việc dự đoán scaling này được thực hiện dựa trên các mô hình có kích thước nhỏ hơn và cùng một tác vụ và cùng một chiến lược training. Các bạn có thể thấy trong hình sau
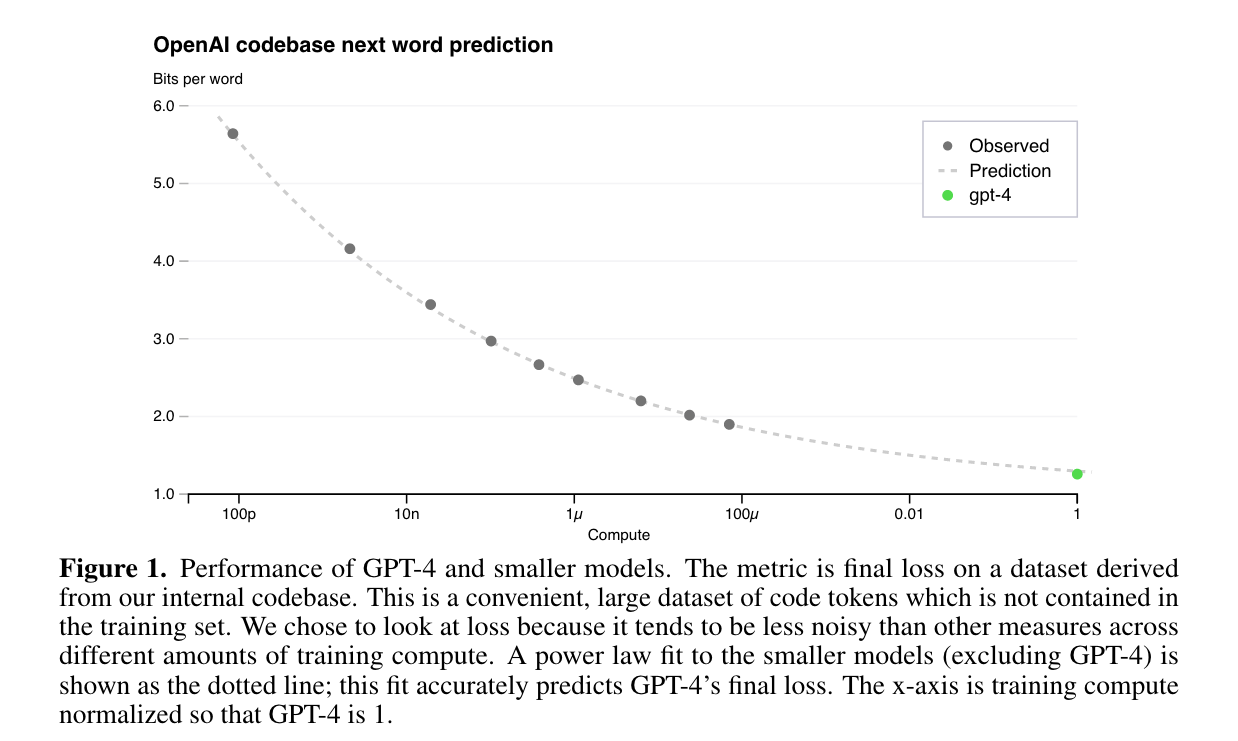
- Nhiều bạn sẽ hỏi rằng điều này có ý nghĩa ra sao. Như các bạn thấy trong các hình trên, họ thiết kế kiến trúc infrastructure và các chiến lược tối ưu để thoả mãn scaling laws. Đường nét đứt là đường được fit theo scaling laws với các chấm tròn là giá trị loss thu được khi huấn luyện các mô hình nhỏ hơn và lượng tài nguyên tính toán thấp hơn. Khi việc fit này đã chính xác trên các mô hình nhỏ hơn rất nhiều lần (huấn luyện hết ít tiền hơn 😀😀😀) thì họ hoàn toàn có thể dự đoán được sẽ cần bao nhiêu tài nguyên tính toán để đạt được độ chính xác mong muốn. Điều này là rất quan trọng khi mà training những mô hình ngôn ngữ lớn như GPT-4 chẳng khác nào đốt tiền.
