Pretrain Model Vision Transformer in Pytorch
Tiếp bước series trước, hôm nay mình lên series về pretrain cho model Vision Transformer- ViT. Các bạn có thể đọc bài biết From Vision Transformer Paper to Code của mình tại đây để hiểu sâu hơn về ViT. Đọc paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale của các tác giả Google Research
1. Một số bước chuẩn bị
- Chúng ta cần chuẩn bị một số đoạn code để Tracking. Tại đây mình sử dụng WanDB để tracking đoạn code này. Truy cập WanDB tại đây
- Xuyên suốt bài này mình sẽ dùng Pytorch. Cài đặt Pytorch, có thể truy cập vào đây để xem hướng dẫn cài đặt
- Sau khi cài đặt Pytorch. Chúng ta cần setup thiết bị sử dụng train model:
device="cuda" if torch.cuda.is_available() else "cpu". Khi bạn có GPU thì nó sẽ trực tiếp sử dụng GPU của bạn và ngược lại. - Login Wandb: Bạn có thể dùng đoạn code sau để login:
import wandb
wandb.login(key="#INPUT YOUR API KEY")
2. Lấy thông số một số Weights của ViT.
- Tại phần này mình sẽ dùng ViT-B 16 để demo chạy nhanh hơn, các bạn có thể dùng một số Weights khác tại đây. Số lượng đầu của ViT-B 16 Base là 768. Tham số của ViT-B 16 nhỏ hơn so với các model khác.
- Mình sẽ dùng trực tiếp pretrain weights của Pytorch. Bạn có thể follow đoạn code sau:
# 1. Get pretrained weights for ViT-Base
pretrained_vit_weights = torchvision.models.ViT_B_16_Weights.DEFAULT # requires torchvision >= 0.13, "DEFAULT" means best available
# 2. Setup a ViT model instance with pretrained weights
pretrained_vit = torchvision.models.vit_b_16(weights=pretrained_vit_weights).to(device)
# 3. Freeze the base parameters
for parameter in pretrained_vit.parameters():
parameter.requires_grad = False
pretrained_vit_transforms = pretrained_vit_weights.transforms()
print(pretrained_vit_transforms)
- Tham số
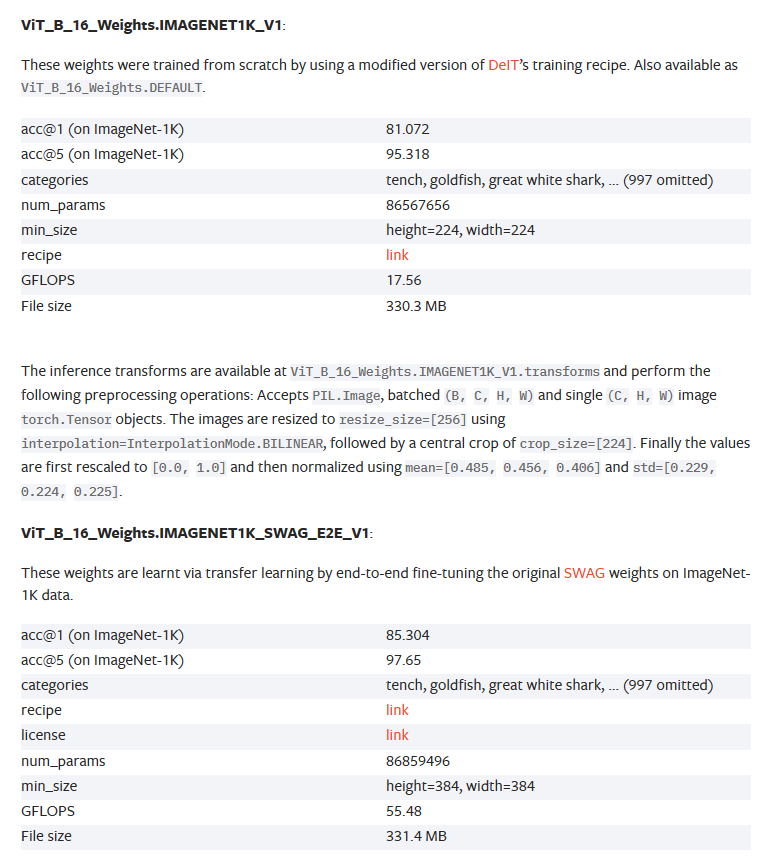
DEFAULTlà tham số trả về mô hình tốt nhất. Tuỳ vào bộ dữ liệu hay ý muốn của bạn. Bạn có thể thay tham sốDEFAULTthay tham số khác nhưIMAGENET1K_V1được train trên bộImagenet-1khoặcIMAGENET1K_SWAG_E2E_V1được train trên bộ SWAG. Xem chi tiết tại bảng này:![]() trong phần link mình gửi phía trên.
trong phần link mình gửi phía trên. - Do chúng ta pretrain nên cần đóng băng một số layer của model. Bạn có thể nhìn thấy
parameter.requires_grad = Falsetrong đoạn code. - Ngoài ra, chúng ta cũng cần transform của model này để biết yêu cầu đầu vào của mô hình.
