
Biến ảnh của bạn thành các tác phẩm hội hoạ với Neural Style Transfer
Bài đăng này đã không được cập nhật trong 5 năm
PRISMA - Ứng dụng gây bão 1 thời
Khi đã chán Instagram và các bộ lọc hình ảnh quen thuộc, chúng ta bắt đầu tìm kiếm những thứ mới mẻ hơn. Đó là lúc mà những ứng dụng như Snapchat hay Snow bắt đầu trở thành trào lưu. Nhưng các ứng dụng này chỉ đáp ứng nhu cầu giải trí, khiến chúng ta cười trước khuôn mặt bị biến dạng thành thỏ hay mèo của bạn bè. Và ứng dụng Prisma ra đời để đáp ứng nhu cầu theo đuổi nghệ thuật của chúng ta trong thời đại số. Để có được những bức ảnh đẹp giống như tranh vẽ, đầy tính nghệ thuật giống như tác phẩm của một họa sĩ nổi tiếng...
Dòng mô tả đầy ngắn gọn trên được trích trong một bài phân tích vì sao ứng dụng PRISMA * (một ứng dụng giúp bạn chỉnh sửa các bức ảnh của mình bằng cách đưa vào chúng những hiệu ứng nghệ thuật) * lại trở thành trào lưu lan truyền rất nhanh trong giới trẻ.
Sự phát triển của công nghệ camera trên smartphone, cùng với những phần mềm chụp ảnh và chỉnh sửa ảnh, thêm bộ lọc hình ảnh đã giúp bất kỳ ai cũng có thể trở thành một nhiếp ảnh gia không chuyên. Chúng ta có thể chụp ảnh ở bất kỳ đâu, bất kỳ lúc nào, bất kỳ thứ gì và tự hào chia sẻ chúng trên mạng xã hội với một câu caption “ý nghĩa” nào đó.
Nghệ thuật là một thứ cảm nhận vô hình mà ai trong chúng ta cũng theo đuổi, giống như theo đuổi cái đẹp. Chính vì vậy mà mỗi khi đăng tải những bức ảnh trên mạng xã hội chúng ta luôn muốn mọi người khen đẹp, khen xuất sắc, khen từ màu sắc đến bối cảnh hay nhân vật chính trong bức ảnh. Và với PRISMA, chúng ta có thể dễ dàng có được những bức ảnh độc đáo của chính mình chụp.
Mục tiêu
Việc chuyển những bức ảnh của bạn thành những bức ảnh có phong cách nghệ thuật trên là một điều khiến mọi người đều cảm thấy vô cùng bất ngờ và thích thú, tuy nhiên với những người đã tìm hiểu về các mạng deep learning trong một thời gian, đây là một kỹ thuật khá quen thuộc và cơ bản của mạng Deep Learning có tên gọi Neural Style Transfer. Trong bài viết lần này, chúng ta hãy cùng nhau đi tìm hiểu và xây dựng lại mạng Neural Style Transfer để có thể tạo ra những bức ảnh cực kỳ nghệ đó giống với cách PRISMA đang làm nhé 
Neural Style Transfer là gì?
Định nghĩa
Phần mở đầu cũng như trong mục tiêu bài viết có lẽ cũng đã khiến cho các bạn có những hình dung cụ thể về ứng dụng và hiệu quả của mạng Neural Style Transfer. Vậy để định nghĩa một cách cụ thể hơn, chúng ta có thể tạm gọi bức ảnh của chúng ta là * ảnh nội dung (content image) - chứa thông tin nội dung chính*. Ngoài ra chúng ta cần định nghĩa 1 bức ảnh để đưa phong cách của bức ảnh này vào trong bức ảnh gốc, chúng ta gọi nó là ảnh phong cách (style image) - chứa phong cách, kết cấu.
