GET / POST và một số thứ cần biết
Bài đăng này đã không được cập nhật trong 3 năm
Bạn có thể là một web developer lâu năm hoặc mới vào nghề, nhưng tôi tin rằng bạn sẽ không cảm thấy hứng thú khi đọc đến RESTful API methods: GET và POST. Vì sao ư, đơn giản thì là vì nó đơn giản chỉ là GET và POST, làm gì còn gì nữa đúng không? Well, thì về cơ bản nó là như thế, nhưng liệu bạn còn bỏ lỡ điều gì nữa không? Cùng tổng hợp lại liệu xem bạn đã tường tận được sự khác nhau giữa GET và POST chưa nhé.
1. GET parameter sẽ được lưu trữ vào lịch sử trình duyệt
Trình duyệt sử dụng lịch sử duyệt của nó để điều hướng người dùng quay lại trang trước, hoặc chuyển tiếp sang trang tiếp theo, hậu quả là mọi URL được nhập vào sẽ được tự động chuyển đến lưu vào lịch sử trình duyệt. Nhưng điều gì sẽ xảy ra nếu một request GET được thực hiện thông qua một SPA (Single Page Aplication), thông qua AJAX, hoặc axios? Trong trường hợp này, URL request phải được đẩy vào lịch sử thủ công thông qua history.pushState và nó có thể được cập nhật trên địa chỉ URL của trình duyệt mà không chuyển hướng người dùng.
Xem xét 2 tình huống sau:
A. Truy cập https://www.kogan.com/au/shop/?q=laptop và click vào filter bất kì (ví dụ "Free shipping"). Trang web sẽ thực hiện GET request mới, lấy dữ liệu mới, hiển thị lại danh sách sản phẩm, cập nhật địa chỉ URL của trình duyệt và lưu URL vào lịch sử trình duyệt. Mặc dù trang web không được refresh, đường dẫn mới vẫn được đẩy vào lịch sử trình duyệt, do đó bạn vẫn có thể điều hướng trở lại trang đầu tiên.
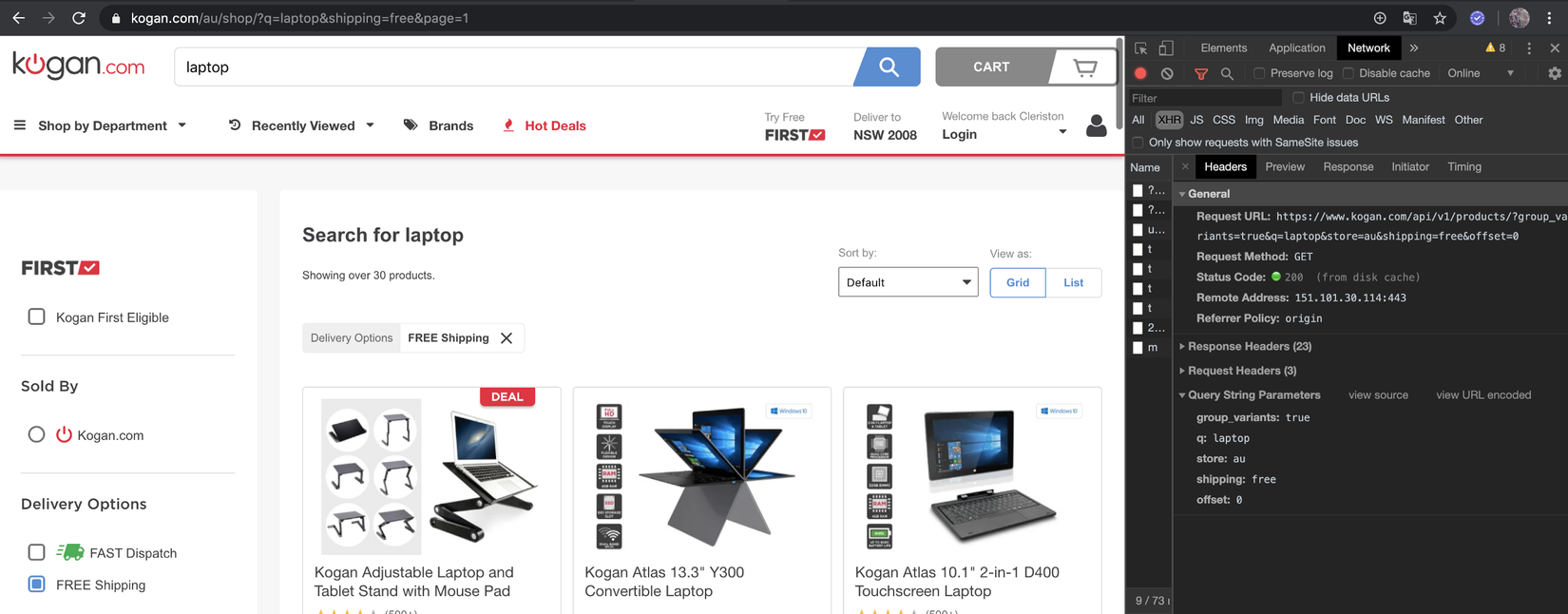
Chú ý rằng request mới được thực hiện mà không cần refresh trang, nút back trên trình duyệt giờ đã được enable và URL trình duyệt thậm chí còn khác với URL đầu tiên.
