Làm một con Crawler đơn giản để cào ebooks với Scrapy và python
Bài đăng này đã không được cập nhật trong 4 năm
Vì sao có tool này
Chả là một hôm sếp giao cho mình task tìm hiểu về scrapy để cào dữ liệu, tình cờ thay vài hôm sau mình cũng vừa mua được một con máy đọc sách nên cũng có nhu cầu tìm kiếm ebooks free. Hôm đó mình tìm được trang sachvui.com có khá nhiều ebooks free và mình phát hiện ra là web này có thể làm tools để lấy hết ebooks về một cách dễ dàng, hôm nay mình xin chia sẽ các bạn tool mà mình viết.
Bắt tay vào làm việc nào
Tìm hiểu cấu trúc trang sachvui.com trước
Trước khi bắt tay vào code chúng ta cùng tìm hiểu cấu trúc trang sachvui và một số kiến thức cơ bản về xpath trước nhé.
- Các bạn vào https://sachvui.com/the-loai/tat-ca.html để trang list tất cả các ebooks ra nhé
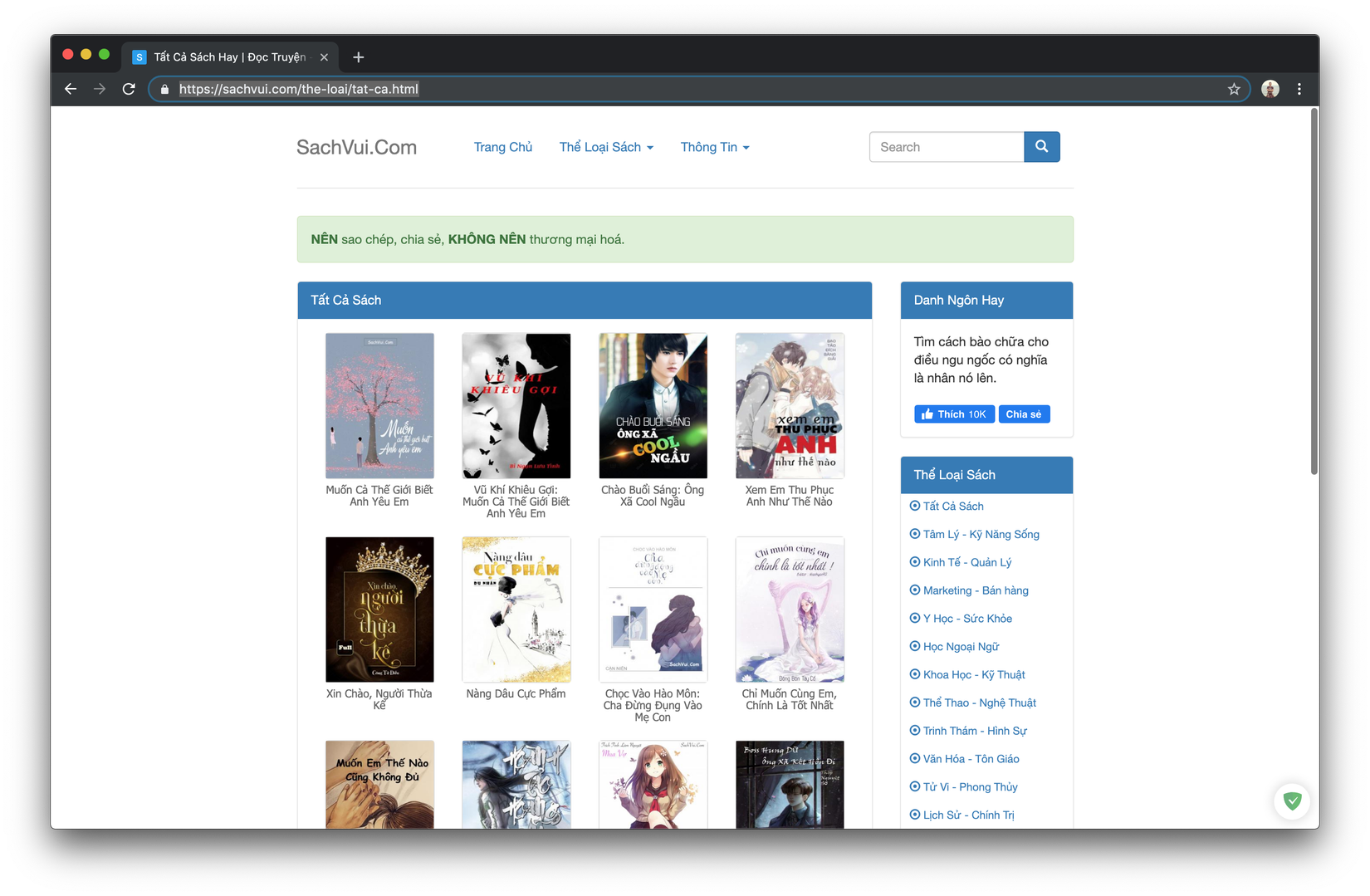
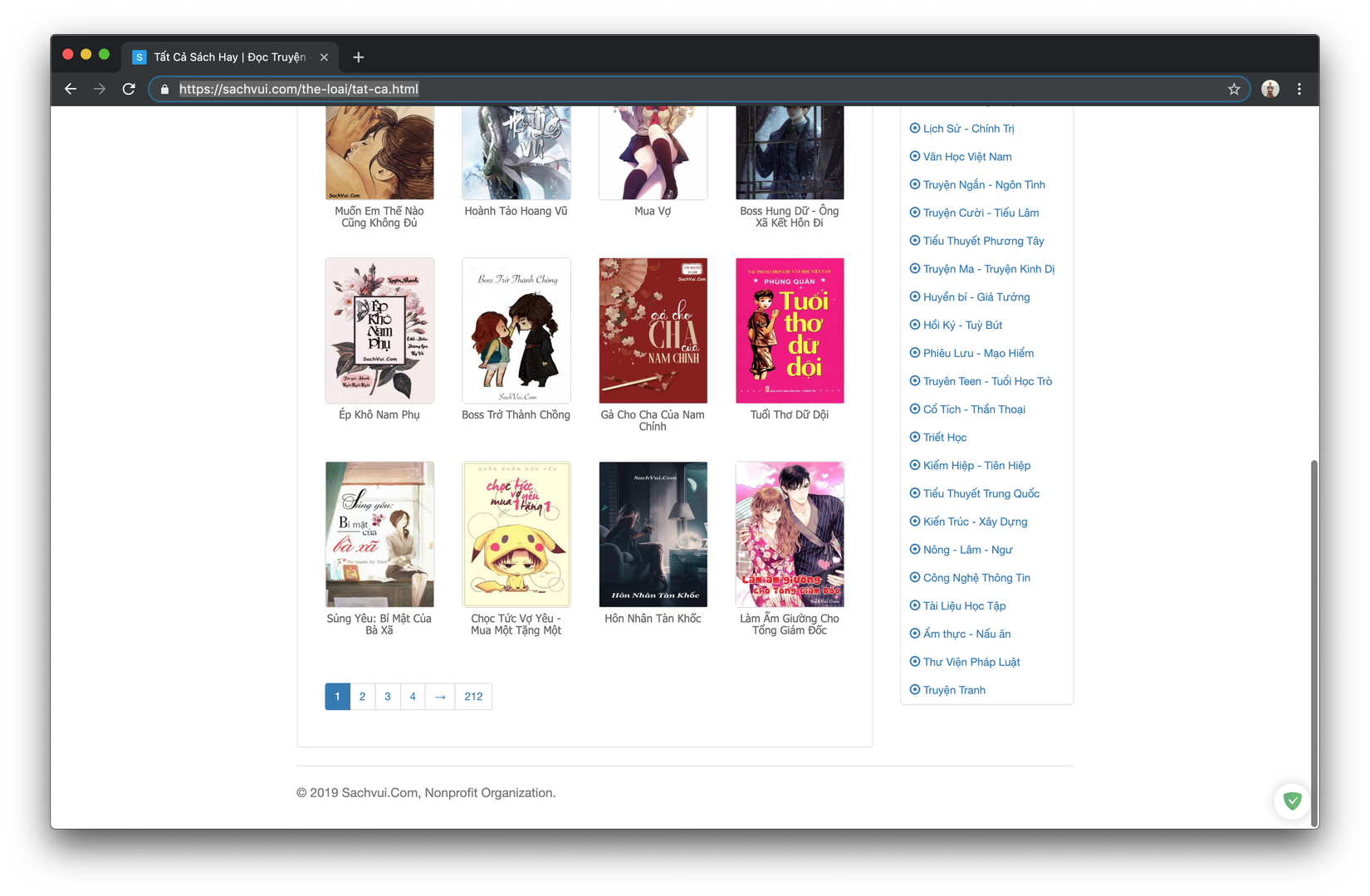
- Bấm vào một ebooks bất kì bạn sẽ vào được trang có cấu trúc tương tự như sau:
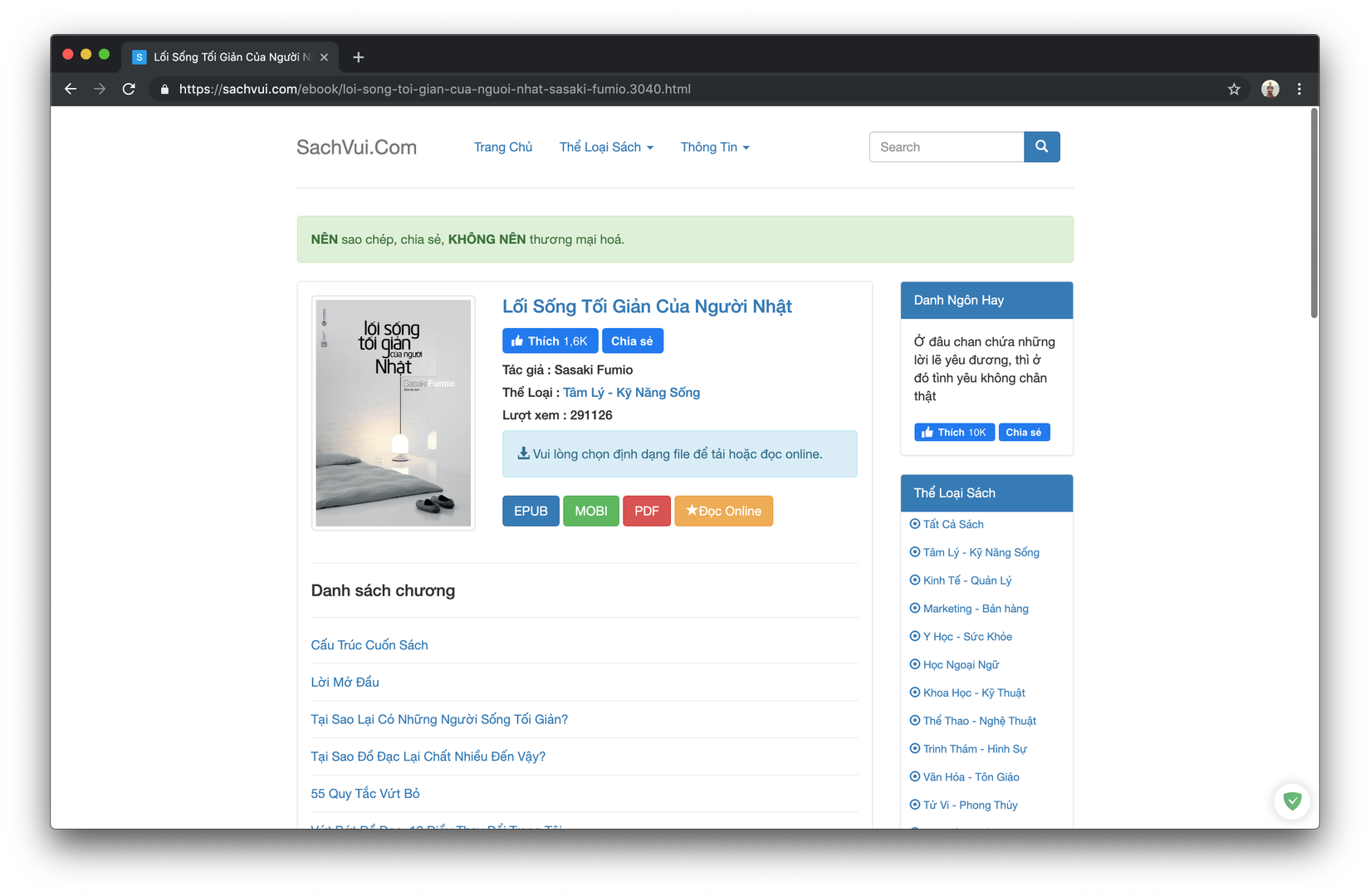
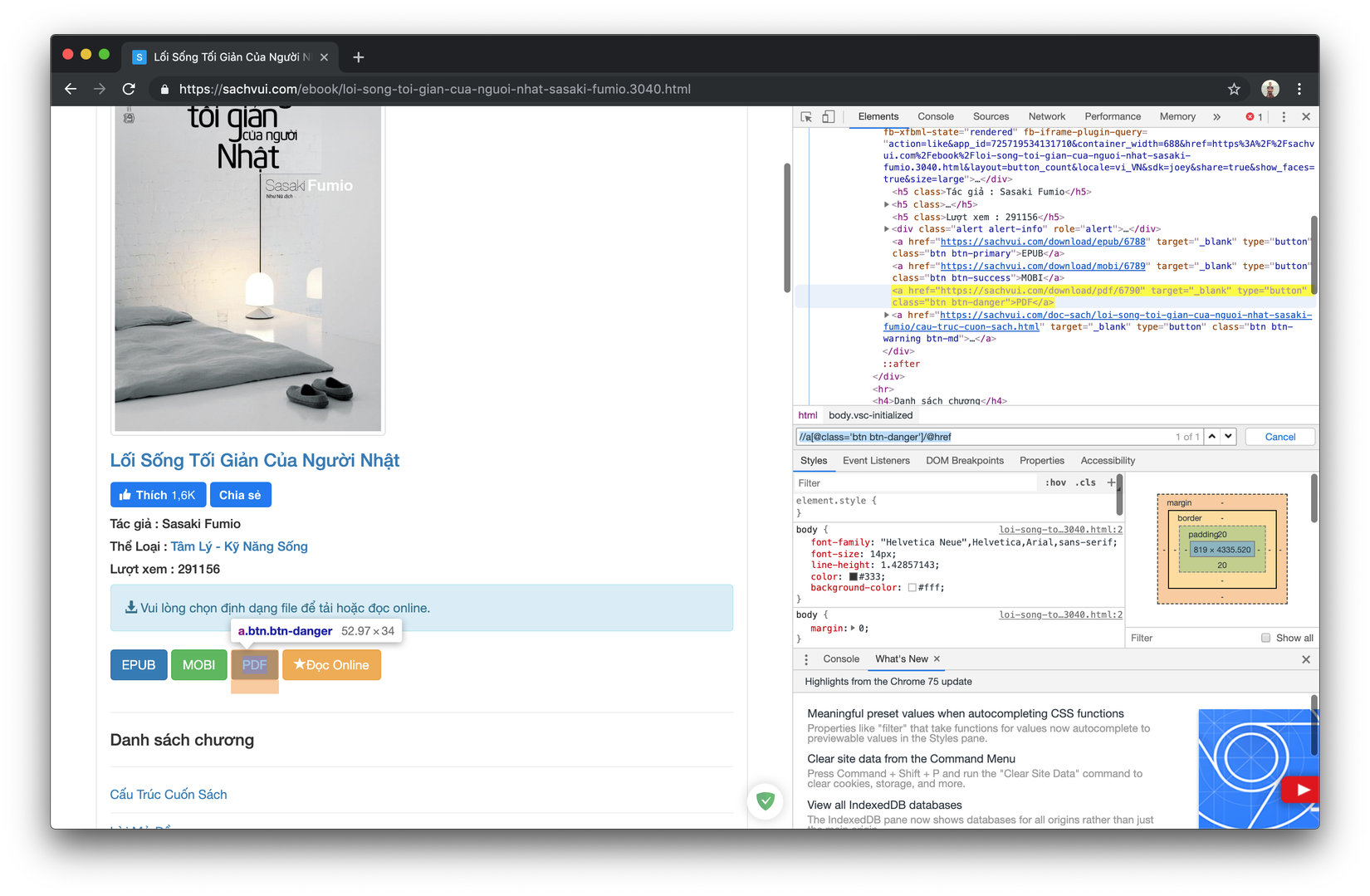
Các bạn có thể thấy các mục EPUB, MOBI, PDF là các nút download ebook với các định dạng khác nhau, khi bạn bấm vào ebook sẽ bắt đầu được download. Lưu ý là không phải ebooks nào cũng có file để download nha