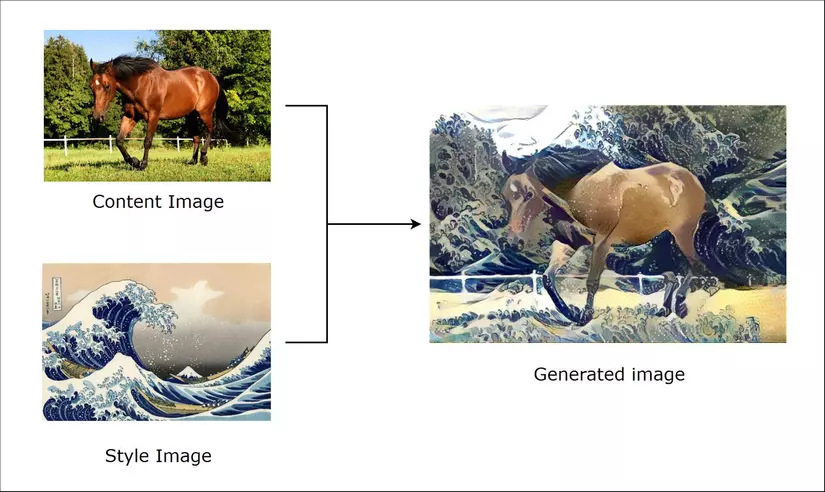
Và ảnh chúng ta tạo ra ảnh kết quả - sẽ là bức ảnh có nội dung đúng với ảnh nội dung nhưng lại đậm phong cách của ảnh phong cách
Ý tưởng chính
Chúng ta cũng sẽ sử dụng một mạng Convolution Neural Network (CNN) với mục đích phân tích ảnh và học các thuộc tính sâu (deep features) của ảnh, tuy nhiên khác với các bài toán khác, với Neural Style Transfer, chúng ta sẽ không cố gắng tối ưu mạng neural của chúng ta, thay vào đó, chúng ta sẽ cố gắng tối ưu trực tiếp đầu ra của mình (ảnh kết quả). Việc tối ưu của chúng ta sẽ dựa trên tối ưu tổng mất mát của:
- Sự khác nhau giữa Ảnh nội dung với Ảnh kết quả (Content Image vs Generated Image)
- Sự khác nhau Ảnh phong cách với Ảnh kết quả (Style Image vs Generated Image)
- Sự biến thiên của Ảnh kết quả (Variation of Generated Image)
Vậy nói cách khác, khi ảnh kết quả của chúng ta đạt được mất mát nhỏ nhất, điều này đồng nghĩa với việc nó chắc chắn sẽ giống với ảnh nội dung và ảnh phong cách. Tuỳ theo việc chúng ta khai báo hệ số cho các thành phần của hàm mất mát mà ảnh kết quả sẽ khác nhau.
Xây dựng mô hình Neural Style Transfer
Chúng ta sẽ sử dụng keras và tensorflow cho việc xây dựng bài toán này, ngoài ra mình sẽ sử dụng 1 vài hàm của thư viện scipy để giúp đơn giản hoá quá trình code.
Theo đề xuất của tác giả thì các bạn nên sử dụng mạng VGG19 với trọng số (pretrained weight) đã được huấn luyện trên tập imagenet để làm mạng phân tách thuộc tính.
Khai báo các thư viện cần dùng
from tensorflow.keras.applications import vgg19
from tensorflow.keras.preprocessing.image import load_img, save_img, img_to_array
from tensorflow.keras import backend as K
import numpy as np
from scipy.optimize import fmin_l_bfgs_b
import time
Khi sử dụng thư viện nào mình sẽ giải thích kỹ càng hơn nên các bạn đừng quá lo lắng nhé, tiếp tục thôi.
Khai báo các hằng số, tham số
img_nrows = 224
img_ncols = 224
base_image_path = ''
style_reference_image_path = ''
content_weight = 0.025
style_weight = 1
total_variation_weight = 1
iterations = 10
Ngoài việc thay đổi base_image_path (Đường dẫn tới ảnh nội dung - hay gọi là ảnh gốc) và style_reference_image_path (Đường dẫn tới ảnh phong cách), các bạn nên giữ nguyên các hằng số còn lại, mình sẽ giải thích cụ thể tác dụng của từng hằng số trong các phần sau.
