Tăng cường dữ liệu trong deep learning
Bài đăng này đã không được cập nhật trong 4 năm
Hiện nay trong deep learning thì vấn đề dữ liệu có vai trò rất quan trọng. Chính vì vậy có những lĩnh vực có ít dữ liệu để cho việc train model thì rất khó để tạo ra được kết quả tốt trong việc dự đoán. Do đó người ta cần đến một kỹ thuật gọi là tăng cường dữ liệu (data augmentation) để phục vụ cho việc nếu bạn có ít dữ liệu, thì bạn vẫn có thể tạo ra được nhiều dữ liệu hơn dựa trên những dữ liệu bạn đã có. Ví dụ như hình dưới, đó là các hình được tạo ra thêm từ một ảnh gốc ban đầu.
Ví dụ :

Lý thuyết về tăng cường dữ liệu
Vì mình có đọc một số bài trên mạng, và thấy bài này khá hay, nên mình cũng không cần trình bày lại lý thuyết làm gì cho mất công. Mình xin trích dẫn bài của ngcthuong ở đây:
Phương thức data aumentation cơ bản cho thị giác máy:
- Original (Ảnh gốc): dĩ nhiên rồi, bao giờ mình cũng có ảnh gốc
- Flip (Lật): lật theo chiều dọc, ngang miễn sao ý nghĩa của ảnh (label) được giữ nguyên hoặc suy ra được. Ví dụ nhận dạng quả bóng tròn, thì mình lật kiểu gì cũng ra quả bóng. Còn với nhận dạng chữ viết tay, lật số 8 vẫn là 8, nhưng 6 sẽ thành 9 (theo chiều ngang) và không ra số gì theo chiều dọc. Còn nhận dạng ảnh y tế thì việc bị lật trên xuống dưới là không bao giờ sảy ra ở ảnh thực tế --> không nên lật làm gì
- Random crop (Cắt ngẫu nhiên): cắt ngẫu nhiên một phần của bức ảnh. Lưu ý là khi cắt phải giữ thành phần chính của bức ảnh mà ta quan tâm. Như ở nhận diện vật thể, nếu ảnh được cắt không có vật thể, vậy giá trị nhãn là không chính xác.

- Color shift (Chuyển đổi màu): Chuyển đổi màu của bức ảnh bằng cách thêm giá trị vào 3 kênh màu RGB. Việc này liên quan tới ảnh chụp đôi khi bị nhiễu --> màu bị ảnh hưởng.
- Noise addition (Thêm nhiễu): Thêm nhiễu vào bức ảnh. Nhiễu thì có nhiều loại như nhiễu ngẫu nhiên, nhiễu có mẫu, nhiễu cộng, nhiễu nhân, nhiễu do nén ảnh, nhiễu mờ do chụp không lấy nét, nhiễu mờ do chuyển động… có thể kể hết cả ngày.
- Information loss (Mất thông tin): Một phần của bức hình bị mất. Có thể minh họa trường hợp bị che khuất.
- Constrast change (Đổi độ tương phản): thay độ tương phản của bức hình, độ bão hòa

- Geometry based: Đủ các thể loại xoay, lật, scale, padding, bóp hình, biến dạng hình,
- Color based: giống như trên, chi tiết hơn chia làm (i) tăng độ sắc nét, (ii) tăng độ sáng, (iii) tăng độ tương phản hay (iv) đổi sang ảnh negative - âm bản.
- Noise/occlusion: Chi tiết hơn các loại nhiễu, như mình kể trên còn nhiều lắm. kể hết rụng răng.
- Whether: thêm tác dụng cảu thời tiết như mưa, tuyết, sương mờ, …
Một số ví dụ khác
-
Transitional: quả bóng dịch sang trái phải :
![]()
-
Scale: chuyển đổi kích thước bức hình
![]()
-
Scale vào trong
![]()
-
Dùng GAN đổi ngày thành đêm, xuân thành hạ
![]()
-
Dùng GAN đổi style bức hình





Lưu ý rằng [4] việc sử dụng data aumgentation nên thực hiện ngẫu nhiên trong quá trình huấn luyện. Và việc dùng GAN là tạo dữ liệu ko có trước, có thể có tác dụng phụ.
