
Full text search trong Azure AI Search
Dữ liệu đang tăng lên với tốc độ chóng mặt, và việc tìm kiếm thông tin dữ liệu trở nên cần thiết và khó khăn hơn bao giờ hết. Với sự phát triển mạnh mẽ của LLM ở thời điểm hiện tại, Retrival Augmented Generation hứa hẹn một tương lai đầy triển vọng. Gần đây thì mình tiếp xúc với khá nhiều dự án về RAG và cũng được làm việc chủ yếu với Azure AI Search cho nhiệm vụ Retrival data.
Azure AI Search sẽ có 3 cách thức tìm kiếm documents liên quan:
- Full text search: tìm kiếm dự trên text
- Vector search: tìm kiếm dựa trên độ tương đồng của các embedded vector
- Hybrid search: kết hợp cả Full Text Search và Vector Search
Trong bài viết này, chúng ta sẽ cùng trao đổi kỹ hơn về Full text search để hiểu về cách hoạt động cũng như cách dùng của nó. Cùng bắt đầu thôi nào
What is full-text search?
Full-text search là một công nghệ quan trọng trong việc tìm kiếm thông tin trong các cơ sở dữ liệu hoặc tập tin văn bản. Khác biệt so với các phương pháp tìm kiếm truyền thống, nó không chỉ dựa vào việc tìm kiếm từ hoặc cụm từ cụ thể, mà còn khai thác toàn bộ nội dung của văn bản để đảm bảo tìm kiếm chính xác và toàn diện.
Khi thực hiện full-text search, hệ thống sẽ quét và phân tích toàn bộ nội dung của văn bản, bao gồm các phần như topic, phrasing, và citation. Điều này cho phép người dùng tìm kiếm theo nhiều tiêu chí khác nhau, từ các từ khóa cụ thể đến ý nghĩa chung của câu hoặc đoạn văn.
Ví dụ, nếu bạn tìm kiếm từ "machine learning", hệ thống full-text search có thể trả về kết quả không chỉ chứa cụm từ này mà còn những tài liệu có liên quan đến chủ đề hoặc phương pháp liên quan như "artificial intelligence", "data analysis", và "predictive modeling".
Một số loại full-text search điển hình
- Simple full-text search
- Boolean full-text search
- Fuzzy search
- Wildcard search
- Phrase search
- Proximity search
- Range search
- Faceted search
- …
Các bạn có thể đọc thêm tại đây
Kiến trúc tổng quan của full-text search trong Azure AI Search
Gồm 4 stages:
- Query parsing
- Lexical analysis
- Document retrieval
- Scoring
→ Tương ứng sẽ có 4 components chính
- Query parser: truy vấn được phân tách thành các thành phần riêng lẻ để xử lý và tìm kiếm tương ứng.
- Analyzers: có thể bao gồm biến đổi, loại bỏ hoặc mở rộng truy vấn. Mục đích là chuẩn hóa và chuẩn bị truy vấn để tìm kiếm hiệu quả.
- Index: Chỉ mục giúp tìm kiếm nhanh chóng và hiệu quả bằng cách xác định vị trí của các thuật ngữ trong các tài liệu.
- Search engine: truy xuất và đánh score cho các tài liệu liên quan
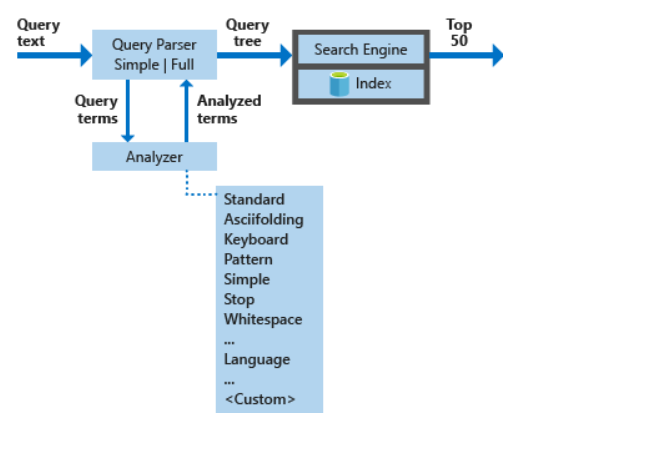
Stage 1: Query parsing
Có chức năng phân tách các toán tử trong search terms và phân tách truy vấn tìm kiếm thành các truy vấn con, với các kiểu hỗ trợ:
- Term query: sử dụng cho các thuật ngữ đứng một mình (ví dụ “search”: “nữ”), không có toán tử hoặc dấu ngoặc kép. Loại truy vấn này tìm kiếm các tài liệu chứa chính xác thuật ngữ đó
- Phrase query: sử dụng cho các thuật ngữ nằm trong dấu ngoặc kép (thường là 1 từ hoặc cụm từ, ví dụ “search”: “Cán bộ”). Truy vấn này sẽ tìm kiếm các tài liệu chứa chính xác cụm từ đó
- Prefix query: sử dụng cho các thuật ngữ được theo sau bởi toán tử tiền tố (“+”, “-”, “|”). Truy vấn này sẽ tìm kiếm tùy theo toán tử đưa vào.