- Một số model khác lớn hơn tương đương cần nhiều thời gian hơn để train.
3. Chuẩn bị dữ liệu
- Trước tiên chúng ta cần chuẩn bị một số dữ liệu đầu vào. Tại bài này, mình cũng sẽ sử dụng bộ dữ liệu khác bài trước. Gồm hơn 1000 ảnh não người và được chia thành 2 lớp tải xuống từ Roboflow. Bộ này chủ yếu mô tả về ung thư não ở người, các khối u trong não. Bộ dữ liệu có thể tải xuống tại các bạn có thể thay API của mình vào để download:
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="FILL Your API Key")
project = rf.workspace("afylmardopila-cenfk").project("brain-tumor-bapp1")
version = project.version(1)
dataset = version.download("folder")
- Sau khi có dữ liệu chúng ta cần lấy đường dẫn đến thư mục
train,val,test, mình sẽ gọi tên thư mục này làtrain_dir,test_dir, val_dir. Bạn có thể follow đoạn code phía dưới:
from pathlib import Path
# Tạo đối tượng đường dẫn cho thư mục gốc
image_path = Path("/kaggle/working/Brain-tumor-1")
# Kết hợp các đường dẫn để tạo đường dẫn hoàn chỉnh cho tập huấn luyện và tập kiểm tra
train_dir = image_path.joinpath("train")
test_dir = image_path.joinpath("test")
val_dir = image_path.joinpath("valid")
- Sau khi có train_dir,test_dir,val_dir. Chúng ta cần chuyển chúng sang định dạng phù hợp với framework Pytorch, đó chính là DataLoaders.
import os
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
NUM_WORKERS=os.cpu_count()
def create_dataloader(train_dir:str,test_dir:str,transform:transforms.Compose,batch_size:int,num_workers:int=NUM_WORKERS):
train_data=datasets.ImageFolder(train_dir,transform=transform)
test_data=datasets.ImageFolder(test_dir,transform)
train_dataloader=DataLoader(dataset=train_data,num_workers=num_workers,batch_size=batch_size,shuffle=True,pin_memory=True)
test_dataloader=DataLoader(dataset=test_data,batch_size=batch_size,pin_memory=True,num_workers=num_workers,shuffle=False)
class_name=train_data.classes
return train_dataloader,test_dataloader,class_name
Đoạn code này đầu vào là đường dẫn đến các tập Train,Test và Val và trả ra train_dataloaders và test_dataloaders phù hợp với yêu cầu đầu vào của Pytorch. Để chạy đoạn code này, bạn có thể nhìn đoạn code phía dưới:
train_dataloaders,test_dataloader,class_name=create_dataloader(train_dir=train_dir,test_dir=val_dir,transform=pretrained_vit_transforms,batch_size=32,num_workers=1)
train_dir: Đường dẫn tới tập Traintest_dir: Đường dẫn tới tập TestBatch_size: số ảnh trong 1 batch.Transforms: Là phép biến đổi hình ảnh, có thể là xoay, lật ảnh,...Chính là tham sốpretrained_vit_transformsphía trên.
4. Train Model
4.1. Setup Loss Function và Optimizer
Trong một model không thể thiếu được Loss Function và Optimizer đúng không. Thì ViT cũng tương tự như vậy.
optimizer = torch.optim.Adam(params=pretrained_vit.parameters(),
lr=1e-3)
loss_fn = torch.nn.CrossEntropyLoss()
Trong model này, mình dùng Adam để làm Optimizers và CrossEntropy để làm loss function.