- Okey giờ các bạn có thể hiểu sơ cấu trúc của nó đơn giản là hiện tất cả các ebooks lên theo dạng trang (có 212 trang mỗi trang tầm 20 cuốn)
- Trở về trang tất cả sách mở Inspect lên vào tab Elements
- Bấm Command + F (Control + F với windows) để hiện khung search lên
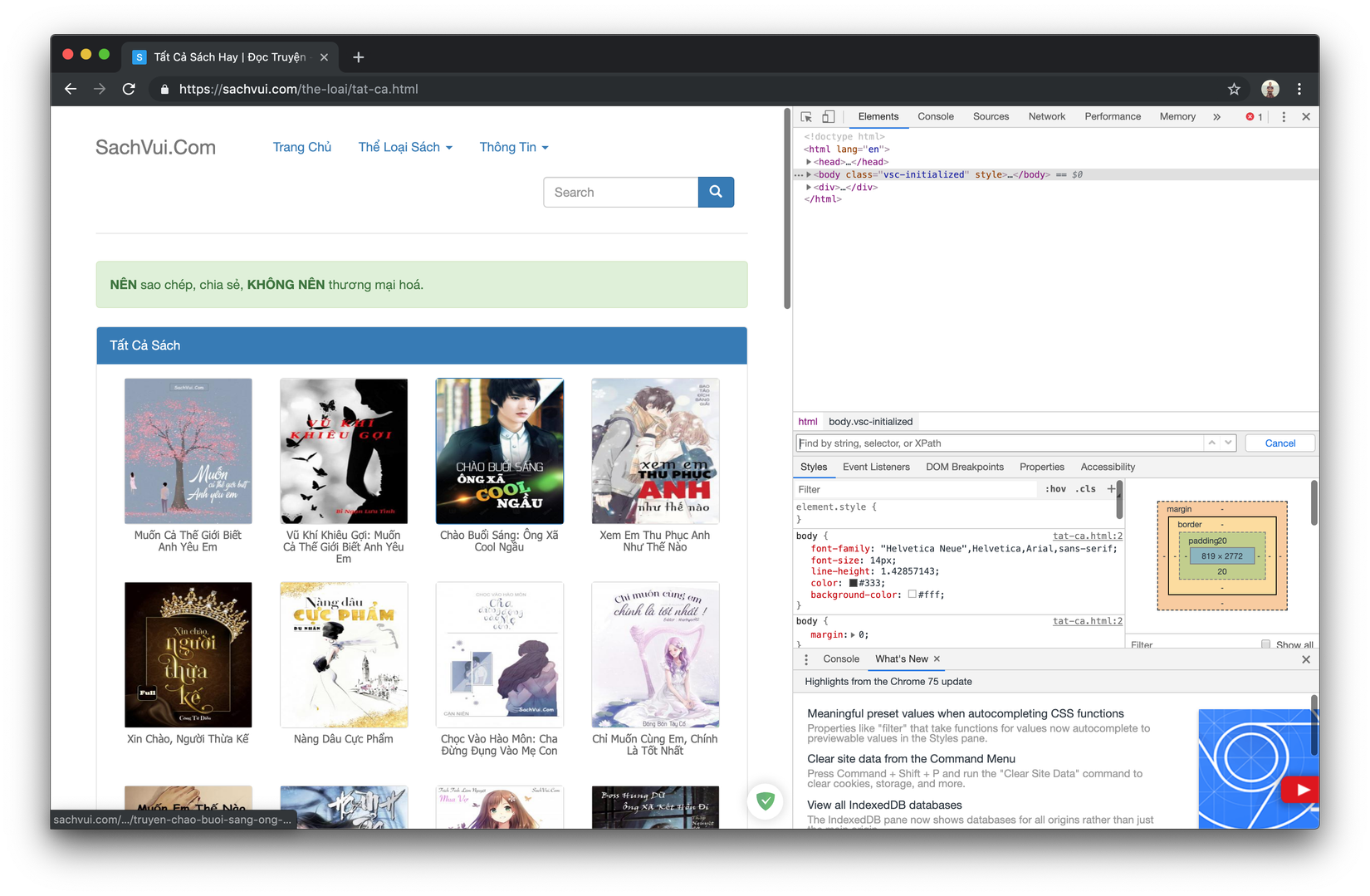
- Bắt đầu gõ Xpath để để lấy urls các trang ebooks (Các bạn tự tìm hiểu thêm về xpath nhé) mình lấy ví dụ đơn giản để do các bạn dể các bạn dùng trong trường hợp này nha:
Bạn gõ vào