Azure AI Search hỗ trợ 2 kiểu parsers:
- Simple query syntax
- Là một cú pháp dễ sử dụng và thường được sử dụng cho truy vấn cơ bản.
- Cú pháp này cho phép sử dụng các toán tử cơ bản như AND, OR, NOT, "+", "|" hay "-".
- Các bạn có thể đọc thêm tại đây
- Lucene query syntax
- Là một cú pháp mạnh mẽ hơn và linh hoạt hơn cho truy vấn tìm kiếm.
- Cú pháp này cho phép sử dụng các truy vấn phức tạp hơn bằng cách sử dụng các trường khác nhau, tùy chọn độ chính xác, truy vấn dựa trên vị trí, truy vấn theo khoảng cách, và nhiều hơn nữa.
- Các bạn có thể đọc thêm tại đây
Stage 2: Lexical analysis
- Giai đoạn phân tích từ vựng
- Một số thao tác thường được thực hiện
- Tokenization (phân tách thành các token)
- Case normalization (chuẩn hóa chữ hoa)
- Stemming (Đưa về dạng từ gốc, thường trong tiếng anh)
- Stop words removal (loại bỏ các từ không quan trọng như “a”, “an”, “the”, …)
- Tùy theo mỗi loại ngôn ngữ mà sẽ có các kiểu Analyzer khác nhau
- Một số Analyzers theo ngôn ngữ có thể đọc thêm tại đây
Stage 3: Document retrieval
Indexing là quá trình lập chỉ mục trong hệ thống search giúp xây dựng các chỉ mục ngược (inverted index) để lưu trữ và tìm kiếm dữ liệu hiệu quả.
- Với đánh chỉ mục thông thường (mỗi tài liệu có một định danh duy nhất và khi tìm kiếm phải duyệt qua tất cả)
- Với Inverted Index, dữ liệu được tổ chức theo từng thuật ngữ, mỗi thuật ngữ sẽ ánh xạ đến danh sách các tài liệu chứa thuật ngữ đó nên việc tìm kiếm sẽ hiệu quả hơn
Về Inverted Index, để hiểu rõ hơn, hãy xem xét một ví dụ đơn giản về cách hoạt động của inverted index. Giả sử chúng ta có ba tài liệu văn bản sau:
- Tài liệu 1: "Machine learning is fascinating."
- Tài liệu 2: "Machine learning algorithms are used in various applications."
- Tài liệu 3: "Deep learning is a subset of machine learning." Khi xây dựng inverted index cho các tài liệu này, chúng ta sẽ tạo ra một bảng, trong đó mỗi từ sẽ được liệt kê cùng với danh sách các tài liệu mà nó xuất hiện trong. Ví dụ:
- "machine": Tài liệu 1, Tài liệu 2, Tài liệu 3
- "learning": Tài liệu 1, Tài liệu 2, Tài liệu 3
- "is": Tài liệu 1, Tài liệu 3
- "fascinating": Tài liệu 1
- "algorithms": Tài liệu 2
- ... Khi người dùng tìm kiếm một từ cụ thể, hệ thống sẽ dựa vào inverted index để nhanh chóng xác định các tài liệu chứa từ đó và trả về kết quả. Điều này giúp tăng tốc độ và hiệu suất của quá trình tìm kiếm.