Một vài kết quả mà OpenAI đã "khoe"
Phần lớn các ý chính của Tehcnical Report này mình đã trình bày ở trên rồi. Còn lại thì đa phần là các nội dung mang tính chất tự sướng và khoe thành tích của GPT-4 so với các mô hình trước đó. Tiêu biểu có thể kể đến vài thứ như
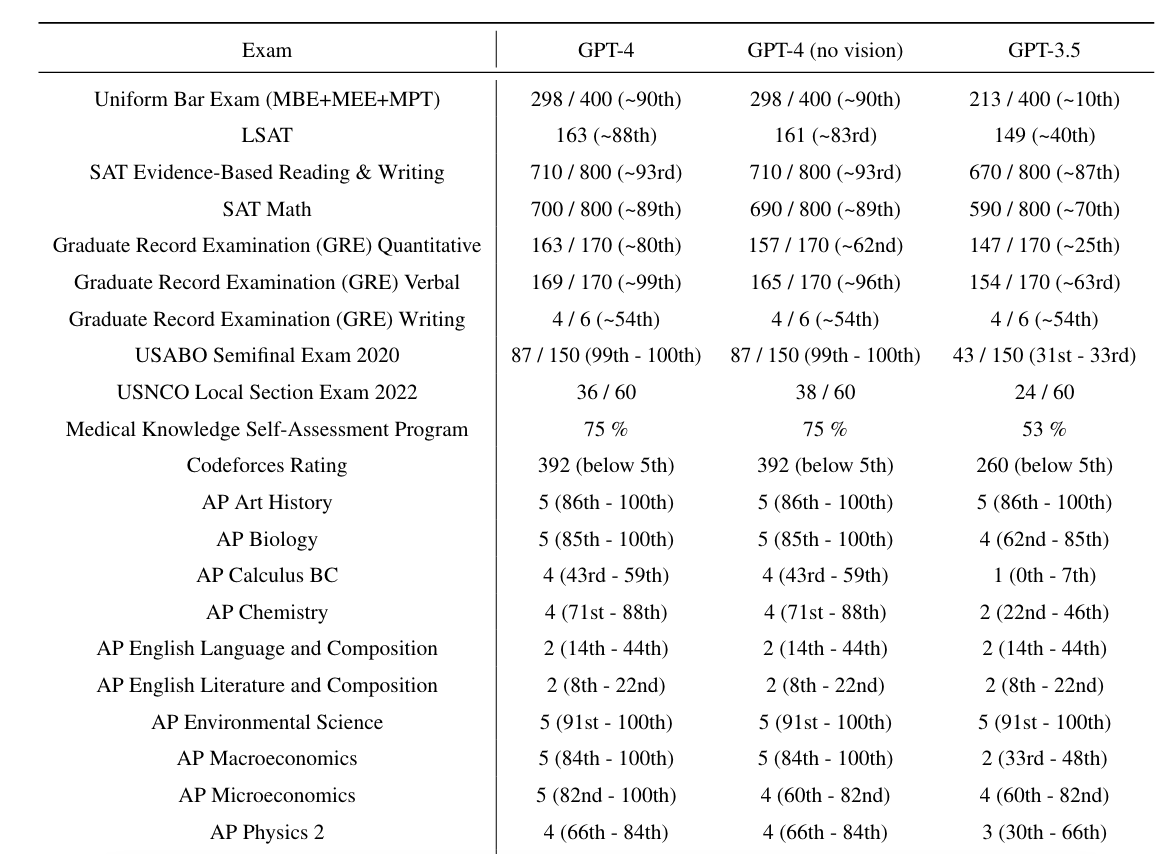
Vượt qua kì thi
Trong số nhiều kết quả được OpenAI đánh dấu, điều nổi bật ngay lập tức là hiệu suất của GPT-4 trên một loạt các bài kiểm tra tiêu chuẩn hóa. Ví dụ: GPT-4 đạt điểm trong số 10% có điểm cao nhất trong kỳ thi luật sư mô phỏng của Hoa Kỳ, trong khi điểm GPT-3.5 nằm trong 10% điểm thấp nhất.
Trả lời trên cả thông tin hình ảnh
Đưa ra các câu trả lời trên cả text và hình ảnh như hình bên dưới

Hay thậm chí còn giải cả bài thi vật lý

Suy luận tốt hơn so với ChatGPT
Có thể so sanh cùng câu trả lời của GPT-4 và ChatGPT về một vấn đề.