//div[contains(@class,"ebook")]sẽ nhận được như hình bên dưới.Hiểu đơn giản là các bạn sẽ lấy được các thẻ div có chứa class tên là ebooks, ở đây có 20 cái thử đếm bằng mắt các bạn cũng có thể thấy có 20 ebooks hiện trên trang, vậy là xpath của ta có vẻ đã đúng
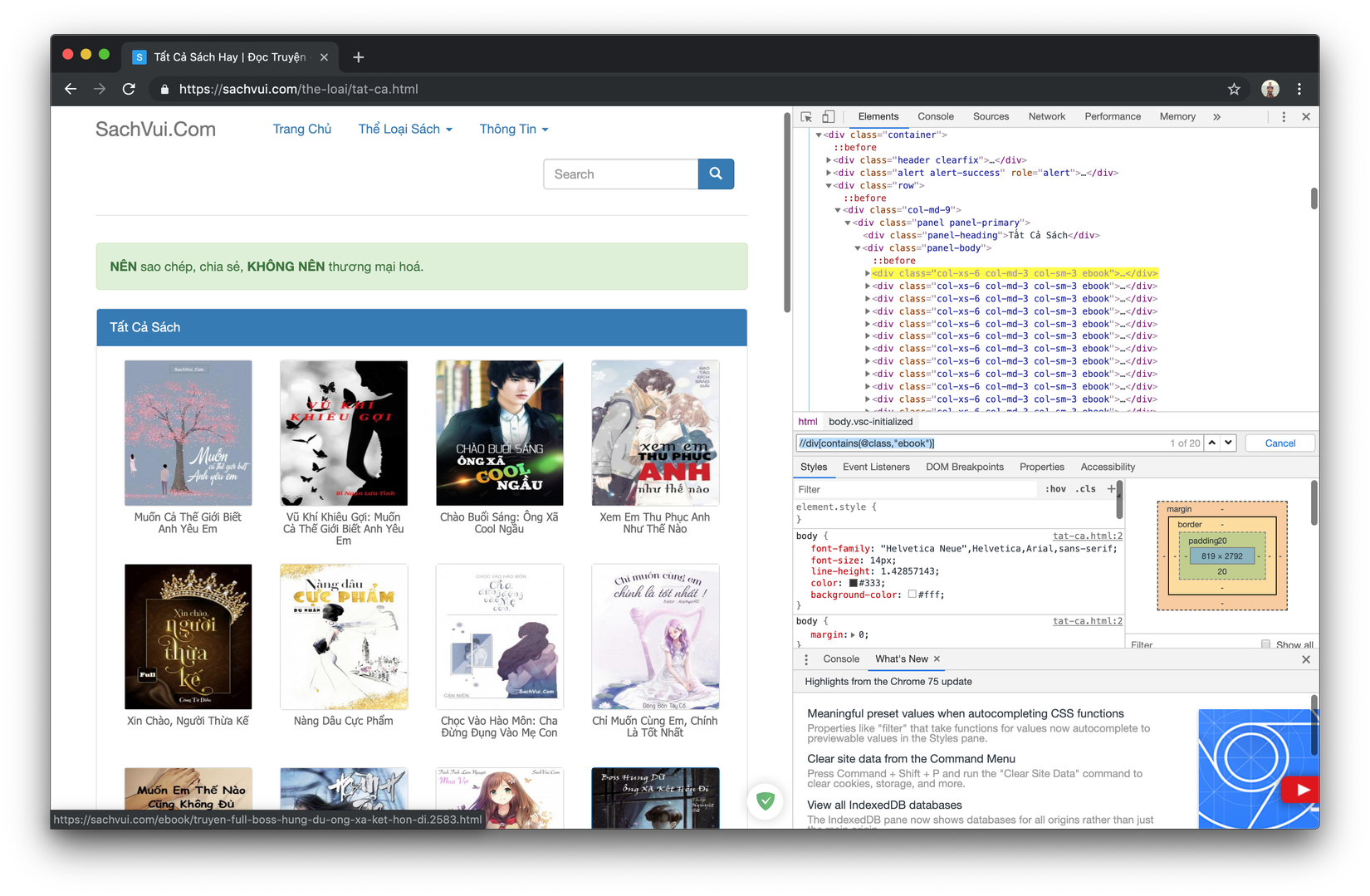
Bung thẻ div ra bạn có thể thấy thẻ a đầu tiên chứa url của trang chứa ebook mà bạn muống vào, công việc có vẻ khá đơn giản, ta bắt đầu update lại xpath để lấy thẻ a đó Bạn update tiếp xpath thành
//div[contains(@class,"ebook")]/aNói thêm về xpath nếu bạn muốn lấy trực tiếp atr href của nó thì bạn có thể update thành như sau//div[contains(@class,"ebook")]/a/@hrefta sẽ là nó sau trong code.
