Tìm hiểu về Semantic Annotation - Phần 6(phần cuối) : Information Extraction trong Sematic Annotation
Bài đăng này đã không được cập nhật trong 4 năm
Khai thác thông tin là một trong những mục đích quan trọng nhất trong kỷ nguyên công nghệ thông tin hiện nay, trong bài cuối của seri tìm hiểu về Semantic Annotation này, mình sẽ nêu các khái niệm, cách thức khai thác thông tin bằng semantic annotation.
1 - What is Information Extraction (Khai thác thông tin là gì) ?
Khai thác thông tin là quá trình trích xuất thông tin cụ thể (được chỉ định trước) từ các nguồn văn bản.
Một trong những ví dụ mà bạn làm thường ngày là check mail, lấy nội dung thông tin từ email và add vào Calendar của mình đấy 
Các nguồn văn bản bao gồm từ nhiều nguồn, nhiều lĩnh vực khác nhau, việc tự động hóa khai thác thông tin sẽ mang lại lợi ích như :
- Tự động hóa các nhiệm vụ như phân loại nội dung thông minh, tìm kiếm tích hợp, quản lý và phân phối;
- Khai thác thông tin, từ đó đưa ra các xu hướng, nhận định các mối quan hệ ẩn đàng sau thông tin
Trang web dưới đây là một ví dụ trong việc gắn tag, phân tích quan hệ dữ liệu và đưa ra các xu hướng : https://link.sun-asterisk.vn/p3mDPA
Việc khai thác và đưa ra thông tin thường được thực hiện qua 3 bước : Tagging , Content Classification và Recommendation .
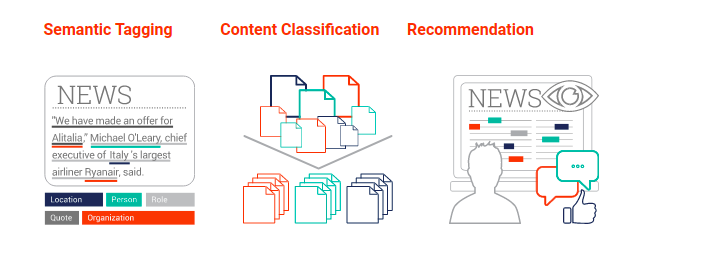
2- Các thức hoạt động của Semantic Annotation đối với Information Extraction
Đầu tiên, đối với Semantic Annotation , quan trọng nhất là có tập hợp Ontology để định nghĩa dữ liệu. Đối với kỹ thuật này, Ontology như là bộ từ vựng của cơ sở tri thức vậy.
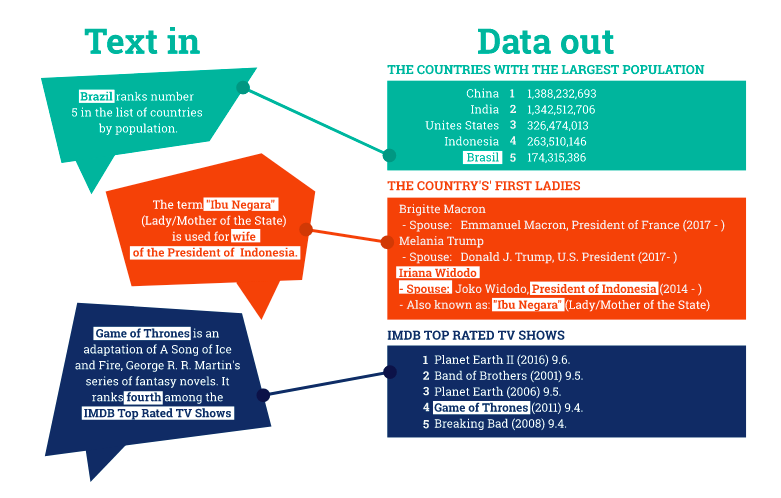
Để Trích xuất dữ liệu, ta cần thực hiện các bước cơ bản sau đây :
- Xử lý trước văn bản đây là nơi văn bản được chuẩn bị để xử lý với sự trợ giúp của các công cụ ngôn ngữ học tính toán như tách câu, phân tích từ ngữ, định dạng ngôn ngữ , v.v.