GPT-4 kiểu:
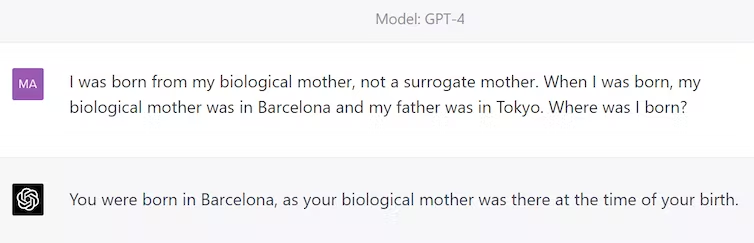
ChatGPT kiểu:

Context lớn hơn, text sinh ra dài hơn
GPT-4 có thể nhận và tạo tối đa 25.000 từ văn bản, nhiều hơn nhiều so với giới hạn khoảng 3.000 từ của ChatGPT.
Nó có thể xử lý các lời nhắc phức tạp và chi tiết hơn, đồng thời tạo ra các đoạn văn bản mở rộng hơn. Điều này cho phép kể chuyện phong phú hơn, phân tích sâu hơn, tóm tắt các đoạn văn bản dài và tương tác đàm thoại sâu hơn.
Trong ví dụ dưới đây, mình đã đưa cho ChatGPT mới (sử dụng GPT-4) toàn bộ bài viết trên Wikipedia về trí tuệ nhân tạo và hỏi nó một câu hỏi cụ thể, nó đã trả lời chính xác.
Các hạn chế
Mình vẫn giữ quan điểm giống như đã chia sẻ trong ChatGPT hay là "Chết GPT"? đối với các mô hình ngôn ngữ. Dù OpenAI có nói rằng họ đã và đang cố gắng để cải thiện chúng nhưng mình nghĩ đó vẫn là các câu chuyện trong tương lai và cần phải có nhiều thời gian để kiểm chứng. Bản thân trong techincal report họ cũng chỉ ra một số điểm hạn chế như:
- Có thể sinh ra các kết quả không có thật và gây ra ảo giác - hallucinations. Các bạn nào muốn biết rõ hơn thì tham khảo bài viết mình đã viết trước đó ChatGPT hay là "Chết GPT"?
- Mô hình GPT-4 vẫn bị giới hạn context window
- GPT-4 không tự được học từ kinh nghiệm trong quá khứ
- Cần thận trọng khi sử dụng kết quả đầu ra của GPT-4, đặc biệt là trong các ngữ cảnh mà độ tin cậy là quan trọng.
- Các khả năng và hạn chế của GPT-4 tạo ra những thách thức an toàn mới và đáng kể, đòi hỏi phải nghiên cứu và giảm thiểu cẩn thận.
Lời nhắn nhủ
Mình thiết nghĩ OpenAI đang và sẽ chuyển dần sang hướng làm AI product và mong muốn kinh doanh trên sản phẩm của họ. Tất nhiên, họ có quyền làm như thế nhưng những bài báo như thế này thực sự không mang lại quá nhiều giá trị cho cộng đồng công nghệ ngoài việc PR cho OpenAI và sản phẩm mới của họ. Và sẽ có rất nhiều bạn sẽ nhảy dựng lên và nói rằng Ông này chỉ giỏi chê bai, có làm được như người ta không mà nói. Đúng, mình có thể chưa làm được nhưng mình hiểu rằng giá trị của việc chia sẻ trong cộng đồng công nghệ là vô cùng lớn. Nó không những giúp cho chúng ta hoàn thiện bản thân mình hơn nhờ sự góp ý của cộng đồng, mà còn giúp cộng đồng công nghệ được thừa hưởng những bước tiến công nghệ mới và ngày một tốt lên. Nên cá nhân mình thấy GPT-4 Technical Report chỉ là một bài quảng cáo giả danh một bài báo khoa học và nó thực sự như một cái tát vào chính thương hiệu của họ. Nó khác hẳn cái cách mà Facebook AI Research đã làm khi công bố LLaMA, hay Google khi công bố Transformer hay Kubernetes trước đó. Và nó cũng sẽ trở thành một tiền lệ rất xấu trong giới công nghệ, khi mà chẳng còn ai muốn chia sẻ nữa, và người thiệt thòi nhất là chính chúng ta mà thôi
P/S: Các bạn nghĩ sao với đề xuất của mình ở tiêu đề, liệu rằng OpenAI có nên đổi tên thương hiệu mới là CloseAI hay không?
All rights reserved
