Tìm hiểu về phương pháp nhận diện khuôn mặt của Violas & John
Bài đăng này đã không được cập nhật trong 5 năm
Phát hiện mặt người là bài toán cơ bản được xây dựng từ nhiều năm nay, có nhiều phương pháp được đưa ra như sử dụng template matching, neuron network…Cho tới nay bài toán này hầu như được giải quyết dựa trên phương pháp sử dụng các đặc trưng haar like. Phương pháp này được cho là đơn giản và kết quả phát hiện là tương đối cao, lên tới 98%, các hãng sản xuất máy ảnh như Canon, Samsung… cũng đã tích hợp nó vào trong các sản phẩm của mình. Và trong bài viết này, mình sẽ cùng các bạn tìm hiểu về phương pháp pháp phát hiện khuôn mặt của Violas và John được cài đặt trong OpenCV.
1. Các đặc trưng Haar-Like
Các đặc trưng Haar-Like là những hình chữ nhật được phân thành các vùng khác nhau như hình:
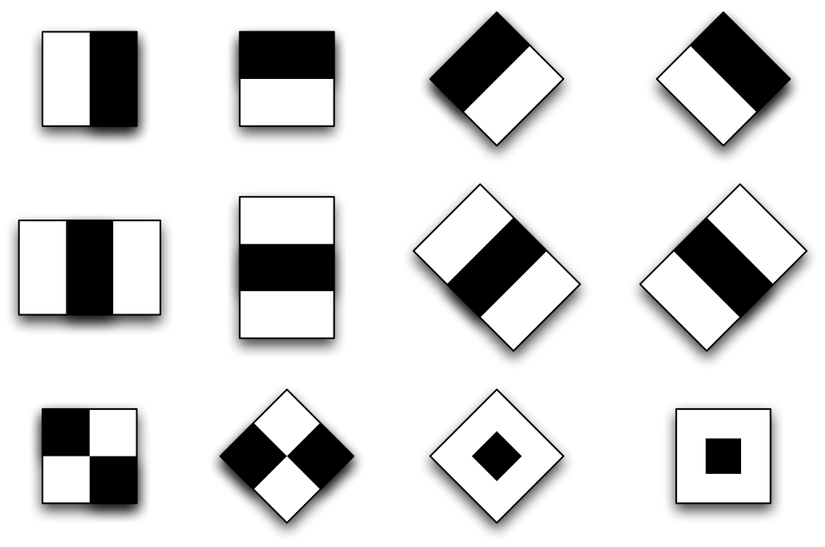
Đặc trưng do Viola và Jones công bố gồm 4 đặc trưng cơ bản để xác định khuôn mặt người. Mỗi đặc trưng Haar-Like là sự kết hợp của hai hay ba hình chữ nhật trắng hay đen như trong hình sau:

Để sử dụng các đặc trưng này vào việc xác định khuôn mặt người, 4 đặc trưng Haar-Like cơ bản được mở rộng ra và được chia làm 3 tập đặc trưng như sau:
-
Đặc trưng cạnh(edge feature)
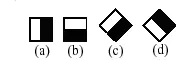
-
Đặc trưng đường(line feature)
-
Đặc trưng xung quanh tâm(center-surround features)
Dùng các đặc trưng trên, ta có thể tính được các giá trị của đặc trưng Haar-Like là sự chênh lệch giữa tổng của các pixel của vùng đen và vùng trắng như trong công thức sau:
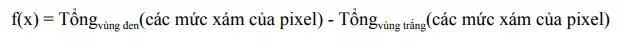
Viola và Joines đưa ra một khái niệm gọi là Integral Image, là một mảng 2 chiều với kích thước bằng với kích thước của ảnh cần tính đặc trưng Haar-Like, với mỗi phần tử của mảng này được tính bằng cách tính tổng của điểm ảnh phía trên (dòng-1) và bên trái (cột-1) của nó.