Tiền xử lý ảnh trước khi đưa vào mô hình
def preprocess_image(image_path):
img = load_img(image_path, target_size=(img_nrows, img_ncols))
img = img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg19.preprocess_input(img)
return img
def deprocess_image(x):
x = x.reshape((resized_width, resized_height, 3))
# Remove zero-center by mean pixel. Necessary when working with VGG model
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# Format BGR->RGB
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
Ở đây chúng ta sẽ sử dụng hàm preprocess_input của mạng vgg19. Lý do sử dụng là bởi mỗi một mạng với các trọng số đã được huấn luyện, cách nhận đầu vào của chúng có sự khác nhau (với 1 số mạng nhận input là ảnh thông thường, 1 số mạng nhận input là ảnh đã được chuẩn hoá các pixel từ 0 đến 1, có mạng là từ -1 đến 1), vậy nên chúng ta đưa input qua hàm preprocess để chuẩn hoá input sao cho khớp với mô hình chúng ta sẽ sử dụng nhé
# get tensor representations of our images
base_image = K.variable(preprocess_image(base_image_path))
style_reference_image = K.variable(preprocess_image(style_reference_image_path))
combination_image = K.placeholder((1, img_nrows, img_ncols, 3))
input_tensor = K.concatenate([base_image,
style_reference_image,
combination_image], axis=0)
Input của chúng ta sẽ là 3 cả 3 ảnh bao gồm ảnh nội dung, ảnh phong cách và ảnh kết quả.
Lấy mô hình từ keras
model = vgg19.VGG19(input_tensor=input_tensor, weights='imagenet')
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers])
Trong bài này, hàm loss của chúng ta không tính đơn thuần dựa vào sự khác nhau giữa các ảnh ở lớp cuối cùng, chúng ta sẽ lấy ra kết quả ở các lớp giữa nhằm đa dạng hoá thành phần mất mát cũng như giúp ảnh kết quả được hình thành dựa trên nhiều mức độ sâu khác nhau của thuộc tính. Chúng ta khai báo 1 dictionary là *outputs_dict * để thuận tiện cho việc lấy đầu ra của các lớp giữa sau này. Các bạn có thể nhìn hình ảnh dưới đây để hình dung cách chúng ta trích các đầu ra ở các lớp giữa để tính tổng mất mát. (S - Style Image, G - Generated Image, C - Content Image).
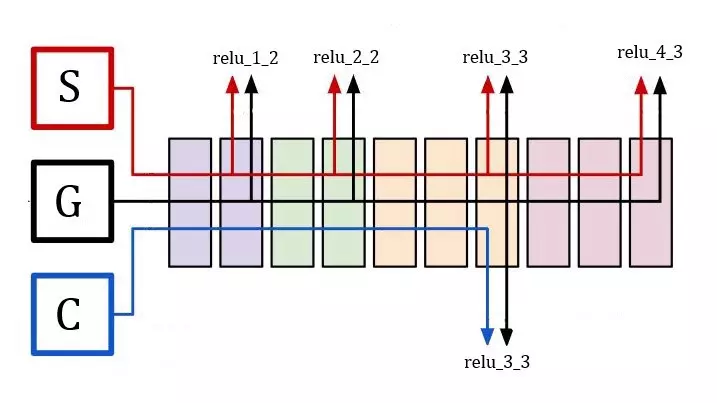
Có thể thấy rõ ảnh chúng ta sẽ cố gắng tối ưu để đáp ứng được việc sai khác nhỏ giữa nhiều lớp, nhiều độ sâu khác nhau của Style Image nên ảnh sẽ mang phong cách đặc trưng của ảnh này, với ảnh Content, chúng ta sẽ chỉ so khớp hàm mất mát dựa trên lớp đặc trưng gần cuối nên ảnh tạo ra sẽ chỉ lấy "nội dung" của nó.