B. Giờ thử truy cập https://www.kogan.com/au/shop/?q=laptop nhưng thay vì click vào bất kì filter nào, hãy cuộn xuống cuối cùng và click vào "View More". Trang web sẽ thực hiện GET request mới, lấy dữ liệu mới, hiển thị lại danh sách sản phẩm và cập nhật địa chỉ URL của trình duyệt. Tuy nhiên nó không lưu URL vào trong lịch sử trình duyệt. Mặc dù trang không được refresh, vì URL không được đẩy và lịch sử trình duyệt, bạn sẽ không thể điều hướng trở lại trang ban đầu
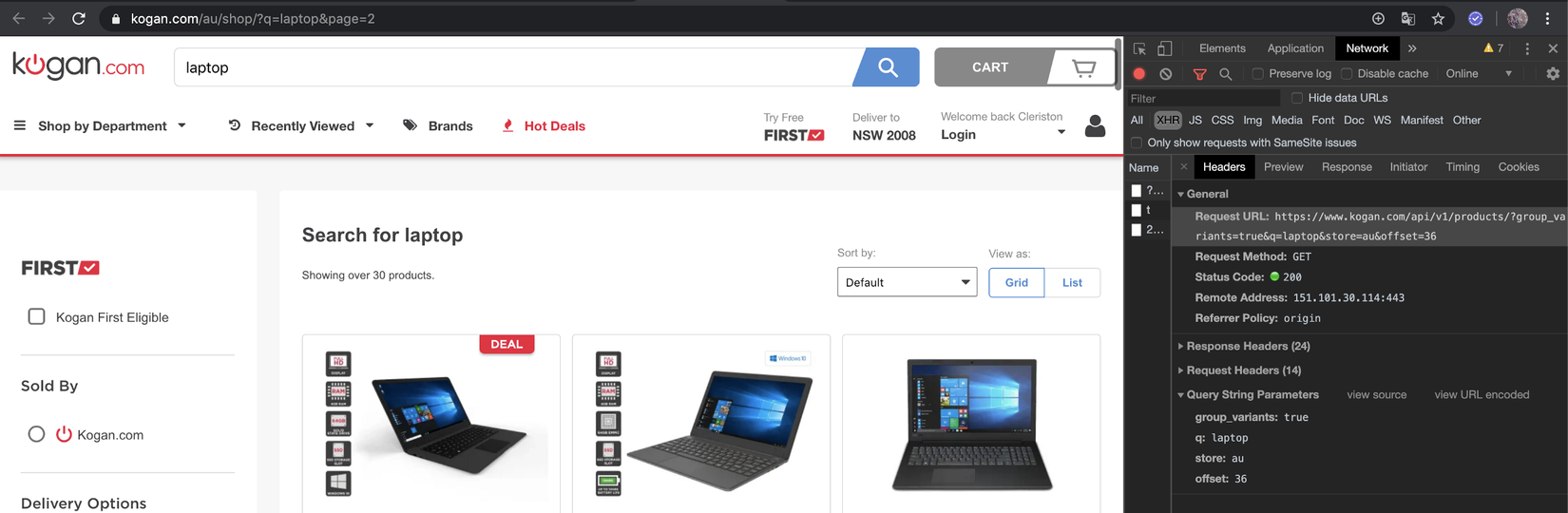
Chú ý rằng request mới được thực hiện mà không cần refresh trang, nút back trên trình duyệt vẫn disable và URL trình duyệt cũng khác với URL đầu tiên.
Đối với POST, nếu người dùng điều hướng trở lại sau khi submmit form, dữ liệu sẽ được submit lại (trình duyệt sẽ cảnh báo người dùng rằng dữ liệu sắp được submit lại), nhưng dữ liệu không được lưu vào lịch sử.
2. Response của GET có thể cache
Vì GET request là số lượng lớn và hầu hết tài nguyên trang web được trả về thông phương thức này, trình duyệt theo mặc định sẽ cache GET request. Vì vậy lần sau bạn truy cập trang web, thay vì truy cập vào server và gửi request lại lấy tất cả image, trình duyệt sẽ đơn giản là load nó từ cache của trình duyệt.
Lợi ích của điều này là trang web của bạn sẽ load nhanh hơn rất nhiều so với lần đầu load trang. Tuy nhiên các tài nguyên mới có thể sẽ không tiếp cận được client nếu họ đã cache lại tài nguyên cũ vào trình duyệt. Kết quả là để vô hiệu cache của client, developer thường dùng trick thay đổi tên của các file tài nguyên khi có sự thay đổi.
POST request không thể bị cache bên phía client
3. GET là phương thức an toàn
Bởi vì phương thức GET không bao giờ thay đổi tài nguyên nguồn, cho nên nó được coi là an toàn.
Phương thức an toàn là phương thức HTTP không sửa đổi tài nguyên nguồn.