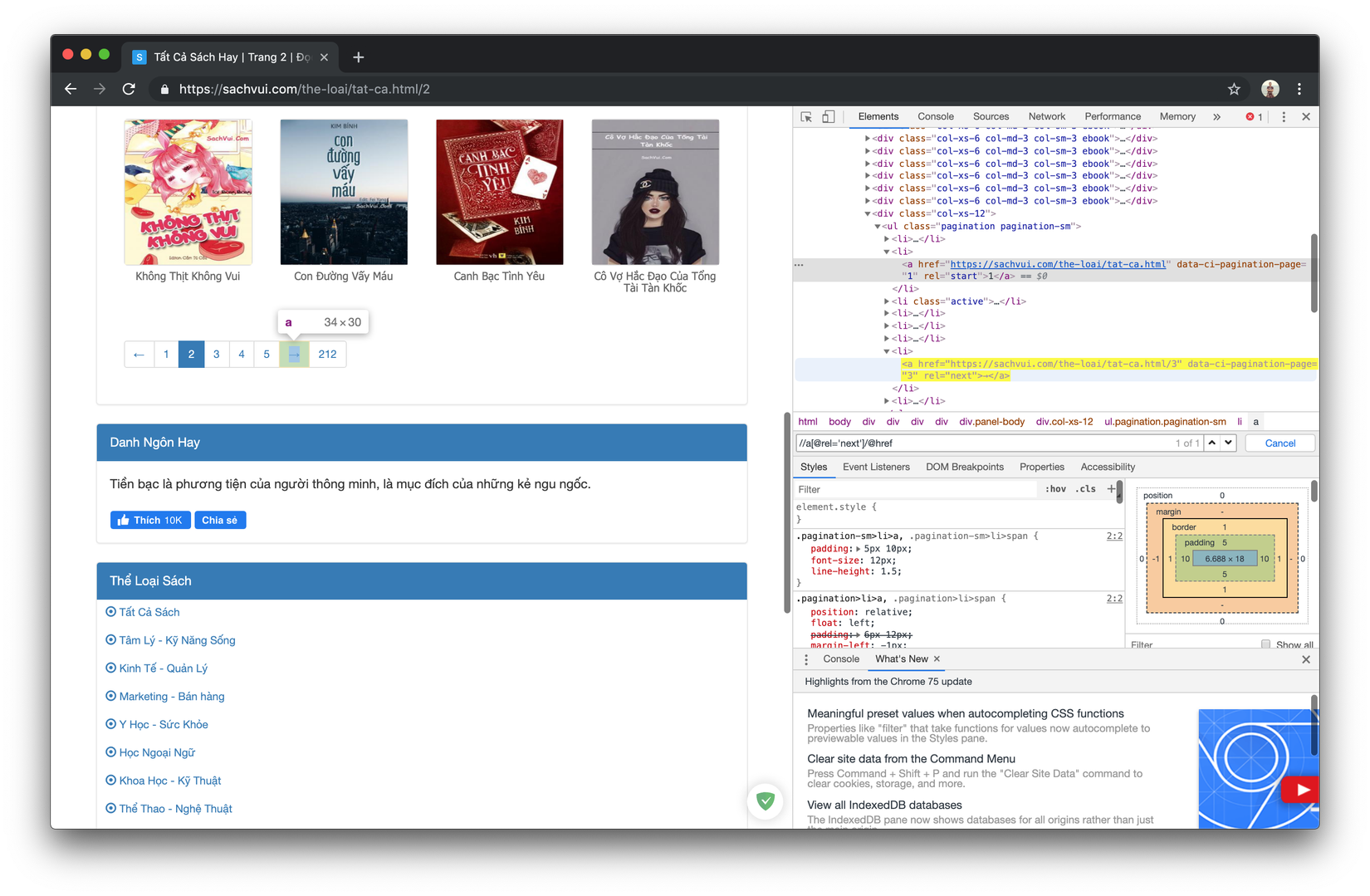
- Sẵn đây ta tìm luôn nút next để phần sau ta dễ code hơn
Ta nhập đoạn xpath sau:
//a[@rel='next']/@hrefTa sẽ lấy được url của nút next khi bấm vào thì sẽ qua trang tiếp theo sang trang tiếp theo cứ bấm tiếp như vậy thì ta sẽ có thể thấy hết ebooks luôn.
- Quay trở lại trang ebook chúng ta cũng dùng xpath để lấy url của các nút download nhé
Mình viết sẵn các đoạn xpath cho các bạn dễ dàng dùng như sau Chúng ta sẽ không chú ý tới mục đọc online nhé
EPUB:
//a[@class='btn btn-primary']/@hrefMOBI:
//a[@class='btn btn-success']/@hrefPDF:
//a[@class='btn btn-danger']/@href
Cấu trúc trang web ok rồi giờ thì bắt tay vào code thôi
cài đặt môi trường
- Đầu tiên cần phải cài đặt python cho máy, cách cài các bạn tìm hiểu google giúp mình nhé cũng đơn giản thôi.