4.2. Chỉnh sửa output Layer
Do mô hình của tác giả được huấn luyện trên một số bộ dữ liêu như IMAGENET1K có 1000 lớp, một số bộ dữ liệu khác số lớp khác nhau mà số lớp của mô hình chúng ta khác họ, chúng ta cần phải custom layer output cho phù hợp. Tại đây mình dùng đoạn code này để tuỳ chỉnh:
torch.manual_seed(42)
pretrained_vit.heads = nn.Linear(in_features=768, out_features=len(class_name)).to(device)
- Đầu vào
in_features=768là số đầu của mô hình, mô hình ViT B-16 dùng 768 đầu nên đầu vào là 768. - Đầu ra
out_featureslà số lớp của mô hình chúng ta. devicechính là thiết bị chúng ta sử dụng có thể làcuda,cpuhoặc applemps
4.3. Tạo hàm Train
Chúng ta có thể thiết lập hàm train model với 3 thành phần chính sau:
train_step: Thực hiện bước huấn luyện mô hình trên một batch dữ liệu từ train dataloader. Hàm này nhận vào các tham số là mô hình, dataloader, hàm mất mát và bộ tối ưu hóa. Hàm này trả về giá trị độ chính xác và mất mát trên batch đó.test_step: Tương tự nhưng trên testdataloaderstrain: Kích hoạt 2 hàm phía trên
Bạn cũng thể tinh chỉnh tên của dự án trên Wandb bằng cách thay đổi run=wandb.init(project="Vision Transformer Plane Classification Model") thành tên mà bạn muốn.
Chúng ta có thể code như sau:
import torch
import torch.nn as nn
from tqdm.auto import tqdm
from typing import List,Tuple,Dict
def train_step(model:torch.nn.Module,dataloader:torch.utils.data.DataLoader,loss_fn:torch.nn.Module,optimizers:torch.optim.Optimizer):
wandb.watch(model, log_freq=100)
model.train()
train_acc,train_loss=0,0
for batch,(X,y) in enumerate(dataloader):
X,y=X.to(devices),y.to(devices)
y_pred=model(X)
loss=loss_fn(y_pred,y)
train_loss+=loss.item()
optimizers.zero_grad()
loss.backward()
optimizers.step()
y_pred_class=torch.argmax(torch.softmax(y_pred,dim=1),dim=1)
train_acc +=(y_pred_class==y).sum().item()/len(y_pred)
train_acc/=len(dataloader)
train_loss/=len(dataloader)
return train_acc,train_loss
def test_step(model:torch.nn.Module,dataloader:torch.utils.data.DataLoader,loss_fn:torch.nn.Module):
model.eval()
test_loss_values,test_acc_values=0,0
with torch.inference_mode():
for batch,(X,y) in enumerate(dataloader):
X,y=X.to(devices),y.to(devices)
y_test_pred_logits=model(X)
test_loss=loss_fn(y_test_pred_logits,y)
test_loss_values+=test_loss.item()
y_pred_class=torch.argmax(y_test_pred_logits,dim=1)
test_acc_values += ((y_pred_class==y).sum().item()/len(y_test_pred_logits))
test_loss_values/=len(dataloader)
test_acc_values/=len(dataloader)
return test_loss_values,test_acc_values
run=wandb.init(project="Vision Transformer Plane Classification Model")
def train(model: torch.nn.Module, train_dataloader: torch.utils.data.DataLoader, test_dataloader: torch.utils.data.DataLoader, optimizer: torch.optim.Optimizer, loss_fn: torch.nn.Module = nn.CrossEntropyLoss(), epochs: int = 100, early_stopping=None):
result = {
"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": []
}
for epoch in tqdm(range(epochs)):
train_acc, train_loss = train_step(model=model, dataloader=train_dataloader, loss_fn=loss_fn, optimizers=optimizer)
test_loss, test_acc = test_step(model=model, dataloader=test_dataloader, loss_fn=loss_fn)
print(
f"Epoch: {epoch + 1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f}"
)
# Update results dictionary
result["train_loss"].append(train_loss)
result["train_acc"].append(train_acc)
result["test_loss"].append(test_loss)
result["test_acc"].append(test_acc)
wandb.log({"Train Loss": train_loss,
"Test Loss": test_loss,
"Train Accuracy": train_acc,
"Test Accuracy": test_acc,"Epoch":epoch})
# Check for early stopping
if early_stopping is not None:
if early_stopping.step(test_loss): # You can use any monitored metric here
print(f"Early stopping triggered at epoch {epoch + 1}")
break
return result
4.4. Tạo Early Stopping
Phần này chúng ta sẽ sử dụng hàm CrossEntropyLoss để tính toán Loss Function. Code:
loss_fn = torch.nn.CrossEntropyLoss()
4.5. Thiết lập EarlyStopping
Mục đích để tracking lại hiệu suất của mô hình. Rồi có quyết dịnh dừng sớm để tránh lãng phí tài nguyên hay không. Code như sau:
import numpy as np
class EarlyStopping(object):
def __init__(self, mode='min', min_delta=0, patience=10, percentage=False):
self.mode = mode
self.min_delta = min_delta
self.patience = patience
self.best = None
self.num_bad_epochs = 0
self.is_better = None
self._init_is_better(mode, min_delta, percentage)
if patience == 0:
self.is_better = lambda a, b: True
self.step = lambda a: False
def step(self, metrics):
if self.best is None:
self.best = metrics
return False
if np.isnan(metrics):
return True
if self.is_better(metrics, self.best):
self.num_bad_epochs = 0
self.best = metrics
print('improvement!')