Các hàm mất mát
 Ngoài ra chúng ta sẽ sử dụng thêm mất mát theo sự biến thiên của ảnh kết quả nhằm làm mượt ảnh (Như mình đã nói trong phần ý tưởng chính)
Ngoài ra chúng ta sẽ sử dụng thêm mất mát theo sự biến thiên của ảnh kết quả nhằm làm mượt ảnh (Như mình đã nói trong phần ý tưởng chính)
Sự khác nhau giữa Ảnh nội dung với Ảnh kết quả (Content Loss)
def content_loss(base, combination):
return K.sum(K.square(combination - base))
Hàm loss tính theo L2 norm, 1 công thức rất quen thuộc phải không
Sự khác nhau Ảnh phong cách với Ảnh kết quả (Style Loss)
def gram_matrix(x):
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1))) #channel first
gram = K.dot(features, K.transpose(features))
return gram
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = img_nrows * img_ncols
return K.sum(K.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
Với ảnh style, không như ảnh loss chúng ta sẽ chỉ tính mất mát dựa trên sự khác nhau về mặt "kết cấu". Hiểu một cách đơn giản nhất, thay vì so sánh 2 ảnh với nhau, chúng ta sẽ so sánh gram matrix của chúng. Gram matrix là một ma trận sẽ chứa đặc trưng của ảnh, tức là chúng ta đi so sánh và tối ưu về mặt đặc trưng thay vì về mặt hình ảnh.
Sự biến thiên của Ảnh kết quả (Variation Loss)
Đây là một phần không bắt buộc, tuy nhiên việc dùng thêm hàm loss này trong các thành phần của hàm mất mát khiến cho ảnh kết quả chúng ta sẽ "mượt hơn" - đảm bảo được sự biến thiên hài hoà giữa màu sắc nhất có thể.
def total_variation_loss(x):
a = K.square(
x[:, :img_nrows - 1, :img_ncols - 1, :] - x[:, 1:, :img_ncols - 1, :]) #x_dimension
b = K.square(
x[:, :img_nrows - 1, :img_ncols - 1, :] - x[:, :img_nrows - 1, 1:, :]) #y_dimension
return K.sum(K.pow(a + b, 1.25))
Hàm mất mát tổng
loss = K.variable(0.0)
# contribution of content_loss
feature_layers_content = outputs_dict['block5_conv2']
loss += content_weight * content_loss(feature_layers_content)
# contribution of style_loss
feature_layers_style = ['block1_conv1', 'block2_conv1',
'block3_conv1', 'block4_conv1',
'block5_conv1']
loss += total_style_loss(feature_layers_style) * style_weight
# contribution of variation_loss
loss += total_variation_weight * total_variation_loss(combination_image)
Ở đây chúng ta sẽ tính toán tổng loss dựa trên các trọng số của các thành phần mà chúng ta đã khai báo ở đầu bài thay vì tổng đơn thuần. Điều này làm chúng ta dễ dàng tuỳ chỉnh mức độ "giống" của ảnh kết quả về mặt "nội dung" lẫn "phong cách"
Khai báo Gradients, Optimizer của Output
# Get the gradients of the generated image
grads = K.gradients(loss, combination_image)
outputs = [loss]
outputs += grads
f_outputs = K.function([combination_image], outputs)
# Evaluate the loss and the gradients respect to the generated image. It is called in the Evaluator, necessary to
# compute the gradients and the loss as two different functions (limitation of the L-BFGS algorithm) without
# excessive losses in performance
def eval_loss_and_grads(x):
x = x.reshape((1, resized_width, resized_height, 3))
outs = f_outputs([x])
loss_value = outs[0]
if len(outs[1:]) == 1:
grad_values = outs[1].flatten().astype('float64')
else:
grad_values = np.array(outs[1:]).flatten().astype('float64')
return loss_value, grad_values
# Evaluator returns the loss and the gradient in two separate functions, but the calculation of the two variables
# are dependent. This reduces the computation time, since otherwise it would be calculated separately.
class Evaluator(object):
def __init__(self):
self.loss_value = None
self.grads_values = None
def loss(self, x):
assert self.loss_value is None
loss_value, grad_values = eval_loss_and_grads(x)
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
evaluator = Evaluator()
Chúng ta sẽ sử dụng optimizer là thuật toán L-BFGS với fmin_l_bfgs_b của thư viện scipy. Các bước xử lý sẽ hơi rườm rà bởi thuật toán L-BFGS yêu cầu chúng ta đưa gradient và loss vào 1 cách tách biệt nhau.