- Cài đặt scrapy.
pip install scrapy - Khởi tạo project.
- Đầu tiên cần mở terminal (cmd trong windows) lên xong di chuyển đến thư mục muốn chứa project nhé.
- Bắt đầu gõ vào terminal
scrapy startproject crawler
Một folder tên crawler sẽ được tạo ra, bạn dùng IDE bất kì để mở lên mình thì dùng VSCode. Bạn sẽ nhận được một project có cấu trúc như sau:
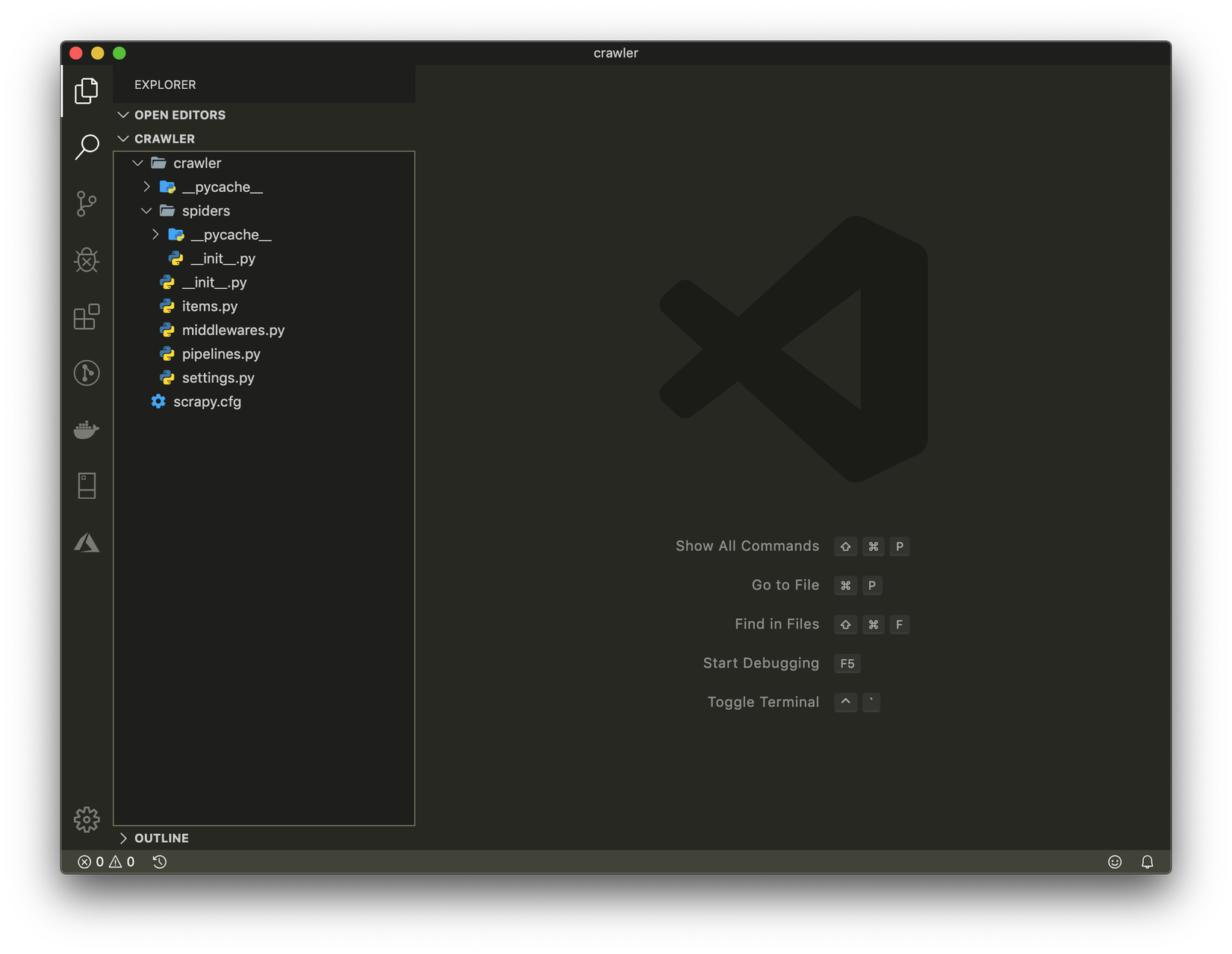
- Tạo file tên
sachvui.pytrong thư mục spiders và copy đoạn code này vào
import scrapy
class SachVuiSpider(scrapy.Spider):
name = 'sachvui'
def start_requests(self):
urls = [
'https://sachvui.com/the-loai/tat-ca.html'
]
for url in urls:
yield scrapy.Request(url = url, callback=self.parsePage)
def parsePage(self, response):
for page in response.xpath("//div[contains(@class,'ebook')]/a"):
page_url = page.xpath('./@href').extract_first()
yield {
"url": page_url
}
Hàm start_requests sẽ được chạy đầu tiên
Đoạn
yield scrapy.Request(url = url, callback=self.parsePage)hiểu một cách đơn giản thì khi request được tạo ra thì trang html được get về sẽ được xử lí với hàm parsePageỞ đây ta có mảng urls là danh sách các url bắt đầu chạy, url trên là của tất cả sách trên sachvui.com, bạn có thể vào từng thể loại như kinh tế, tài chính, truyện hay gì đó để lấy url khác nếu bạn chỉ muốn lấy sách của một thể loại thôi.