- **Tìm kiếm và phân loại các khái niệm ** Dựa vào bộ từ vựng (ontology) để định nghĩa , phát hiện và phân loại các chủ thể liên quan như : Con người, sự vật, địa điểm, sự kiện ....
- Kết nối các khái niệm Hay các khác, đây là bước trích xuất ngữ nghĩa: Khi có các định nghĩa, ta sẽ trích xuất ngữ nghĩa theo dạng triple
- Unifying Bước này sẽ tổng hợp các dữ liệu thành một khối dữ liệu hoàn chỉnh, mapping ý nghĩa và xây dựng thành mô hình ngữ nghĩa graphdb.
- Getting rid of the noise Loại bỏ nhiễu - hạn chế các dữ liệu trùng lặp, chuẩn hóa ngữ nghĩa
- Enriching your knowledge base Tạo dữ liệu thành cụm knowledge base , để trích xuất, truy vấn.
Khai thác thông tin có thể hoàn toàn tự động hoặc được thực hiện với sự trợ giúp của đầu vào của con người.
3 - Ví dụ về khai thác thông tin
Ví dụ :
Marc Marquez was fastest in the final MotoGP warm-up session of the 2016 season at Valencia, heading Maverick Vinales by just over a tenth of a second.
After qualifying second on Saturday behind a rampant Jorge Lorenzo, Marquez took charge of the 20-minute session from the start, eventually setting a best time of 1m31.095s at half-distance.
Thông qua việc trích xuất thông tin, các sự kiện cơ bản sau đây có thể được trích xuất văn bản và được tổ chức dưới dạng có cấu trúc, dễ đọc bằng máy:
Person: Marc Marquez Location: Valencia Event: MotoGP Related mentions: Maverick Vinales, Yamaha, Jorge Lorenzo
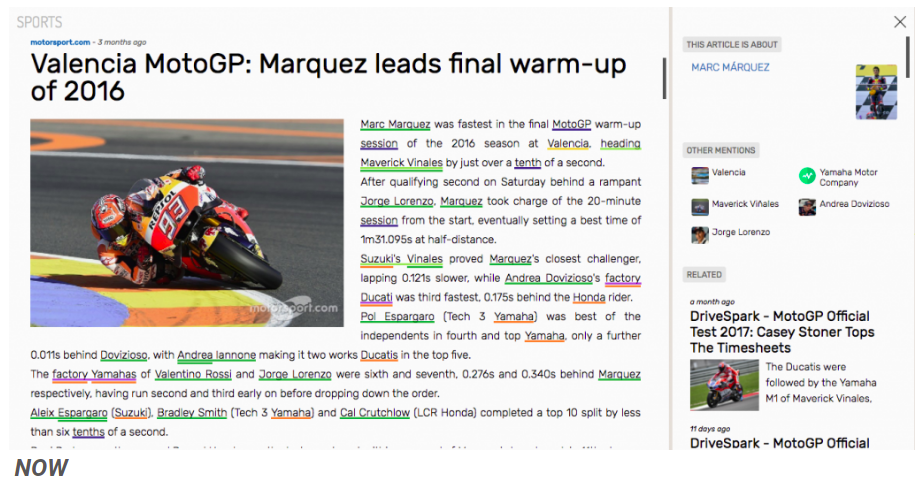
Để xem nhiều hơn về ví dụ, bạn có thể truy cập trang web dưới đây :
4 - Lời kết
Vậy là đã qua 6 phần về Semantic Annotation. Như mình đã nói, đây không phải kỹ thuật mới, và cũng không hề lạc hậu. Bằng chứng là nó đang từng ngày được các công ty lớn như google, wiki đưa vào sử dụng . Semantic Annotation là kỹ thuật ít người tìm hiểu và nghiên cứu ở Việt Nam, kiếm thức mình chia sẻ cũng chỉ là basic trong Semantic Annotation , mong rằng những ai đọc đến đây có thể hiểu cơ bản về lĩnh vực này và tiếp tục tìm hiểu nó.
All rights reserved