Do đó nó có thể được lưu vào cache một cách an toàn, lưu vào lịch sử của trình duyệt và lưu trên các công cụ tìm kiếm, chẳng hạn như google. Điều này là bởi vì các parameter sẽ được lưu trữ trên URL và việc gọi lại phương thức GET sẽ không gây ra bất kì thay đổi nào với máy chủ.
Mặc khác, POST không phải một phương thức an toàn.
4. Các website tĩnh chỉ phản hồi GET request
Một trang web tĩnh là một ứng dụng tĩnh mà không cần bất kì công cụ nào khác để xử lý file của nó vì chúng sẽ trả về các nội dung mà trình duyệt có thể đọc được (JS, ảnh, CSS, HTML). Do đó nó chỉ cần phản hổi các GET request để trả về trang HTML. Vậy điều này có nghĩ gì?
Bạn có thể biết rằng bạn có thể tạo host cho một trang web tĩnh chỉ bằng cách sử dụng AWS S3. Tuy nhiên bạn có biết rằng nó chỉ cho phép các request GET và HEAD. Theo tài liệu của họ, tất cả các object request trên S3 bucket phải thông qua GET.
5. Phương thức nào có hạn chế về độ dài?
Điều quan trọng bạn cần hiểu là phương thức GET sẽ luôn được "dịch" sang dạng URL trên trình duyệt (giao thức http) và chỉ các kí tự ASCII mới được cho phép. Nói cách khác, bất kì văn bản nào bạn đặt trong URL của trình duyệt sẽ tạo ra GET request đến máy chủ, ngay cả khi GET request đó được thực hiện ngầm thông qua một số trang web, nó vẫn sẽ chuyển đổi nó thành định dạng URL với các tham số giống một querystring.
Bạn biết rằng GET request sẽ gửi các tham số thông qua URL, bạn nghĩ điều gì sẽ xảy ra nếu có quá nhiều parameter. Mặc dù con số này có thể hơi khác nhau giữa các trình duyệt, giới hạn độ dài URL an toàn thường là 2048 kí tự, trừ đi số kí tự trong phần đường dẫn thực tế. Do đó, nếu bạn đang xây dựng một trang web mà trang sản phẩm dùng nhiều bộ lọc trên URL, thì hãy cẩn thận với độ dài giới hạn của URL của GET request.
Đối với POST, vì payload được gửi thông qua body của request, về mặt kĩ thuật không có giới giạn dữ liệu được gửi, cũng như không có giới hạn về loại dữ liệu.
6. Phương thức nào an toàn hơn và nên sử dụng để xử lý dữ liệu nhạy cảm
Có rất nhiều người có thể trả lời điều này, nhưng họ thường không biết tại sao. Xem xét một endpoint đăng nhập với dữ liệu truyền đi là mật khẩu của người dùng, bạn đã bao giờ tự hỏi tại sao nó được sử dụng thông qua POST mà không phải là GET chưa? Đúng vậy, nó liên quan đến sự an toàn, nhưng không phải vì thông tin payload truyền đi của POST bị ẩn. Nó liên quan đến một trong những điểm đầu tiên mà chúng ta đã thảo luận ở đây: cache và lịch sử của trình duyệt.
Hãy tưởng tượng nếu bạn bắt đầu nhập vào thanh tìm kiếm tên một trang web trên trình duyệt của mình và nó tự động đề xuất một URL với người dùng và mật khẩu là một phần của chuỗi parameter. Nghe có vẻ lạ nhưng endpoint login GET có thể sẽ cho phép điều đó và tôi chắc chắn rằng đó không phải là điều bạn muốn.
Một điều nữa là URL phương thức GET có thể được log vào server. Cho dù là nginx, AWS... vì thông tin được đi qua một chuỗi truy vấn, thông tin nhạy cảm vẫn sẽ được log vào máy chủ như một đường dẫn thông thường. Và có lẽ là bạn sẽ không muốn nhìn thấy mật khẩu của khách hàng trong file log của bạn :-s
7. Phương thức nào có thể bookmark
POST không nên được đánh dấu trang (bookmark) và lý do của điều là là sự kết hợp của một số chủ đề đã thảo luận ở trên:
-
Việc cố gắng đánh dấu một POST request sẽ chỉ dẫn đến phương thức GET trên URL.
-
Phương thức này là không cố định nên không đảm bảo rằng response sẽ luôn giống nhau mọi lần. Ví dụ, nó có thể dẫn đến một giao dịch ngân hàng trùng lặp.
-
URL sẽ mất các tham số vì dấu trang không hỗ trợ lưu body payload của request
-
Nó có thể chứa dữ liệu nhạy cảm không nên được lưu trữ.
Tổng kết
Mặc dù GET rất thường được sử dụng để tìm nạp dữ liệu và POST để gửi / lưu dữ liệu, chúng ta có thể kết luận rằng có nhiều điều về hai phương pháp này và nhận thức được các đặc thù của chúng sẽ không chỉ giúp coding tốt hơn mà còn cả là về kiến trúc, thiết kế và giải quyết vấn đề. Hi vọng bài viết này có thể giúp bạn một chút trên con đường trở thành lập trình viên có tâm và có tầm của mình.
All rights reserved