Chạy mô hình
Giờ là lúc chúng ta cài đặt nốt những dòng code cuối cùng để chạy được ứng dụng hay ho này  )
)
x = preprocess_image(base_image_path)
for i in range(iterations):
print('Start of iteration', i)
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.flatten(),
fprime=evaluator.grads, maxfun=20)
print('Current loss value:', min_val)
# save current generated image
img = deprocess_image(x.copy())
fname = 'res_at_iteration_%d.png' % i
save_img(fname, img)
end_time = time.time()
print('Image saved as', fname)
print('Iteration %d completed in %ds' % (i, end_time - start_time))
Sau mỗi vòng lặp, chúng ta lưu lại ảnh kết quả để theo dõi.
Kết quả thu được
Các Styles mình kiếm được trên mạng để sử dụng trong bài lần này
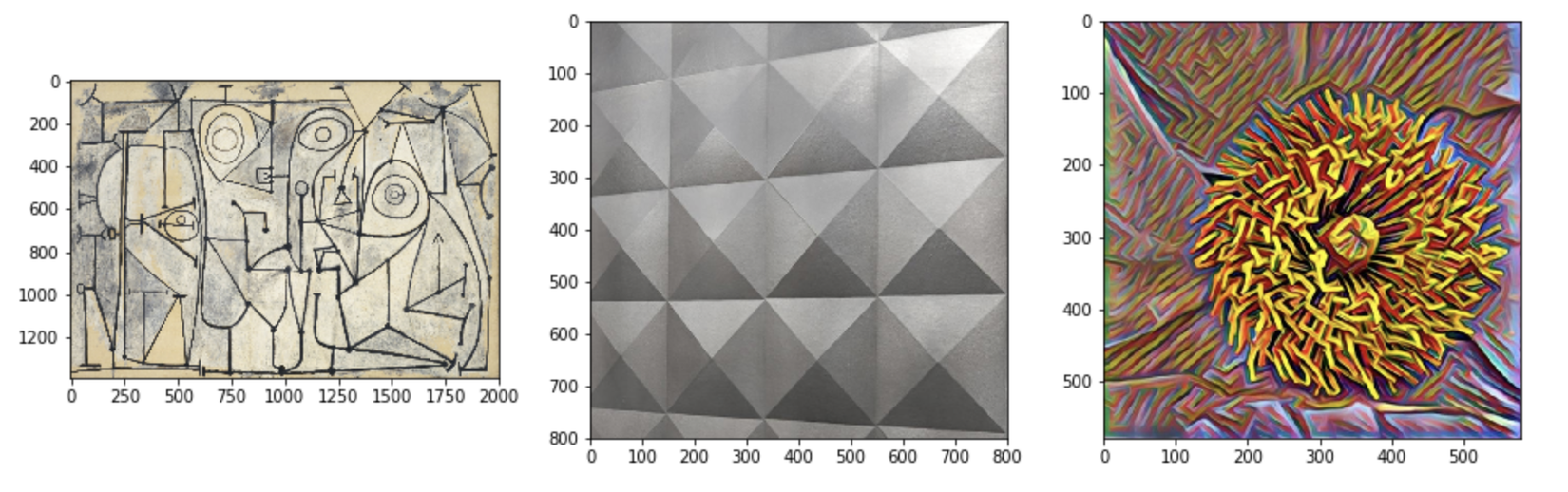
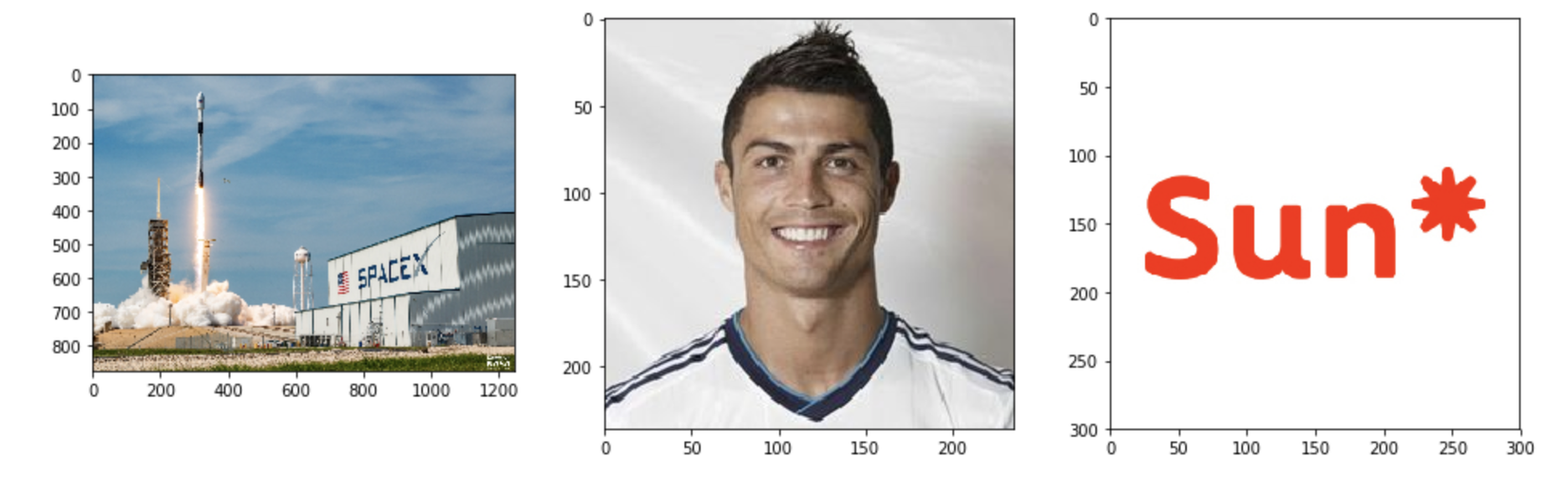
3 ảnh gốc mà chúng ta dùng để thử nghiệm
Hãy nhìn qua tất cả kết quả tổng quan

Kết quả chi tiết qua từng vòng lặp của ảnh thứ 1 và style thứ 1
 Có thể dễ nhận thấy rằng, càng lặp nhiều, bức ảnh gốc càng mang nhiều màu của bức ảnh phong cách hơn. Tuỳ vào mức độ mong muốn, chúng ta có thể chọn số vòng lặp thích hợp