Vấn đề của data augmentation!
Tính phụ thuộc dữ liệu và ứng dụng
Vấn đề là “con vịt nào cũng béo vặt lông con nào”, quá nhiều cách thức augmentation, chọn cách nào để cho chất lượng tốt nhất đây? Câu trả lời là - tùy thuộc vào dữ liệu (số lượng mẫu, tính balance/imbalance của mẫu, dữ liệu test, v.v. và ứng dụng tương ứng. Nghĩa là mỗi bộ dữ liệu sẽ có cách thức riêng để augmentation sao cho ra kết quả tốt nhất.
Điển hình là dữ liệu MNIST được cho là tốt với phương pháp elastic distortion, scale, translation, và rotation. Trong khi dữ liệu ảnh tự nhiên như CIFAR10 và ImageNet thì lại tốt với thuật toán random-cropping, iamge miroring, color shiffting/whitenting [8]. Không chỉ có vậy mà một số augmentation method không tốt cho một số tập dữ liệu. Đơn cử là hroizontal flipping tốt cho CIFAR10 nhưng không tốt cho MNIST ( bởi vì flip là thành ra số khác rồi còn gì).
Sự đa dạng của augmentation
Với danh sách các thương thức augmentation kể trên thì cũng còn nhiều cách thức mình chưa liệt kê hết. Bản thân mỗi augmenation lại có các Yếu tố điều khiển riêng. Mình có thể phân loại thành
- Các phương thức augmentation: flip, rotation, random crop, v.v.
- Các yếu tố điều khiển augmentation: mỗi augmenation sẽ có các yếu tố điều khiển riêng. Ví dụ rotation thì bao nhiêu độ, scaling thì scaling lên xuống bao nhiêu lần, crop random thì random trong khoảng bao nhiêu …
- Tần suất sử dụng từng phương thức augmentation?
- Cách augmentation tốt nhất là một bộ các phương thức augmentation
- Cách augmenation cho từng giai đoạn training/epoch có thể khác nhau. Epoch đầu ở leanring rate lớn có thể khác với các epoch cuối ở learning rate nhỏ
- Cách augmenation cho từng class, tần suất dùng augmenation có thể khác nhau
- Cách augmenation cũng có thể bị ảnh hưởng bở cấu trúc mạng. Tức là augmentation cho mức gain khác nhau tới từng network Và không phải các yếu tố kể trên có tác động giống nhau tới mức độ cải thiện chất lượng của augmentation.
Cách augmentation tốt nhất?
Việc phụ thuộc vào dữ liệu và ứng dụng, kiến trúc mạng,kể trên đồng nghĩa với việc bạn cần phải thử kha khá, và chắc chắn sẽ tốn rất nhiều thời gian mà chưa chắc tìm ra cách augmentation tốt nhất.
Tìm hiểu về cách Data Agumentation trong keras
Trong keras có hỗ trợ class ImageDataGenerator cho phép tạo thêm dữ liệu. Hôm nay mình xin trình bày về nó.
Class ImageDataGenerator có 3 phương thức flow(), flow_from_directory() và flow_from_dataframe() để đọc các ảnh từ một mảng lớn numpy và thư mục chứa ảnh ( from a big numpy array and folder containing images)
Chúng ta sẽ thảo luận về flow_from_directory() trong bài này này.
Giả sử bạn đã tải được một tập dataset và bạn có 2 thư mục train và test, trong mỗi thư mục thì bạn có các thư mục con , mỗi thư mục con chứa các ảnh thuộc về thư mục con đó. (Tí xem hình phía dưới là bạn hiểu mình đang nói gì )
Tạo một tập validation set, thường bạn phải tạo thủ công một validation data bởi sampling images từ train folder (bạn có thể lấy ngẫu nhiên, hoặc lấy theo thứ tự mà bạn muoons) và di chuyển chúng vào một thư một tên là "valid". Nếu bạn đã có tập validation, bạn có thể sử dụng chúng thay vì tạo thủ công.