- Trở lại terminal vã gõ
scrapy crawl sachvui -o sachvui.jsonđể chạy crawler thử - Bạn sẽ thấy có một file sachvui.json được tạo ra và lưu về url của các trang ebooks của page đầu tiên vào đó
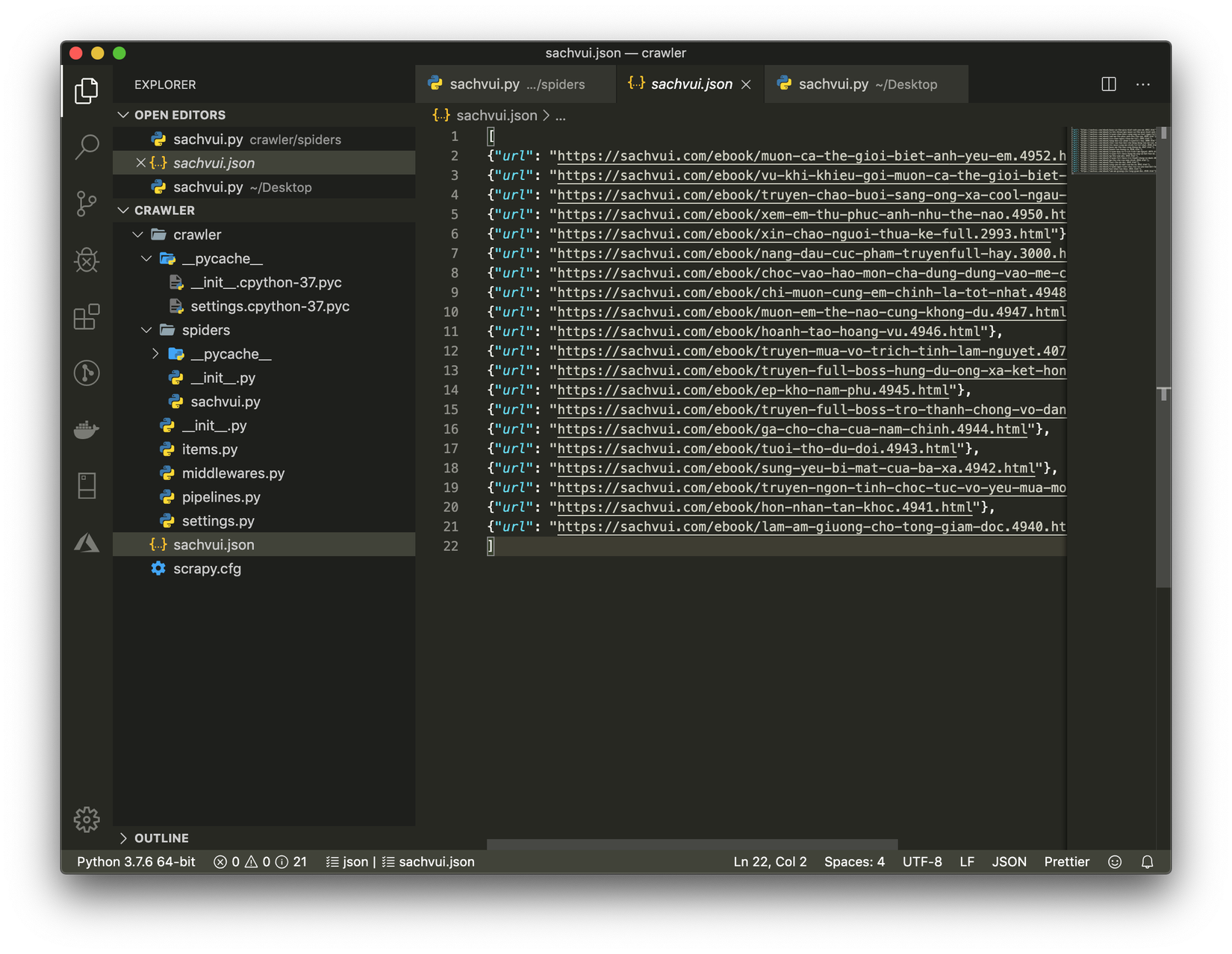
- Bước tiếp theo ta cần giả lập việc bấm nút next để qua trang, các bạn update lại code như sau
import scrapy
class SachVuiSpider(scrapy.Spider):
name = 'sachvui'
def start_requests(self):
urls = [
'https://sachvui.com/the-loai/tat-ca.html'
]
for url in urls:
yield scrapy.Request(url = url, callback=self.parsePage)
def parsePage(self, response):
for page in response.xpath("//div[contains(@class,'ebook')]/a"):
page_url = page.xpath('./@href').extract_first()
yield {
"url": page_url
}
nextButtonUrl = response.xpath("//a[@rel='next']/@href").extract_first()
if nextButtonUrl is not None:
yield scrapy.Request(url = nextButtonUrl, callback=self.parsePage)
Hiểu nôm na là hàm parsePage sẽ lấy dữ liệu url của tất cả các ebooks hiện lên trên page, sau đó ta lấy url của nút next lưu vào biến nextButtonUrl. rồi ta tiếp tục tạo request mới với url trên thì hàm parsePage sẽ được gọi tiếp ở trang tiếp theo Chạy lại lệnh
scrapy crawl sachvui -o sachvui.jsonở terminal và quay lại file sachvui.json ta sẽ thấy được tất cả ebooks page url đâu đó hơn 4000 ebooks
- Giờ thì ta không cần lưu url ebooks vào file sachvui.json nữa mà khi có url thì ta vào url đó để lấy tiếp url của trang download nhé ta update lại các đoạn code như sau:
import scrapy
class SachVuiSpider(scrapy.Spider):
name = 'sachvui'
def start_requests(self):
urls = [
'https://sachvui.com/the-loai/tat-ca.html'
]
for url in urls:
yield scrapy.Request(url = url, callback=self.parsePage)
def parsePage(self, response):
for page in response.xpath("//div[contains(@class,'ebook')]/a"):
page_url = page.xpath('./@href').extract_first()
yield scrapy.Request(url = page_url, callback=self.parse)
nextButtonUrl = response.xpath("//a[@rel='next']/@href").extract_first()
if nextButtonUrl is not None:
yield scrapy.Request(url = nextButtonUrl, callback=self.parsePage)
def parse(self, response):
epubUrl = response.xpath("//a[@class='btn btn-primary']/@href").extract_first()
mobiUrl = response.xpath("//a[@class='btn btn-success']/@href").extract_first()
pdfUrl = response.xpath("//a[@class='btn btn-danger']/@href").extract_first()