Có thể dễ nhận thấy rằng, càng lặp nhiều, bức ảnh gốc càng mang nhiều màu của bức ảnh phong cách hơn. Tuỳ vào mức độ mong muốn, chúng ta có thể chọn số vòng lặp thích hợp
Kết luận
Mình có đẩy code lên github nhằm giúp các bạn dễ dàng hơn trong việc theo dõi: https://github.com/hoanganhpham1006/neural_style_transfer
Để tối ưu được hơn nữa mô hình của chúng ta, chúng ta sẽ cần điều chỉnh các trọng số dựa trên sự nghiên cứu kỹ lưỡng phân bố của ảnh nội dung với ảnh phong cách (trọng số này có thể khác nhau nhiều đối với từng loại ảnh). Việc chọn ảnh phong cách (Style Image) cũng là một việc khó khăn, nan giải bởi lẽ không phải phong cách nào cũng phù hợp với ảnh gốc của chúng ta phải không ) Mình xin phép dừng bài viết ở đây. Nếu có khúc mắc gì khi làm theo, các bạn có thể comment trực tiếp tại đây để mình giải đáp. Hãy thử tự sáng tác một tác phẩm nghệ thuật theo phong cách Picasso xem thế nào. Chúc các bạn thành công!!
P/s: Dạo gần đây mình nhận được nhiều câu hỏi qua email, facebook cá nhân cũng như comment trực tiếp nhưng do đang khá bận rộn với các kế hoạch nên việc trả lời của mình sẽ không được nhanh chóng. Mong các bạn thông cảm, mình chắc chắn sẽ trả lời hết các bạn  . Rất cảm ơn sự ủng hộ của các bạn.
. Rất cảm ơn sự ủng hộ của các bạn.
All rights reserved