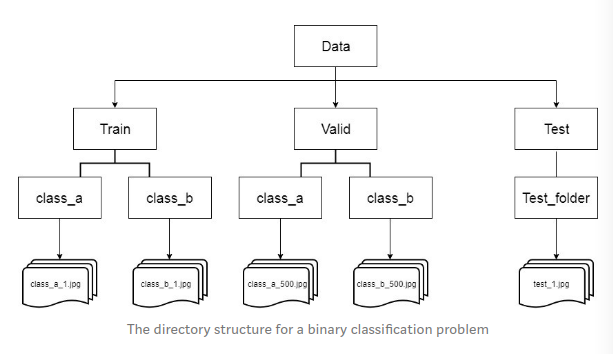
Như bạn có thể thấy ở hình ảnh trên, Test folder chỉ chứa một một folder test_folder và bên trong có tất cả các hình ảnh để test.
Tên của folder cho các lớp là rất quan trọng, đặt tên (hoặc đổi teen) chúng với tên nhãn tương ứng để có thể dễ dàng cho bạn sau này. Sau khi thiết lập các hình ảnh vào cấu trúc như trên, bạn có thể sẵn sàng để code!
Với class ImageDataGenerator
Có các thuộc tính sau :
- zoom_range: thực hiện zoom ngẫu nhiên trong một phạm vi nào đó
- width_shift_range: Dịch theo chiều ngang ngẫu nhiên trong một phạm vi nào đó
- height_shift_range: Dịch ảnh theo chiều dọc trong một phạm vi nào đó
- brightness_range: Tăng cường độ sáng của ảnh trong một phạm vi nào đó.
- vertical_flip: Lật ảnh ngẫu nhiên theo chiều dọc
- rotation_range: Xoay ảnh góc tối đa là 45 độ
- shear_range: Làm méo ảnh
Với flow_from_directory
Dưới đây là các thuộc tính được sử dụng phổ biến với flow_from_directory():
train_generator = train_datagen.flow_from_directory(
directory=r"./train/",
target_size=(224, 224),
color_mode="rgb",
batch_size=32,
class_mode="categorical",
shuffle=True,
seed=42
)
- directory: phải đặt đường dẫn có các classes của folder.
- target_size: là size của các ảnh input đầu vào, mỗi ảnh sẽ được resized theo kích thước này.
- color_mode: Nếu hình ảnh là màu đen và màu trắng hoặci là grayscale thì set "grayscale" hoặc nếu nó gồm 3 channels thì set "rgb"
- batch_size : Số lượng ảnh được yielded từ generator cho mỗi lô batch.
- class_mode : set "binary" nếu bạn có 2 classes để dự đoán, nếu không thì bạn set "categorical". trong trường hợp nếu bạn đang lập trình một hệ thống tự động Autoencoder, thì cả input và output đều là ảnh, trong trường hợp này thì bạn set là input
- shuffle: set True nếu bạn muốn đổi thứ tự hình ảnh, ngược lại set False.
- seed : Random seed để áp dụng tăng hình ảnh ngẫu nhiên và xáo trộn thứ tự của hình ảnh
valid_generator = valid_datagen.flow_from_directory(
directory=r"./valid/",
target_size=(224, 224),
color_mode="rgb",
batch_size=32,
class_mode="categorical",
shuffle=True,
seed=42
)
- Giống train generator ngoại trừ những thay đổi hiển nhiên như đường dẫn thư mục.
test_generator = test_datagen.flow_from_directory(
directory=r"./test/",
target_size=(224, 224),
color_mode="rgb",
batch_size=1,
class_mode=None,
shuffle=False,
seed=42
)
- directory: đường dẫn chứa một folder, trong đó có các ảnh để test. Ví dụ, trong trường hợp cấu trúc thư mục ở trên, thì các ảnh sẽ được tìm thấy ở /test/test_images/ Các tham số khác cũng giống như ở trên mình đã trình bày.
Cảm ơn các bạn đã đọc bài trình bày. Hi vọng các bạn sẽ có thêm kiến thức về data augumentation
All rights reserved