yield {
'epub': epubUrl,
'mobi': mobiUrl,
'pdf': pdfUrl,
}
Clear dữ liệu trong file sachvui.json đi sau đó các bạn chạy lại lệnh
scrapy crawl sachvui -o sachvui.jsonsau đó các bạn có thể thấy được tất cả url download sẽ được lưu vào sachvui.json
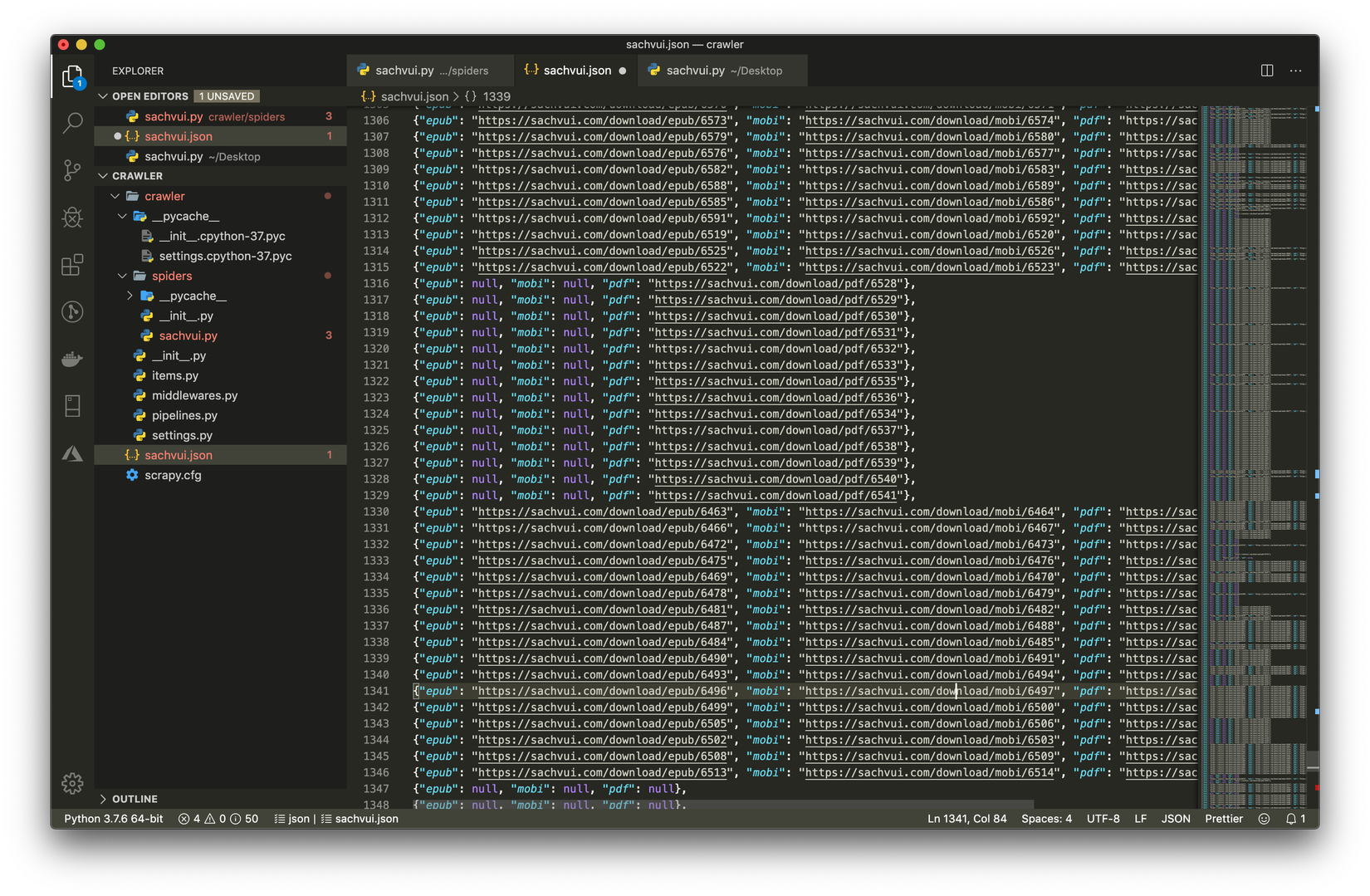
- Có url rồi viết thêm hàm download thôi, các bạn update lại code như bên dưới nhé
import scrapy
import os
class SachVuiSpider(scrapy.Spider):
name = 'sachvui'
def start_requests(self):
urls = [
'https://sachvui.com/the-loai/tat-ca.html'
]
for url in urls:
yield scrapy.Request(url = url, callback=self.parsePage)
def parsePage(self, response):
for page in response.xpath("//div[contains(@class,'ebook')]/a"):
page_url = page.xpath('./@href').extract_first()
yield scrapy.Request(url = page_url, callback=self.parse)
nextButtonUrl = response.xpath("//a[@rel='next']/@href").extract_first()
if nextButtonUrl is not None:
yield scrapy.Request(url = nextButtonUrl, callback=self.parsePage)
def parse(self, response):
epubUrl = response.xpath("//a[@class='btn btn-primary']/@href").extract_first()
mobiUrl = response.xpath("//a[@class='btn btn-success']/@href").extract_first()
pdfUrl = response.xpath("//a[@class='btn btn-danger']/@href").extract_first()
if mobiUrl is not None:
yield scrapy.Request(url = mobiUrl, callback=self.download)
def download(self, response):
path = response.url.split('/')[-1]
dirf = r"../sachvui/"
if not os.path.exists(dirf):os.makedirs(dirf)
os.chdir(dirf)
with open(path, 'wb') as f:
f.write(response.body)
Chạy
scrapy crawl sachvuivà đợi thành quả thôiỞ đoạn code trên mình chỉ muốn lấy file mobi thôi để dùng cho máy đọc sách thôi, các bạn muốn lấy các file còn lại thì thêm mã download thôi nha
Tất cả ebooks download về được lưu trong folder sachvui song song với thư mục crawler nhé
ở đoạn
dirf = r"../sachvui/"bạn có thể đổi vị trí thành nơi bạn muốn lưu ebooks nhéHMM, download về chung một folder rồi lười chia ra quá, các bạn tự dùng filter type trong folder để phân loại ra nha
Git repo: https://github.com/dpnthanh/EbooksCrawler.git
Đến đây là hết rồi, bài viết có hơi sơ sài cũng như kiến thức không đủ rộng và bài đầu tiên mà mình viết, mong có gì sai sót các bạn hãy đóng góp ý kiến giúp mình nhé, chân thành cảm ơn các bạn đã đọc đến đây
All rights reserved