- Ví dụ về Inverted Index có thể đọc thêm tại đây
Quay lại với Stage Document Retrival, để tạo ra các thuật ngữ trong Inverted Index, Search Engine thực hiện phân tích từ vựng (Lexical Analysis) trên nội dung của documents:
- Document được chuyển đến bộ Analyzer, chuyển thành dữ liệu lower-cased, loại bỏ dấu câu và một vài bước khác tùy thuộc vào bộ Analyzer
- Các token là kết quả đầu ra của bộ phân tích từ vựng
- Các thuật ngữ được thêm vào chỉ mục
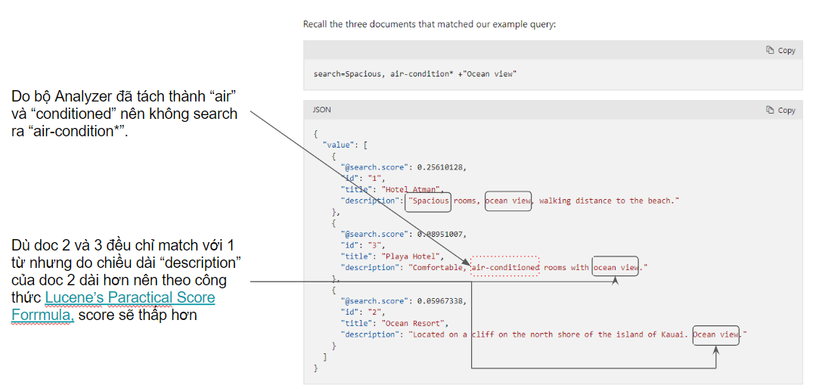
Ví dụ về quá trình thực thi truy vấn:
- Từ “spacious” khớp với tài liệu 1 vì có từ đó trong các từ được lập chỉ mục trong tài liệu 1
- Với Prefix query, cần tìm tài liệu khớp với cả cụm từ “air-condition” (chỉ chứa “air” hoặc “condition” là không thỏa mãn), rất có thể không có tài liệu nào liên quan mặc dù thực chất có, do bộ Analyzer đã nhầm lẫn tách từ này thành “air” và “condition”
- Với Phrase query “Ocean view” (dấu cách “ ” default là tìm kiếm các từ chứa cả “ocean” và “view”). Giả sử tài liệu 1, 2, 3 đều có, trong khi đó tài liệu 4 chỉ có “Ocean” là không khớp do không có chứa “view”
Stage4: Scoring
- Các documents trong kết quả tìm kiếm đều có kèm một relevance score để xếp hạng mức độ liên quan của documents tới input query
- Score này được tính dựa trên thuộc tính thống kê của các thuật ngữ matched
- Công thức để tính score dựa trên TF/IDF (term frequency-inverse document frequency)
- Các truy vấn sẽ chứa những terms hiếm và phổ biến
- TF/IDF sẽ ưu tiên kết quả dựa trên độ hiếm của thuật ngữ
- Ví dụ với các bài viết tìm kiếm được liên quan đến query “the president” (raw query, sau stage 2 thì giả sử output là “the” và “president”) thì các documents matching với “president” sẽ có độ liên quan cao hơn so với các documents matching với “the”
Ví dụ:
Bên cạnh đó, chúng ta cũng có thể điều chỉnh score theo mục đích của mình. Có 2 cách để điều chỉnh relevance scores trong Azure AI Search:
- Scoring profiles: Đưa vào 1 số quy tắc cho các field Searchable trong Index. Ví dụ đưa vào quy tắc xem xét độ khớp của query với các tài liệu trong field “Tags” là quan trọng hơn so với field “description”.
- Term boosting (Chỉ phù hợp với Full Lucene query syntax): Ví dụ, thay vì tìm kiếm theo tiền tố “air-condition*”, có thể tìm kiếm theo thuật ngữ chính xác “air-condition” hoặc tiền tố đó, nhưng các tài liệu khớp theo thuật ngữ chính xác sẽ được xếp hạng cao hơn bằng cách áp dụng tăng cường cho truy vấn thuật ngữ: “air-condition^2||air-condition*”.
References
All rights reserved