else:
self.num_bad_epochs += 1
print(f'no improvement, bad_epochs counter: {self.num_bad_epochs}')
if self.num_bad_epochs >= self.patience:
return True
return False
def _init_is_better(self, mode, min_delta, percentage):
if mode not in {'min', 'max'}:
raise ValueError('mode ' + mode + ' is unknown!')
if not percentage:
if mode == 'min':
self.is_better = lambda a, best: a < best - min_delta
if mode == 'max':
self.is_better = lambda a, best: a > best + min_delta
else:
if mode == 'min':
self.is_better = lambda a, best: a < best - (
best * min_delta / 100)
if mode == 'max':
self.is_better = lambda a, best: a > best + (
best * min_delta / 100)
4.6. Train model
Các bạn có thể sử dụng hàm sau để train model:
early_stopping = EarlyStopping(mode='min', patience=10)
devices="cuda" if torch.cuda.is_available() else "cpu"
model_result=train(model=pretrained_vit,train_dataloader=train_dataloaders,test_dataloader=test_dataloader,optimizer=optimizer,loss_fn=loss_fn,epochs=100,early_stopping=early_stopping)
run.finish()
4.7. Save mode
Sau khi train xong model, các bạn có thể sử dụng đoạn code sau để lưu model:
import torch
from pathlib import Path
def save_model(model:torch.nn.Module,target_dir:str,model_name:str):
target_dir_path = Path(target_dir)
target_dir_path.mkdir(parents=True,
exist_ok=True)
# Create model save path
assert model_name.endswith(".pth") or model_name.endswith(".pt"), "model_name should end with '.pt' or '.pth'"
model_save_path = target_dir_path / model_name
# Save the model state_dict()
print(f"[INFO] Saving model to: {model_save_path}")
torch.save(obj=model.state_dict(),
f=model_save_path)
Chạy đoạn code trên
save_model(model=pretrained_vit,
target_dir="models",
model_name="ViT_for_Classification.pt")
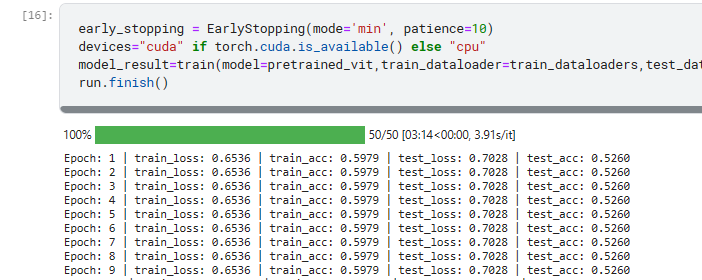
5. Kết quả
Do mình train demo nên kết quả có thể hơi tệ, bản có thể thử một số bộ data khác tuỳ theo ý của mình. Ngoài ra các bạn cũng có thể sử dụng ViT Huge14 hoặc ViT Large để đạt được kết quả tốt hơn.
6. References
- Pytorch Tutorial: https://www.learnpytorch.io/08_pytorch_paper_replicating/#9-setting-up-training-code-for-our-vit-model
- Paper ViT: https://arxiv.org/abs/2010.11929
- Paper ResidualNet: https://arxiv.org/abs/1512.03385v1
- Paper Transformer: https://arxiv.org/abs/1706.03762
- ViT Pretrain Pytorch Documentation: https://pytorch.org/vision/main/models/vision_transformer.html
- Full Source code: https://www.kaggle.com/tnguynfew/vit-b-16-pretrain-for-brain-tumor
Cảm ơn đã đọc bài này của mình. Nếu bạn các bạn thấy hữu ích có thể cho mình xin 1 upvote.
All rights reserved