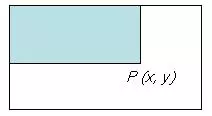
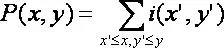
Sau khi tính được Integral Image, việc tính tổng các giá trị mức xám của một vùng bất kỳ nào đó trên ảnh thực hiện rất đơn giản theo cách sau:
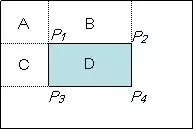
Giả sử ta cần tính tổng giá trị mức xám của vùng D như hình dưới, ta có thể tính được như sau:
Với A + B + C + D chính là giá trị tại điểm P4 trên Integral Image, tương tự như vậy A+B là giá trị tại điểm P2, A+C là giá trị tại điểm P3, và A là giá trị tại điểm P1. Vậy ta có thể viết lại biểu thức tính D ở trên như sau:
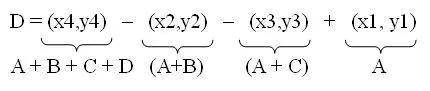
2. AdaBoost
AdaBoost là một bộ phân loại mạnh phi tuyến phức dựa trên hướng tiếp cận boosting được Freund và Schapire đưa ra vào năm 1995. Adaboost cũng hoạt động trên nguyên tắc kết hợp tuyến tính các weak classifiers để hình thành một trong các classifiers.
Viola và Jones dùng AdaBoost kết hợp các bộ phân loại yếu sử dụng các đặc trưng Haar-like theo mô hình phân tầng (cascade) như sau:
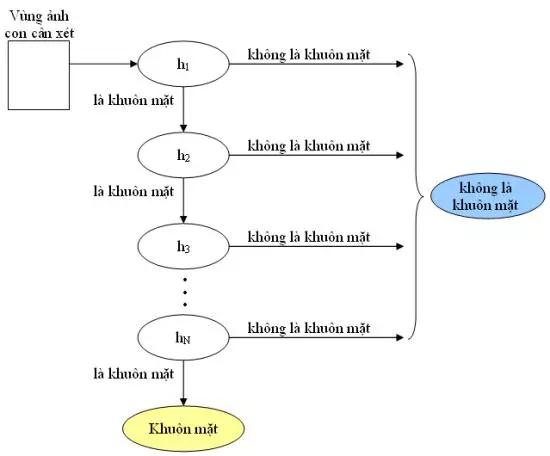
Trong đó, h(k) là các bộ phân loại yếu, được biểu diễn như sau:
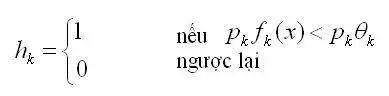
với:

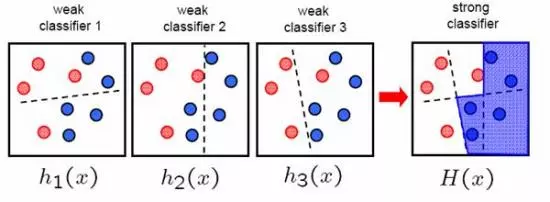
AdaBoost sẽ kết hợp các bộ phân loại yếu thành bộ phân loại mạnh như sau:
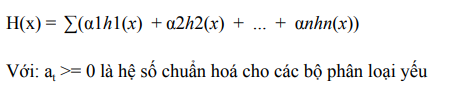
Đây là hình ảnh minh họa việc kết hợp các bộ phân loại yếu thành bộ phân loại mạnh
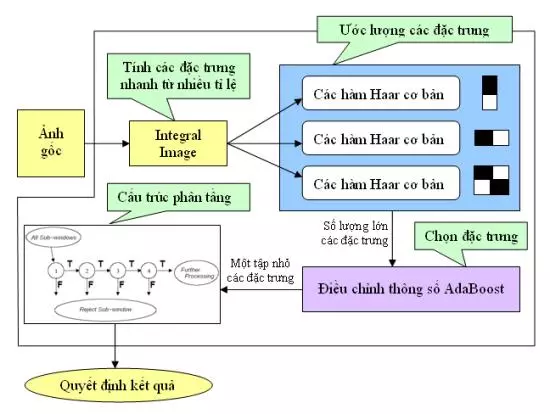
3. Sơ đồ nhận diện khuôn mặt
Source Code tham khảo
https://github.com/HaiHaChan/mmdb_20171
Tài liệu tham khảo
[1] http://kdientu.duytan.edu.vn/media/49682/le-dac-thinh-bao-cao-nckh.pdf
All rights reserved
